بداية الطريق
أود اليوم أن أتحدث عن موضوع مثير للاهتمام مثل "
Java Collections Framework " أو، بعبارات بسيطة، عن المجموعات. يقوم معظم عمل الكود على معالجة البيانات بشكل أو بآخر. احصل على قائمة بالمستخدمين، واحصل على قائمة بالعناوين، وما إلى ذلك. قم بفرزها بطريقة أو بأخرى وإجراء بحث ومقارنتها. ولهذا السبب تعتبر معرفة المجموعات مهارة أساسية. لهذا السبب أريد أن أتحدث عن ذلك. بالإضافة إلى ذلك، أحد الأسئلة الأكثر شيوعًا في مقابلات مطوري Java هو المجموعات. على سبيل المثال، "رسم تسلسل هرمي للمجموعات." سيساعدنا المترجم عبر الإنترنت في طريقنا. على سبيل المثال، يمكنك استخدام " Tutorialspoint
Online Java Compiler " أو
Repl.it. يبدأ الطريق للتعرف على أي هياكل بيانات بالمتغيرات العادية (المتغيرات). على موقع ويب Oracle، يتم تمثيل موضوعات مختلفة على أنها "مسارات" أو مسارات. لذلك، فإن الطريق للتعرف على Java يسمى "
المسار: تعلم لغة Java: جدول المحتويات ". وأساسيات اللغة (أي أساسيات اللغة) تبدأ بالمتغيرات. لذلك، دعونا نكتب رمزًا بسيطًا:
public static void main(String[] args) {
String user = "Max";
System.out.println("Hello, " + user);
}
إنه جيد في كل شيء، إلا أننا نفهم أن هذا الكود جيد وجميل لمتغير واحد فقط. ماذا تفعل إذا كان هناك العديد منهم؟ تم اختراع المصفوفات لتخزين البيانات من نوع واحد. يوجد في نفس المسار من Oracle قسم منفصل مخصص للمصفوفات. يسمى هذا القسم: "
المصفوفات ". العمل مع المصفوفات بسيط جدًا أيضًا:
import java.util.Arrays;
class Main {
public static void main(String[] args) {
String[] users = new String[2];
users[0] = "Max";
users[1] = "John";
System.out.println("Hello, " + Arrays.toString(users));
}
}
تحل المصفوفات مشكلة تخزين قيم متعددة في مكان واحد. لكنه يفرض قيودًا: حجم المصفوفة ثابت. إذا قلنا، كما في المثال، أن الحجم = 2، فهو يساوي اثنين. هذا كل شئ. إذا أردنا مصفوفة أكبر، فنحن بحاجة إلى إنشاء مثيل جديد. كما أن العثور على عنصر يعد أيضًا أمرًا صعبًا بالنسبة للمصفوفة. هناك طريقة
Arrays.binarySearch، ولكن هذا البحث يعمل فقط على مصفوفة مفروزة (بالنسبة للمصفوفة غير المصنفة، تكون النتيجة غير محددة أو ببساطة لا يمكن التنبؤ بها). أي أن البحث سيلزمنا بالفرز في كل مرة. يؤدي الحذف أيضًا إلى مسح القيمة فقط. لذلك، ما زلنا لا نعرف مقدار البيانات الموجودة بالفعل في المصفوفة، فنحن نعرف فقط عدد الخلايا الموجودة في المصفوفة. لتحديث معرفتك حول المصفوفات:
ونتيجة لتطور لغة جافا ظهر Java Collections Framework في JDK 1.2 والذي سنتحدث عنه اليوم.
مجموعة
البدء في حساب التكاليف من البداية. لماذا المجموعات؟ المصطلح نفسه يأتي من أشياء مثل "نظرية النوع" و"أنواع البيانات المجردة". لكن إذا كنت لا تنظر إلى أي أمور عالية، فعندما يكون لدينا عدة أشياء، يمكننا أن نسميها "مجموعة من الأشياء". أولئك الذين يجمعون العناصر. بشكل عام، كلمة جمع نفسها تأتي من اللات. Collectio "جمع، جمع". أي أن المجموعة عبارة عن مجموعة من شيء ما، وهي حاوية لبعض العناصر. لذلك لدينا مجموعة من العناصر. ما قد نرغب في فعله به:
كما ترون، قد نريد أشياء منطقية تماما. ندرك أيضًا أننا قد نرغب في القيام بشيء ما بمجموعات متعددة:
وفقًا لذلك، قام مطورو Java بكتابة واجهة java.util.Collection لوصف هذا السلوك العام لجميع المجموعات . واجهة المجموعة هي المكان الذي تنشأ فيه جميع المجموعات. المجموعة هي فكرة، إنها فكرة عن كيفية تصرف جميع المجموعات. لذلك، يتم التعبير عن مصطلح "المجموعة" كواجهة. وبطبيعة الحال، تحتاج الواجهة إلى تطبيقات. تحتوي الواجهة
java.util.Collectionعلى فئة مجردة
AbstractCollection، أي بعض "المجموعة المجردة"، والتي تمثل الهيكل العظمي للتطبيقات الأخرى (كما هو مكتوب في JavaDoc أعلى الفئة
java.util.AbstractCollection). عند الحديث عن المجموعات، دعونا نعود ونتذكر أننا نريد تكرارها. هذا يعني أننا نريد تكرار العناصر واحدًا تلو الآخر. وهذا مفهوم مهم جدا.
Collectionلذلك، يتم توريث الواجهة من
Iterable. وهذا مهم جداً لأنه... أولاً، يجب أن يكون كل شيء قابل للتكرار قادرًا على إرجاع مكرر بناءً على محتوياته. وثانيًا، كل ما يمكن استخدام Iterable فيه هو الحلقات
for-each-loop. وبمساعدة المكرر يتم تنفيذ أساليب
AbstractCollectionمثل
contains. والطريق إلى فهم المجموعات يبدأ بأحد هياكل البيانات الأكثر شيوعًا - القائمة، أي. .
toArrayremoveList
القوائم
لذا، تحتل القوائم مكانًا مهمًا في التسلسل الهرمي للمجموعات:
كما نرى، تقوم القوائم بتنفيذ واجهة
java.util.List . تعبر القوائم عن أن لدينا مجموعة من العناصر مرتبة في تسلسل ما واحدًا تلو الآخر. يحتوي كل عنصر على فهرس (كما هو الحال في المصفوفة). عادةً، تسمح لك القائمة بالحصول على عناصر لها نفس القيمة. كما قلنا أعلاه،
Listفهو يعرف عن فهرس العنصر. يتيح لك هذا الحصول على (
get) عنصر حسب الفهرس أو تعيين قيمة لفهرس معين (
set). تتيح لك
addطرق التجميع تحديد الفهرس الذي سيتم تنفيذ هذه الطرق منه. بالإضافة إلى ذلك، y لديه نسخته الخاصة من المكرر يسمى . يعرف هذا المكرر فهرس العنصر، لذلك يمكنه التكرار ليس فقط للأمام، ولكن أيضًا للخلف. ويمكن حتى إنشائه من مكان محدد في المجموعة. من بين جميع التطبيقات، هناك نوعان من التطبيقات الأكثر استخدامًا: و . أولاً، إنها قائمة ( ) مبنية على مصفوفة ( ). يتيح لك ذلك تحقيق "الوصول العشوائي"
إلى العناصر. الوصول العشوائي هو القدرة على استرداد عنصر على الفور عن طريق الفهرس، بدلاً من التكرار عبر جميع العناصر حتى نجد العنصر ذو الفهرس المطلوب. إنها المصفوفة كأساس الذي يسمح بتحقيق ذلك. على العكس من ذلك، فهي قائمة مرتبطة. يتم تمثيل كل إدخال في القائمة المرتبطة في النموذج ، الذي يخزن البيانات نفسها، بالإضافة إلى رابط إلى التالي (التالي) والسابق (السابق) . وبالتالي ينفذ "الوصول المتسلسل
" . من الواضح أنه للعثور على العنصر الخامس، سيتعين علينا الانتقال من العنصر الأول إلى العنصر الأخير، لأنه ليس لدينا إمكانية الوصول المباشر إلى العنصر الخامس. لا يمكننا الوصول إليه إلا من العنصر الرابع. الفرق في مفهومهم موضح أدناه:
addAllremoveListListIteratorArrayListLinkedListArrayListListArrayLinkedListEntryEntryLinkedList
في العمل، كما تفهم، هناك أيضا فرق. على سبيل المثال، إضافة العناصر. ترتبط العناصر
LinkedListببساطة مثل الروابط في السلسلة. لكنه
ArrayListيخزن العناصر في صفيف. والمصفوفة، كما نعلم، لا يمكنها تغيير حجمها. اذن كيف تعمل
ArrayList؟ ويعمل بكل بساطة. عندما تنفد المساحة في المصفوفة، فإنها تزيد بمقدار 1.5 مرة. إليك رمز التكبير/التصغير: هناك
int newCapacity = oldCapacity + (oldCapacity >> 1); اختلاف آخر في العملية وهو أي إزاحة للعناصر. على سبيل المثال، عند إضافة أو إزالة العناصر إلى المنتصف. للإزالة من
LinkedListعنصر ما، ما عليك سوى إزالة المراجع إلى هذا العنصر. في حالة،
ArrayListنحن مضطرون إلى تغيير العناصر في كل مرة باستخدام
System.arraycopy. وبالتالي، كلما زاد عدد العناصر، كلما زاد عدد الإجراءات التي يجب تنفيذها. يمكن العثور على وصف أكثر تفصيلاً في هذه المقالات:
بعد فحص ArrayList، لا يسع المرء إلا أن يتذكر "سلفه"، فئة
java.util.Vector . يختلف
Vectorفي
ArrayListأن طرق العمل مع المجموعة (الإضافة والحذف وما إلى ذلك) متزامنة. أي أنه إذا قام أحد الخيوط (
Thread) بإضافة عناصر، فستنتظر الخيوط الأخرى حتى ينتهي الخيط الأول من عمله. نظرًا لأن أمان سلسلة الرسائل ليس مطلوبًا في كثير من الأحيان، فمن المستحسن استخدام الفئة في مثل هذه الحالات
ArrayList، كما هو منصوص عليه صراحةً في JavaDoc للفئة
Vector. بالإضافة إلى ذلك،
Vectorفهو يزيد حجمه ليس بمقدار 1.5 مرة،
ArrayListبل مرتين. بخلاف ذلك، يكون السلوك هو نفسه -
Vectorيتم إخفاء تخزين العناصر في شكل مصفوفة وتكون إضافة/إزالة العناصر لها نفس العواقب كما في
ArrayList. في الواقع،
Vectorتذكرنا هذا لسبب ما. إذا نظرنا إلى Javadoc، فسنرى في "الفئات الفرعية المعروفة المباشرة" بنية مثل
java.util.Stack . المكدس عبارة عن بنية مثيرة للاهتمام وهي
last-in-first-outبنية LIFO (آخر ما يدخل يخرج أولاً). المكدس المترجم من الإنجليزية هو كومة (مثل كومة من الكتب، على سبيل المثال). تنفذ المكدس طرقًا إضافية:
peek(انظر، انظر)،
pop(ادفع)،
push(ادفع). تتم ترجمة الطريقة
peekإلى "نظرة" (على سبيل المثال، تتم ترجمة
نظرة خاطفة داخل الحقيبة إلى "
نظرة خاطفة داخل الحقيبة "، وتتم ترجمة
نظرة خاطفة على ثقب المفتاح إلى " نظرة خاطفة على ثقب المفتاح "). تسمح لك هذه الطريقة بالنظر إلى "الجزء العلوي" من المكدس، أي. احصل على العنصر الأخير دون إزالته (أي دون إزالته) من المكدس. تقوم الطريقة
pushبدفع (إضافة) عنصر جديد إلى المكدس وإعادته، وتقوم طريقة العنصر
popبدفع (إزالة) وإرجاع العنصر المحذوف. في جميع الحالات الثلاث (أي النظرة الخاطفة والبوب والدفع)، فإننا نعمل فقط مع العنصر الأخير (أي "أعلى المكدس"). هذه هي الميزة الرئيسية لهيكل المكدس. بالمناسبة، هناك مهمة مثيرة للاهتمام لفهم المكدسات، الموصوفة في كتاب "A Programmer's Career" (مقابلة Cracking Coding). هناك مهمة مثيرة للاهتمام حيث باستخدام بنية "المكدس" (LIFO) تحتاج إلى تنفيذ "قائمة الانتظار" "الهيكل (FIFO). يجب أن تبدو هذه:
يمكن العثور على تحليل هذه المهمة هنا: "
تنفيذ قائمة انتظار باستخدام الأكوام - قائمة الانتظار ADT ("تنفيذ قائمة الانتظار باستخدام الأكوام" على LeetCode) ". لذلك ننتقل بسلاسة إلى بنية بيانات جديدة - قائمة الانتظار.
طابور
قائمة الانتظار هي بنية مألوفة لنا في الحياة. طوابير أمام المحلات التجارية والأطباء. من يأتي أولاً (أولاً في الداخل) سيكون أول من يغادر قائمة الانتظار (أولاً يخرج). في Java، يتم تمثيل قائمة الانتظار بواسطة الواجهة
java.util.Queue . وفقًا لـ Javadoc الخاص بقائمة الانتظار، تضيف قائمة الانتظار الطرق التالية:
كما ترون، هناك طرق الطلب (عدم تنفيذها محفوف بالاستثناء) وهناك طرق الطلب (عدم القدرة على تنفيذها لا يؤدي إلى أخطاء). من الممكن أيضًا الحصول على العنصر دون إزالته (نظرة خاطفة أو عنصر). تحتوي واجهة قائمة الانتظار أيضًا على خليفة مفيد -
Deque . هذا هو ما يسمى "قائمة الانتظار ذات الاتجاهين". أي أن قائمة الانتظار هذه تسمح لك باستخدام هذا الهيكل من البداية ومن النهاية. تشير الوثائق إلى أنه "يمكن أيضًا استخدام Deques كمكدسات LIFO (Last-In-First-Out). يجب استخدام هذه الواجهة بدلاً من فئة Stack القديمة. "، أي أنه يوصى باستخدام تطبيقات Deque بدلاً من كومة. يعرض Javadoc الطرق التي تصفها واجهة Deque:
دعونا نرى ما هي التطبيقات هناك. وسنرى حقيقة مثيرة للاهتمام - لقد وصل LinkedList إلى معسكر قائمة الانتظار) أي أن LinkedList ينفذ كلاً من
Listو
Deque. ولكن هناك أيضًا "طوابير الانتظار فقط"، على سبيل المثال
PriorityQueue. لا يتم تذكرها كثيرًا، ولكن عبثًا. أولاً، لا يمكنك استخدام "كائنات غير قابلة للمقارنة" في قائمة الانتظار هذه، أي: يجب تحديد المقارنة أو يجب أن تكون جميع الكائنات قابلة للمقارنة. ثانيًا، "يوفر هذا التنفيذ وقتًا O(log(n)) لطرق الانتظار وإلغاء الانتظار". التعقيد اللوغاريتمي موجود لسبب ما. تم تنفيذ PriorityQueue بناءً على الكومة. يقول Javadoc: "يتم تمثيل قائمة الانتظار ذات الأولوية على شكل كومة ثنائية متوازنة". التخزين نفسه لهذا هو مجموعة عادية. الذي ينمو عند الضرورة. عندما تكون الكومة صغيرة، فإنها تزيد مرتين. ومن ثم بنسبة 50%. تعليق من الكود: "حجم مزدوج إذا كان صغيرًا؛ وإلا سينمو بنسبة 50%". تعد قائمة انتظار الأولوية والكومة الثنائية موضوعًا منفصلاً. لذلك لمزيد من المعلومات:
java.util.Dequeيمكن أن يكون التنفيذ هو فئة
java.util.ArrayDeque . أي أنه يمكن تنفيذ القوائم باستخدام قائمة مرتبطة ومصفوفة، ويمكن أيضًا تنفيذ قوائم الانتظار باستخدام مصفوفة أو باستخدام قائمة مرتبطة. تحتوي الواجهات
Queueو
Dequeعلى فروع تمثل "قائمة انتظار الحظر":
BlockingQueueو
BlockingDeque. إليك تغيير الواجهة مقارنةً بقوائم الانتظار العادية:
دعونا نلقي نظرة على بعض الأمثلة على حظر قوائم الانتظار. لكنها مثيرة للاهتمام. على سبيل المثال، يتم تنفيذ BlockingQueue بواسطة:
PriorityBlockingQueue و
SynchronousQueue و ArrayBlockingQueue و
DelayQueue و
LinkedBlockingQueue . لكنهم
BlockingDequeينفذون كل شيء بدءًا من أطر عمل المجموعة القياسية
LinkedBlockingDeque. كل قائمة انتظار هي موضوع مراجعة منفصلة. وفي إطار هذه المراجعة، سنصور التسلسل الهرمي للفصل ليس فقط مع
List، ولكن أيضًا مع
Queue:
كما يمكننا أن نرى من الرسم البياني، فإن واجهات وفئات Java Collections Framework متشابكة بشكل كبير. دعونا نضيف فرعًا آخر من التسلسل الهرمي -
Set.
تعيين
Set- تُرجمت كـ "مجموعة". وهو يختلف عن قائمة الانتظار والقائمة
Setفي تجريده الأكبر لتخزين العناصر.
Set- مثل كيس الأشياء، حيث لا يُعرف كيف توجد الأشياء وبأي ترتيب توضع. في Java، يتم تمثيل هذه المجموعة بواسطة الواجهة
java.util.Set . كما تقول الوثائق،
Setهذه "مجموعة لا تحتوي على عناصر مكررة". ومن المثير للاهتمام أن الواجهة نفسها
Setلا تضيف طرقًا جديدة إلى الواجهة
Collection، ولكنها توضح فقط المتطلبات (حول ما لا ينبغي أن يحتوي على نسخ مكررة). بالإضافة إلى ذلك، من الوصف السابق، يتبع أنه من المستحيل
Setالحصول على عنصر منه. يستخدم التكرار للحصول على العناصر.
Setلديه العديد من الواجهات المرتبطة به. اول واحد هو
SortedSet. كما يوحي الاسم،
SortedSetفإنه يشير إلى أن هذه المجموعة مرتبة، وبالتالي فإن العناصر تنفذ الواجهة
Comparableأو يتم تحديدها
Comparator. بالإضافة إلى ذلك،
SortedSetفهو يقدم عدة طرق مثيرة للاهتمام:
بالإضافة إلى ذلك، هناك طرق
first(أصغر عنصر من حيث القيمة) و
last(أكبر عنصر من حيث القيمة). هناك
SortedSetوريث -
NavigableSet. الغرض من هذه الواجهة هو وصف طرق التنقل اللازمة لتحديد العناصر المناسبة بشكل أكثر دقة. الشيء المثير للاهتمام هو
NavigableSetأنه يضيف إلى المكرر المعتاد (الذي ينتقل من الأصغر إلى الأكبر) مكررًا للترتيب العكسي -
descendingIterator. بالإضافة إلى ذلك،
NavigableSetيسمح لك باستخدام الطريقة
descendingSetللحصول على عرض لنفسك (عرض)، حيث تكون العناصر بترتيب عكسي. وهذا ما يسمى
Viewلأنه من خلال العنصر الناتج يمكنك تغيير عناصر العنصر الأصلي
Set. أي أنها في جوهرها تمثيل للبيانات الأصلية بطريقة مختلفة، وليست نسخة منها. ومن المثير للاهتمام أن
NavigableSet، مثل
Queue، يمكنه التعامل مع العناصر
pollFirst(الحد الأدنى) و
pollLast(الحد الأقصى). أي أنه يحصل على هذا العنصر ويزيله من المجموعة. ما هي أنواع التطبيقات الموجودة؟ أولاً، يعتمد التنفيذ الأكثر شهرة على رمز التجزئة -
HashSet . تطبيق آخر معروف بنفس القدر يعتمد على شجرة حمراء وسوداء -
TreeSet . لنكمل مخططنا:
ضمن المجموعات، يبقى فرز التسلسل الهرمي - النساك. الذي للوهلة الأولى يقف جانبا -
java.util.Map.
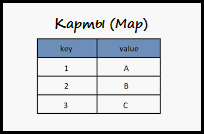
خرائط
الخرائط هي بنية بيانات يتم فيها تخزين البيانات عن طريق المفتاح. على سبيل المثال، يمكن أن يكون المفتاح عبارة عن معرف أو رمز مدينة. ومن خلال هذا المفتاح سيتم البحث عن البيانات. ومن المثير للاهتمام أن البطاقات يتم عرضها بشكل منفصل. وفقًا للمطورين (راجع "
الأسئلة الشائعة حول تصميم واجهة برمجة تطبيقات Java Collections ")، فإن تعيين القيمة الرئيسية ليس مجموعة. ويمكن اعتبار الخرائط بسرعة أكبر بمثابة مجموعة من المفاتيح، أو مجموعة من القيم، أو مجموعة من أزواج القيمة الرئيسية. هذا حيوان مثير للاهتمام. ما هي الطرق التي توفرها البطاقات؟ دعونا نلقي نظرة على واجهة Java API
java.util.Map . لأن نظرًا لأن الخرائط ليست مجموعات (لا ترث من المجموعات)، فهي لا تحتوي على ملف
contains. وهذا منطقي. تتكون الخريطة من المفاتيح والقيم. أي مما يلي يجب أن تتحقق منه الطريقة
containsوكيف لا يتم الخلط بينها؟ ولذلك فإن الواجهة
Mapلها نسختان مختلفتان:
containsKey(تحتوي على مفتاح) و
containsValue(تحتوي على قيمة). يتيح لك استخدامه
keySetالحصول على مجموعة من المفاتيح (نفس المفتاح
Set). وباستخدام الطريقة
valuesيمكننا الحصول على مجموعة من القيم في الخريطة. المفاتيح الموجودة في الخريطة فريدة من نوعها، وهو ما تؤكده بنية البيانات
Set. يمكن تكرار القيم، وهو ما يتم التأكيد عليه من خلال بنية بيانات المجموعة. بالإضافة إلى ذلك، باستخدام الطريقة
entrySetيمكننا الحصول على مجموعة من أزواج القيمة الرئيسية. يمكنك قراءة المزيد حول تطبيقات البطاقة الموجودة في التحليلات الأكثر تفصيلاً:
أود أيضًا أن أرى ما هو
HashMapمشابه جدًا لـ
HashSetو
TreeMapلـ
TreeSet. لديهم أيضًا واجهات متشابهة:
NavigableSetو
NavigableMapو
SortedSetو
SortedMap. لذلك ستبدو خريطتنا النهائية كما يلي:
يمكننا أن ننتهي بحقيقة مثيرة للاهتمام وهي أن المجموعة
Setتستخدم داخليًا
Map، حيث تكون القيم المضافة مفاتيح، والقيمة هي نفسها في كل مكان. هذا مثير للاهتمام لأنه
Mapليس مجموعة وإرجاع
Set، وهو عبارة عن مجموعة ولكن في الواقع يتم تنفيذه كـ
Map. سريالية بعض الشيء، ولكن هكذا اتضح)
خاتمة
والخبر السار هو أن هذا ينهي هذه المراجعة. الخبر السيئ هو أن هذه مقالة مراجعة للغاية. يستحق كل تطبيق لكل مجموعة مقالة منفصلة، وكذلك لكل خوارزمية مخفية عن أعيننا. لكن الغرض من هذه المراجعة هو تذكر ماهيتها وما هي الروابط بين الواجهات. آمل أنه بعد القراءة المدروسة، ستتمكن من رسم مخطط للمجموعات من الذاكرة.
حسنًا، كالعادة، بعض الروابط:
# فياتشيسلاف


















GO TO FULL VERSION