يعد الفرز أحد الأنواع الأساسية للأنشطة أو الإجراءات التي يتم تنفيذها على الكائنات. حتى في مرحلة الطفولة، يتم تعليم الأطفال الفرز وتطوير تفكيرهم. أجهزة الكمبيوتر والبرامج أيضا ليست استثناء. هناك مجموعة كبيرة ومتنوعة من الخوارزميات. أقترح عليك أن تنظر إلى ما هي وكيف تعمل. بالإضافة إلى ذلك، ماذا لو سُئلت يومًا ما عن أحد هذه الأمور في إحدى المقابلات؟
مقدمة
يعد فرز العناصر إحدى فئات الخوارزميات التي يجب على المطور التعود عليها. إذا كان ياما كان، عندما كنت أدرس، لم يتم أخذ علوم الكمبيوتر على محمل الجد، الآن في المدرسة يجب أن يكونوا قادرين على تنفيذ خوارزميات الفرز وفهمها. يتم تنفيذ الخوارزميات الأساسية، أبسطها، باستخدام حلقة for. بطبيعة الحال، من أجل فرز مجموعة من العناصر، على سبيل المثال، مجموعة، تحتاج إلى اجتياز هذه المجموعة بطريقة أو بأخرى. على سبيل المثال:
int[] array ={10,2,10,3,1,2,5};for(int i =0; i < array.length; i++){System.out.println(array[i]);}
ماذا يمكنك أن تقول عن هذا الجزء من التعليمات البرمجية؟ لدينا حلقة نقوم فيها بتغيير قيمة الفهرس ( int i) من 0 إلى العنصر الأخير في المصفوفة. في الأساس، نحن ببساطة نأخذ كل عنصر في المصفوفة ونطبع محتوياته. كلما زاد عدد العناصر في المصفوفة، كلما استغرق تنفيذ التعليمات البرمجية وقتًا أطول. أي أنه إذا كان n هو عدد العناصر، فمع n=10 سيستغرق تنفيذ البرنامج وقتًا أطول مرتين مقارنة بـ n=5. عندما يحتوي برنامجنا على حلقة واحدة، يزداد وقت التنفيذ خطيًا: كلما زاد عدد العناصر، زاد وقت التنفيذ. اتضح أن خوارزمية الكود أعلاه تعمل في الزمن الخطي (n). في مثل هذه الحالات، يُقال إن "تعقيد الخوارزمية" هو O(n). يُطلق على هذا الترميز أيضًا اسم "big O" أو "السلوك المقارب". ولكن يمكنك ببساطة أن تتذكر "تعقيد الخوارزمية".
أبسط الفرز (الفرز الفقاعي)
لذا، لدينا مصفوفة ويمكننا التكرار عليها. عظيم. دعونا الآن نحاول فرزها بترتيب تصاعدي. ماذا يعني هذا بالنسبة لنا؟ هذا يعني أنه بالنظر إلى عنصرين (على سبيل المثال، أ=6، ب=5)، يجب علينا تبديل a وb إذا كان a أكبر من b (إذا كان a > b). ماذا يعني هذا بالنسبة لنا عند العمل مع مجموعة حسب الفهرس (كما هو الحال مع المصفوفة)؟ هذا يعني أنه إذا كان العنصر ذو الفهرس a أكبر من العنصر ذو الفهرس b، (array[a]> array[b])، فيجب تبديل هذه العناصر. غالبًا ما يُطلق على تغيير الأماكن اسم المبادلة. هناك طرق مختلفة لتغيير الأماكن. لكننا نستخدم كودًا بسيطًا وواضحًا وسهل التذكر:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);}}System.out.println(Arrays.toString(array));
وكما نرى، فإن العناصر قد تغيرت أماكنها بالفعل. لقد بدأنا بعنصر واحد، لأنه... إذا كانت المصفوفة تتكون من عنصر واحد فقط، فإن التعبير 1 < 1 لن يعود صحيحًا وبالتالي سنحمي أنفسنا من حالات المصفوفة التي تحتوي على عنصر واحد أو بدونها على الإطلاق، وسيبدو الكود أفضل. لكن مجموعتنا النهائية لم يتم فرزها على أي حال، لأن... لا يمكن فرز الجميع في مسار واحد. سيتعين علينا إضافة حلقة أخرى سنجري فيها تمريرات واحدًا تلو الآخر حتى نحصل على مصفوفة مرتبة:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));boolean needIteration =true;while(needIteration){
needIteration =false;for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);
needIteration =true;}}}System.out.println(Arrays.toString(array));
لذلك نجح فرزنا الأول. نقوم بالتكرار في الحلقة الخارجية ( while) حتى نقرر أنه ليست هناك حاجة لمزيد من التكرارات. افتراضيًا، قبل كل تكرار جديد، نفترض أن المصفوفة الخاصة بنا مرتبة، ولا نريد التكرار بعد الآن. ولذلك، فإننا نستعرض العناصر بالتسلسل ونتحقق من هذا الافتراض. لكن إذا كانت العناصر غير مرتبة، نقوم بتبديل العناصر وندرك أننا لسنا متأكدين من أن العناصر الآن في الترتيب الصحيح. لذلك، نريد إجراء تكرار آخر. على سبيل المثال، [3، 5، 2]. 5 أكثر من ثلاثة، كل شيء على ما يرام. لكن 2 أقل من 5. ومع ذلك، [3، 2، 5] يتطلب تمريرة واحدة إضافية، لأن 3> 2 ويجب تبديلهما. نظرًا لأننا نستخدم حلقة داخل حلقة، فقد اتضح أن تعقيد الخوارزمية لدينا يزداد. مع عناصر n يصبح n * n، أي O(n^2). ويسمى هذا التعقيد التربيعي. وكما نفهم، لا يمكننا أن نعرف بالضبط عدد التكرارات المطلوبة. يخدم مؤشر تعقيد الخوارزمية غرض إظهار الاتجاه نحو التعقيد المتزايد، في أسوأ الحالات. ما مقدار زيادة وقت التشغيل عندما يتغير عدد العناصر n. يعد فرز الفقاعات أحد أبسط الأنواع وأقلها كفاءة. ويطلق عليه أيضًا أحيانًا "الفرز الغبي". المواد ذات الصلة:
نوع آخر هو فرز الاختيار. كما أن لديها تعقيدًا من الدرجة الثانية، ولكن المزيد عن ذلك لاحقًا. لذا فإن الفكرة بسيطة. كل تمريرة تختار أصغر عنصر وتنقله إلى البداية. في هذه الحالة، ابدأ كل تمريرة جديدة بالانتقال إلى اليمين، أي التمريرة الأولى - من العنصر الأول، والتمريرة الثانية - من العنصر الثاني. سوف يبدو مثل هذا:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){int minInd = left;for(int i = left; i < array.length; i++){if(array[i]< array[minInd]){
minInd = i;}}swap(array, left, minInd);}System.out.println(Arrays.toString(array));
هذا الفرز غير مستقر، لأن يمكن للعناصر المتطابقة (من وجهة نظر الخاصية التي نفرز بها العناصر) أن تغير موضعها. يوجد مثال جيد في مقالة ويكيبيديا: Sorting_by-selection . المواد ذات الصلة:
يتميز فرز الإدراج أيضًا بتعقيد تربيعي، نظرًا لأنه لدينا مرة أخرى حلقة داخل حلقة. كيف يختلف عن فرز الاختيار؟ هذا الترتيب "مستقر". وهذا يعني أن العناصر المتطابقة لن تغير ترتيبها. متطابقة من حيث الخصائص التي نفرز بها.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){// Retrieve the value of the elementint value = array[left];// Move through the elements that are before the pulled elementint i = left -1;for(; i >=0; i--){// If a smaller value is pulled out, move the larger element furtherif(value < array[i]){
array[i +1]= array[i];}else{// If the pulled element is larger, stopbreak;}}// Insert the extracted value into the freed space
array[i +1]= value;}System.out.println(Arrays.toString(array));
من بين الأنواع البسيطة هناك نوع آخر - الفرز المكوكي. لكنني أفضل مجموعة المكوك المتنوعة. يبدو لي أننا نادرًا ما نتحدث عن المكوكات الفضائية، والمكوك هو أكثر من مجرد رحلة. لذلك، من الأسهل تخيل كيفية إطلاق المكوكات إلى الفضاء. وهنا ارتباط مع هذه الخوارزمية. ما هو جوهر الخوارزمية؟ جوهر الخوارزمية هو أننا نكرر من اليسار إلى اليمين، وعند تبديل العناصر، نتحقق من جميع العناصر الأخرى المتبقية لمعرفة ما إذا كانت عملية المبادلة بحاجة إلى التكرار.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i -1);for(int z = i -1;(z -1)>=0; z--){if(array[z]< array[z -1]){swap(array, z, z -1);}else{break;}}}}System.out.println(Arrays.toString(array));
نوع بسيط آخر هو نوع شل. جوهرها مشابه لفرز الفقاعات، ولكن في كل تكرار لدينا فجوة مختلفة بين العناصر المقارنة. كل تكرار يتم تخفيضه إلى النصف. هنا مثال على التنفيذ:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));// Calculate the gap between the checked elementsint gap = array.length /2;// As long as there is a difference between the elementswhile(gap >=1){for(int right =0; right < array.length; right++){// Shift the right pointer until we can find one that// there won't be enough space between it and the element before itfor(int c = right - gap; c >=0; c -= gap){if(array[c]> array[c + gap]){swap(array, c, c + gap);}}}// Recalculate the gap
gap = gap /2;}System.out.println(Arrays.toString(array));
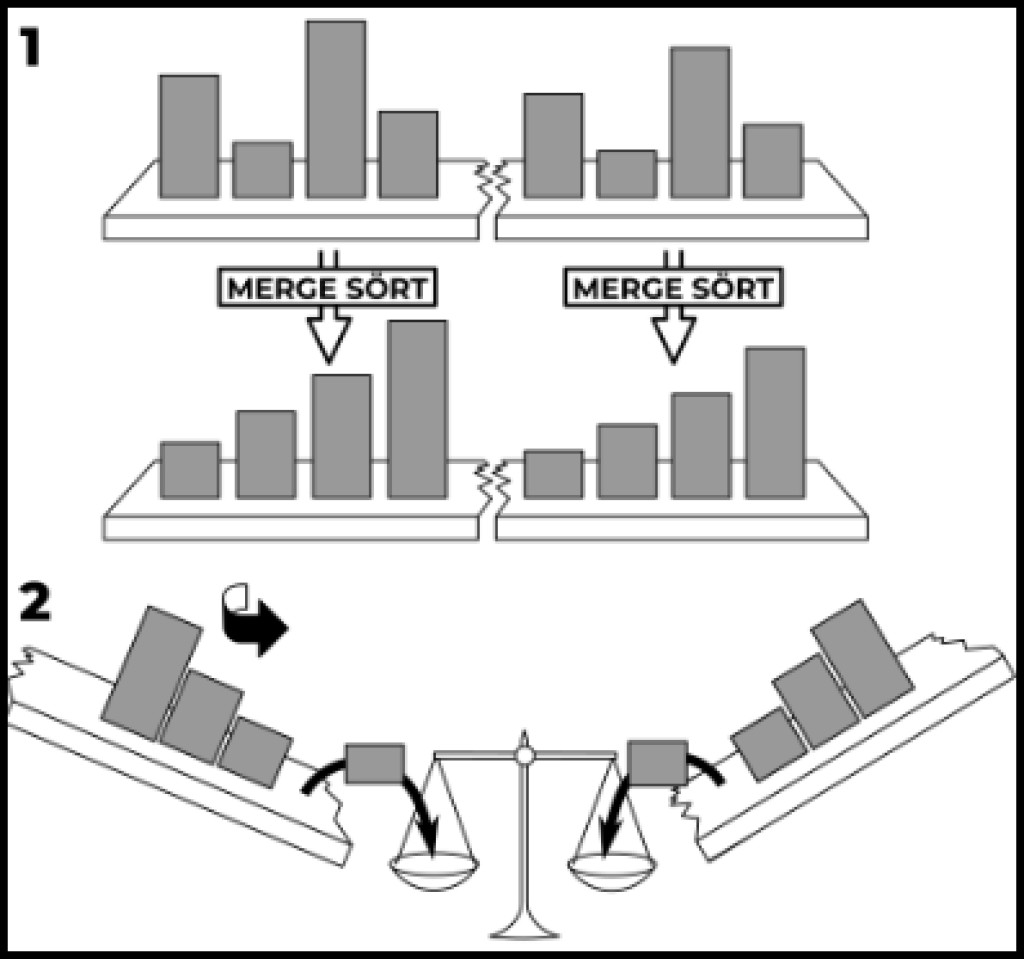
بالإضافة إلى الأنواع البسيطة المشار إليها، هناك أنواع أكثر تعقيدًا. على سبيل المثال، دمج الفرز. أولا، سوف يأتي العودية لمساعدتنا. ثانياً، لن يكون تعقيدنا تربيعياً بعد الآن، كما اعتدنا عليه. تعقيد هذه الخوارزمية لوغاريتمي. مكتوب كـ O(n log n). لذلك دعونا نفعل هذا. أولاً، لنكتب استدعاءً عوديًا لطريقة الفرز:
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}}
الآن، دعونا نضيف الإجراء الرئيسي إليها. فيما يلي مثال على طريقتنا الفائقة مع التنفيذ:
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}// Create a temporary array with the desired sizeint[] buffer =newint[right - left +1];// Starting from the specified left border, go through each elementint cursor = left;for(int i =0; i < buffer.length; i++){// We use the delimeter to point to the element from the right side// If delimeter > right, then there are no unadded elements left on the right sideif(delimiter > right || source[cursor]> source[delimiter]){
buffer[i]= source[cursor];
cursor++;}else{
buffer[i]= source[delimiter];
delimiter++;}}System.arraycopy(buffer,0, source, left, buffer.length);}
لنقم بتشغيل المثال عن طريق استدعاء mergeSort(array, 0, array.length-1). كما ترون، فإن الجوهر يتلخص في حقيقة أننا نأخذ كمدخل مصفوفة تشير إلى بداية ونهاية القسم المراد فرزه. عندما يبدأ الفرز، هذه هي بداية المصفوفة ونهايتها. بعد ذلك نحسب المحدد - موضع الفاصل. إذا كان المقسم يمكن أن ينقسم إلى جزأين، فإننا نسمي الفرز العودي للأقسام التي قسم المقسم المصفوفة إليها. نقوم بإعداد مصفوفة عازلة إضافية نختار فيها القسم الذي تم فرزه. بعد ذلك، نضع المؤشر في بداية المنطقة المراد فرزها ونبدأ بالمرور على كل عنصر من عناصر المصفوفة الفارغة التي أعددناها ونملأها بأصغر العناصر. إذا كان العنصر الذي يشير إليه المؤشر أصغر من العنصر الذي يشير إليه المقسوم عليه، فإننا نضع هذا العنصر في المصفوفة المؤقتة ونحرك المؤشر. بخلاف ذلك، فإننا نضع العنصر المشار إليه بواسطة الفاصل في مصفوفة المخزن المؤقت ونحرك الفاصل. بمجرد أن يتجاوز الفاصل حدود المنطقة التي تم فرزها أو نملأ المصفوفة بأكملها، يعتبر النطاق المحدد مصنفا. المواد ذات الصلة:
خوارزمية فرز أخرى مثيرة للاهتمام هي فرز العد. التعقيد الخوارزمي في هذه الحالة سيكون O(n+k)، حيث n هو عدد العناصر، وk هي القيمة القصوى للعنصر. هناك مشكلة واحدة في الخوارزمية: نحتاج إلى معرفة الحد الأدنى والحد الأقصى للقيم في المصفوفة. فيما يلي مثال على تنفيذ فرز العد:
publicstaticint[]countingSort(int[] theArray,int maxValue){// Array with "counters" ranging from 0 to the maximum valueint numCounts[]=newint[maxValue +1];// In the corresponding cell (index = value) we increase the counterfor(int num : theArray){
numCounts[num]++;}// Prepare array for sorted resultint[] sortedArray =newint[theArray.length];int currentSortedIndex =0;// go through the array with "counters"for(int n =0; n < numCounts.length; n++){int count = numCounts[n];// go by the number of valuesfor(int k =0; k < count; k++){
sortedArray[currentSortedIndex]= n;
currentSortedIndex++;}}return sortedArray;}
كما نفهم، فمن غير المناسب للغاية أن نضطر إلى معرفة الحد الأدنى والحد الأقصى للقيم مقدمًا. ثم هناك خوارزمية أخرى - الترتيب الجذري. سأقدم الخوارزمية هنا بشكل مرئي فقط. للتنفيذ، انظر المواد:
حسنًا، بالنسبة للحلوى - إحدى الخوارزميات الأكثر شهرة: الفرز السريع. لديها تعقيد خوارزمي، أي أن لدينا O(n log n). يُسمى هذا النوع أيضًا بفرز Hoare. ومن المثير للاهتمام أن الخوارزمية اخترعها هور أثناء إقامته في الاتحاد السوفيتي، حيث درس الترجمة الحاسوبية في جامعة موسكو وكان يطور كتاب تفسير العبارات الشائعة باللغتين الروسية والإنجليزية. يتم استخدام هذه الخوارزمية أيضًا في تطبيق أكثر تعقيدًا في Arrays.sort في Java. ماذا عن Collections.sort؟ أقترح عليك أن ترى بنفسك كيف يتم فرزها "تحت الغطاء". إذن الكود:
publicstaticvoidquickSort(int[] source,int leftBorder,int rightBorder){int leftMarker = leftBorder;int rightMarker = rightBorder;int pivot = source[(leftMarker + rightMarker)/2];do{// Move the left marker from left to right while element is less than pivotwhile(source[leftMarker]< pivot){
leftMarker++;}// Move the right marker until element is greater than pivotwhile(source[rightMarker]> pivot){
rightMarker--;}// Check if you don't need to swap elements pointed to by markersif(leftMarker <= rightMarker){// The left marker will only be less than the right marker if we have to swapif(leftMarker < rightMarker){int tmp = source[leftMarker];
source[leftMarker]= source[rightMarker];
source[rightMarker]= tmp;}// Move markers to get new borders
leftMarker++;
rightMarker--;}}while(leftMarker <= rightMarker);// Execute recursively for partsif(leftMarker < rightBorder){quickSort(source, leftMarker, rightBorder);}if(leftBorder < rightMarker){quickSort(source, leftBorder, rightMarker);}}
كل شيء هنا مخيف جدًا، لذا سنكتشف ذلك. بالنسبة لمصدر صفيف الإدخال int[]، قمنا بتعيين علامتين، اليسار (L) واليمين (R). عند استدعائها لأول مرة، فإنها تطابق بداية ونهاية المصفوفة. بعد ذلك، يتم تحديد العنصر الداعم، المعروف أيضًا باسم pivot. بعد ذلك، مهمتنا هي نقل القيم الأقل من pivot، إلى اليسار pivot، والقيم الأكبر إلى اليمين. للقيام بذلك، قم أولاً بتحريك المؤشر Lحتى نجد قيمة أكبر من pivot. إذا لم يتم العثور على قيمة أصغر، ثم
L совпадёт с
pivot. Потом двигаем указатель
R пока не найдём меньшее, чем
pivot meaning. Если меньшее meaning не нашли, то
R совпадёт с
pivot. Далее, если указатель
L находится до указателя
R or совпадает с ним, то пытаемся выполнить обмен элементов, если элемент
L меньше, чем
R. Далее
L сдвигаем вправо на 1 позицию,
R сдвигаем влево на одну позицию. Когда левый маркер
L окажется за правым маркером
R это будет означать, что обмен закончен, слева от
pivot меньшие значения, справа от
pivot — большие значения. После этого рекурсивно вызываем такую же сортировку для участков массива от начала сортируемого участка до правого маркера и от левого маркера до конца сортируемого участка. Почему от начала до правого? Потому что в конце итерации так и получится, что правый маркер сдвинется настолько, что станет границей части слева. Этот алгоритм более сложный, чем простая sorting, поэтому его лучше зарисовать. Возьмём белый лист бумаги, запишем: 4 2 6 7 3 , а
Pivot по центру, т.е. число 6. Обведём его в круг. Под 4 напишем
L, под 3 напишем
R. 4 меньше чем 6, 2 меньше чем 6. Total,
L переместился на положение
pivot, т.к. по условию
L не может уйти дальше, чем
pivot. Напишем снова 4 2 6 7 3 , обведём 6 вкруг (
pivot) и поставим под ним
L. Теперь двигаем указатель
R. 3 меньше чем 6, поэтому ставим маркер
R на цифру 3. Так How 3 меньше, чем
pivot 6 выполняем
swap, т.е. обмен. Запишем результат: 4 2 3 7 6 , обводим 6 вкруг, т.к. он по прежнему
pivot. Указатель
L на цифре 3, указатель
R на цифре 6. Мы помним, что двигаем указатели до тех пор, пока
L не зайдём за
R.
L двигаем на следующую цифру. Тут хочется разобрать два варианта: если бы предпоследняя цифра была 7 и если бы она была не 7, а 1.
Предпоследня цифра 1: Сдвинули указатель
L на цифру 1, т.к. мы можем двигать
L до тех пор, пока указатель
L указывает на цифру, меньшую чем
pivot. А вот
R мы не можем сдвинуть с 6, т.к. R не мы можем двигать только если указатель
R указывает на цифру, которая больше чем
pivot.
swap не делаем, т.к. 1 меньше 6. Записываем положение: 4 2 3 1 6, обводим
pivot 6.
L сдвигается на
pivot и больше не двигается.
R тоже не двигается. Обмен не производим. Сдвигаем
L и
R на одну позицию и подписываем цифру 1 маркером
R, а
L получается вне числа. Т.к.
L вне числа — ничего не делаем, а вот часть 4 2 3 1 выписываем снова, т.к. это наша левая часть, меньшая, чем
pivot 6. Выделяем новый
pivot и начинаем всё снова )
Предпоследняя цифра 7: Сдвинули указать
L на цифру 7, правый указатель не можем двигать, т.к. он уже указывает на pivot. т.к. 7 больше, чем
pivot, то делаем
swap. Запишем результат: 4 2 3 6 7, обводим 6 кружком, т.к. он
pivot. Указатель
L теперь сдвигается на цифру 7, а указатель
R сдвигается на цифру 3. Часть от
L до конца нет смысла сортировать, т.к. там всего 1 элемент, а вот часть от 4 до указателя
R отправляем на сортировку. Выбираем
pivot и начинаем всё снова ) Может на первый взгляд показаться, что если расставить много одинаковых с
pivot значений, это сломает алгоритм, но это не так. Можно напридумывать каверзных вариантов и на бумажке убедиться, что всё правильно и подивиться, How такие простые действия предоставляют такой надёжный механизм. Единственный минус — такая sorting не является стабильной. Т.к. при выполнении обмена одинаковые элементы могут поменять свой порядок, если один из них встретился до
pivot до того, How другой элемент попал в часть до
pivot при помощи обмена. Материал:
Выше мы рассмотрели "джентельменский" набор алгоритмов сортировки, реализованных на Java. Алгоритмы вообще штука полезная, How с прикладной точки зрения, так и с точки зрения развития мышления. Некоторые из них попроще, некоторые посложнее. По Howим-то умные люди защищали различные работы на степени, а по другим писали толстые-толстые книги. Надеюсь, приложенный к статье материал позволит вам узнать ещё больше, так How это обзорная статья, которая и так получилась увесистой. И цель её — дать небольшое вступление. Про введение в алгоритмы можно так же прочитать ознакомиться с книгой "
Грокаем Алгоримы". Также мне нравится плэйлист от Jack Brown —
AQA Decision 1 1.01 Tracing an Algorithm. Ради интереса можно посмотреть на визуализацию алгоритмов на
sorting.at и
visualgo.net. Ну и весь Youtube к вашим услугам.









GO TO FULL VERSION