The modern development world is full of various specifications designed to make life easier. Knowing the tools, you can choose the right one. Without knowing, you can make your life more difficult. This review will lift the veil of secrecy over the concept of JPA - Java Persistence API. I hope that after reading you will want to dive even deeper into this mysterious world.
Introduction
As we know, one of the main tasks of programs is storing and processing data. In the good old days, people simply stored data in files. But as soon as simultaneous read and edit access is needed, when there is a load (i.e., several requests arrive at the same time), storing data simply in files becomes a problem. For more information about what problems databases solve and how, I advise you to read the article “
How databases are structured .” This means that we decide to store our data in a database. For a long time, Java has been able to work with databases using the JDBC API (The Java Database Connectivity). You can read more about JDBC here: “
JDBC or where it all begins .” But time passed and developers each time faced the need to write the same type and unnecessary “maintenance” code (the so-called Boilerplate code) for trivial operations on saving Java objects in the database and vice versa, creating Java objects using data from the database. And then, to solve these problems, such a concept as ORM was born.
ORM - Object-Relational Mapping or translated into Russian object-relational mapping. It is a programming technology that links databases with the concepts of object-oriented programming languages. To simplify, ORM is the connection between Java objects and records in a database:
![JPA: Introduction to Technology - 2]()
ORM is essentially the concept that a Java object can be represented as data in a database (and vice versa). It was embodied in the form of the JPA specification - Java Persistence API. The specification is already a description of the Java API that expresses this concept. The specification tells us what tools we must be provided with (i.e., what interfaces we can work through) in order to work according to the ORM concept. And how to use these funds. The specification does not describe the implementation of the tools. This makes it possible to use different implementations for one specification. You can simplify it and say that a specification is a description of the API. The text of the JPA specification can be found on the Oracle website: "
JSR 338: JavaTM Persistence API ". Therefore, in order to use JPA, we need some implementation with which we will use the technology. JPA implementations are also called JPA Providers. One of the most notable JPA implementations is
Hibernate . Therefore, I propose to consider it.
Creating a Project
Since JPA is about Java, we will need a Java project. We could manually create the directory structure ourselves and add the necessary libraries ourselves. But it is much more convenient and correct to use systems for automating the assembly of projects (i.e., in essence, this is just a program that will manage the assembly of projects for us. Create directories, add the necessary libraries to the classpath, etc.). One such system is Gradle. You can read more about Gradle here: "
A Brief Introduction to Gradle ". As we know, Gradle functionality (i.e. the things it can do) is implemented using various Gradle Plugins. Let's use Gradle and the "
Gradle Build Init Plugin " plugin. Let's run the command:
gradle init --type java-application
Gradle will do the necessary directory structure for us and create a basic declarative description of the project in the build script
build.gradle. So, we have an application. We need to think about what we want to describe or model with our application. Let's use some modeling tool, for example:
app.quickdatabasediagrams.com ![JPA: Introduction to Technology - 4]()
Here it is worth saying that what we have described is our “domain model”. A domain is a “subject area”. In general, domain is “possession” in Latin. In the Middle Ages, this was the name given to areas owned by kings or feudal lords. And in French it became the word "domaine", which simply translates as "area". Thus we described our “domain model” = “subject model”. Each element of this model is some kind of “essence”, something from real life. In our case, these are entities: Category (
Category), Subject (
Topic). Let's create a separate package for the entities, for example with the name model. And let's add Java classes there that describe entities. In Java code, such entities are a regular
POJO , which may look like this:
public class Category {
private Long id;
private String title;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
Let's copy the contents of the class and create a class by analogy
Topic. He will differ only in what he knows about the category to which he belongs. Therefore, let’s add
Topica category field and methods for working with it to the class:
private Category category;
public Category getCategory() {
return category;
}
public void setCategory(Category category) {
this.category = category;
}
Now we have a Java application that has its own domain model. Now it's time to start connecting to the JPA project.
Adding JPA
So, as we remember, JPA means that we will save something in the database. Therefore, we need a database. To use a database connection in our project, we need to add a dependency library to connect to the database. As we remember, we used Gradle, which created a build script for us
build.gradle. In it we will describe the dependencies that our project needs. Dependencies are those libraries without which our code cannot work. Let's start with a description of the dependency on connecting to the database. We do this the same way we would do it if we were just working with JDBC:
dependencies {
implementation 'com.h2database:h2:1.4.199'
Now we have a database. We can now add a layer to our application that is responsible for mapping our Java objects into database concepts (from Java to SQL). As we remember, we are going to use an implementation of the JPA specification called Hibernate for this:
dependencies {
implementation 'com.h2database:h2:1.4.199'
implementation 'org.hibernate:hibernate-core:5.4.2.Final'
Now we need to configure JPA. If we read the specification and section "8.1 Persistence Unit", we will know that a Persistence Unit is some kind of combination of configurations, metadata and entities. And for JPA to work, you need to describe at least one Persistence Unit in the configuration file, which is called
persistence.xml. Its location is described in the specification chapter "8.2 Persistence Unit Packaging". According to this section, if we have a Java SE environment, then we must put it in the root of the META-INF directory.
Let's copy the content from the example given in the JPA specification in the "
8.2.1 persistence.xml file" chapter:
<persistence>
<persistence-unit name="JavaRush">
<description>Persistence Unit For test</description>
<class>hibernate.model.Category</class>
<class>hibernate.model.Topic</class>
</persistence-unit>
</persistence>
But this is not enough. We need to tell who our JPA Provider is, i.e. one who implements the JPA specification:
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
Now let's add settings (
properties). Some of them (starting with
javax.persistence) are standard JPA configurations and are described in the JPA specification in section "8.2.1.9 properties". Some configurations are provider-specific (in our case, they affect Hibernate as a Jpa Provider. Our settings block will look like this:
<properties>
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE" />
<property name="javax.persistence.jdbc.user" value="sa" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
Now we have a JPA-compatible config
persistence.xml, there is a JPA provider Hibernate and there is an H2 database, and there are also 2 classes that are our domain model. Let's finally make this all work. In the catalog
/test/java, our Gradle kindly generated a template for Unit tests and called it AppTest. Let's use it. As stated in the "7.1 Persistence Contexts" chapter of the JPA specification, entities in the JPA world live in a space called the Persistence Context. But we don't work directly with Persistence Context. For this we use
Entity Manageror "entity manager". It is he who knows about the context and what entities live there. We interact with
Entity Manager'om. Then all that remains is to understand where we can get this one from
Entity Manager? According to the chapter "7.2.2 Obtaining an Application-managed Entity Manager" of the JPA specification, we must use
EntityManagerFactory. Therefore, let’s arm ourselves with the JPA specification and take an example from the chapter “7.3.2 Obtaining an Entity Manager Factory in a Java SE Environment” and format it in the form of a simple Unit test:
@Test
public void shouldStartHibernate() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
EntityManager entityManager = emf.createEntityManager();
}
This test will already show the error "Unrecognized JPA persistence.xml XSD version". The reason is that
persistence.xmlyou need to correctly specify the schema to use, as stated in the JPA specification in section "8.3 persistence.xml Schema":
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
In addition, the order of the elements is important. Therefore,
providerit must be specified before listing the classes. After this, the test will run successfully. We have completed the direct JPA connection. Before we move on, let's think about the remaining tests. Each of our tests will require
EntityManager. Let's make sure that each test has its own
EntityManagerat the beginning of execution. In addition, we want the database to be new every time. Due to the fact that we use
inmemorythe option, it is enough to close
EntityManagerFactory. Creation
Factoryis an expensive operation. But for tests it is justified. JUnit allows you to specify methods that will be executed before (Before) and after (After) the execution of each test:
public class AppTest {
private EntityManager em;
@Before
public void init() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
em = emf.createEntityManager();
}
@After
public void close() {
em.getEntityManagerFactory().close();
em.close();
}
Now, before executing any test, a new one will be created
EntityManagerFactory, which will entail the creation of a new database, because
hibernate.hbm2ddl.autohas the meaning
create. And from the new factory we will get a new one
EntityManager.
Entities
As we remember, we previously created classes that describe our domain model. We have already said that these are our “essences”. This is the Entity that we will manage using
EntityManager. Let's write a simple test to save the essence of a category:
@Test
public void shouldPersistCategory() {
Category cat = new Category();
cat.setTitle("new category");
em.persist(cat);
}
But this test will not work right away, because... we will receive various errors that will help us understand what entities are:
-
Unknown entity: hibernate.model.Category
Why doesn't Hibernate understand what Categorythis is entity? The thing is that entities must be described according to the JPA standard.
Entity classes must be annotated with the annotation @Entity, as stated in the chapter "2.1 The Entity Class" of the JPA specification.
-
No identifier specified for entity: hibernate.model.Category
Entities must have a unique identifier that can be used to distinguish one record from another.
According to the chapter "2.4 Primary Keys and Entity Identity" of the JPA specification, "Every entity must have a primary key", i.e. Every entity must have a "primary key". Such a primary key must be specified by the annotation@Id
-
ids for this class must be manually assigned before calling save()
The ID has to come from somewhere. It can be specified manually, or it can be obtained automatically.
Therefore, as indicated in the chapters "11.2.3.3 GeneratedValue" and "11.1.20 GeneratedValue Annotation", we can specify the annotation @GeneratedValue.
So for the category class to become an entity we must make the following changes:
@Entity
public class Category {
@Id
@GeneratedValue
private Long id;
In addition, the annotation
@Idindicates which one to use
Access Type. You can read more about the access type in the JPA specification, in section "2.3 Access Type". To put it very briefly, because... we specified
@Idabove the field (
field), then the access type will be default
field-based, not
property-based. Therefore, the JPA provider will read and store values directly from the fields. If we placed
@Idabove the getter, then
property-basedaccess would be used, i.e. via getter and setter. When running the test, we also see what requests are sent to the database (thanks to the option
hibernate.show_sql). But when saving, we don't see any
insert's. It turns out that we actually didn’t save anything? JPA allows you to synchronize the persistence context and the database using the method
flush:
entityManager.flush();
But if we execute it now, we will get an error:
no transaction is in progress . And now it’s time to learn about how JPA uses transactions.
JPA Transactions
As we remember, JPA is based on the concept of persistence context. This is the place where entities live. And we manage entities through
EntityManager. When we execute the command
persist, we place the entity in the context. More precisely, we tell
EntityManager'y that this needs to be done. But this context is just some storage area. It is even sometimes called the "first level cache". But it needs to be connected to the database. The command
flush, which previously failed with an error, synchronizes data from the persistence context with the database. But this requires transport and this transport is a transaction. Transactions in JPA are described in the "7.5 Controlling Transactions" section of the specification. There is a special API for using transactions in JPA:
entityManager.getTransaction().begin();
entityManager.getTransaction().commit();
We need to add transaction management to our code, which runs before and after tests:
@Before
public void init() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
em = emf.createEntityManager();
em.getTransaction().begin();
}
@After
public void close() {
if (em.getTransaction().isActive()) {
em.getTransaction().commit();
}
em.getEntityManagerFactory().close();
em.close();
}
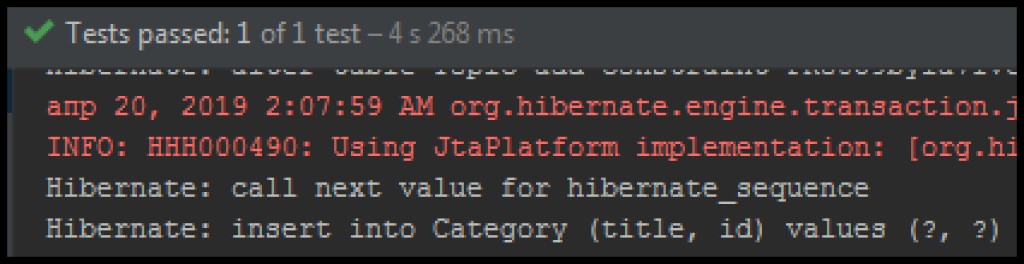
After adding, we will see in the insert log an expression in SQL that was not there before:
The changes accumulated in
EntityManagerthe transaction were committed (confirmed and saved) in the database. Let's now try to find our essence. Let's create a test to search for an entity by its ID:
@Test
public void shouldFindCategory() {
Category cat = new Category();
cat.setTitle("test");
em.persist(cat);
Category result = em.find(Category.class, 1L);
assertNotNull(result);
}
In this case, we will receive the entity we previously saved, but we will not see the SELECT queries in the log. And everything is based on what we say: “Entity Manager, please find me the Category entity with ID=1.” And the entity manager first looks in its context (uses a kind of cache), and only if it doesn’t find it, it goes to look in the database. It is worth changing the ID to 2 (there is no such thing, we saved only 1 instance), and we will see that
SELECTthe request appears. Because no entities were found in the context and
EntityManagerthe database is trying to find an entity. There are different commands that we can use to control the state of an entity in the context. The transition of an entity from one state to another is called the life cycle of the entity -
lifecycle.
Entity Lifecycle
The life cycle of entities is described in the JPA specification in the chapter "3.2 Entity Instance's Life Cycle". Because entities live in a context and are controlled by
EntityManager, then they say that entities are controlled, i.e. managed. Let's look at the stages of an entity's life:
Category cat = new Category();
cat.setTitle("new category");
entityManager.persist(cat);
entityManager.getTransaction().begin();
entityManager.getTransaction().commit();
entityManager.detach(cat);
Category managed = entityManager.merge(cat);
entityManager.remove(managed);
And here’s a diagram to consolidate it:
Mapping
In JPA we can describe the relationships of entities between each other. Let's remember that we already looked at the relationships of entities between each other when we dealt with our domain model. Then we used the
quickdatabasediagrams.com resource :
Establishing connections between entities is called mapping or association (Association Mappings). The types of associations that can be established using JPA are presented below:
Let's look at an entity
Topicthat describes a topic. What can we say about the attitude
Topictowards
Category? Many
Topicwill belong to one category. Therefore, we need an association
ManyToOne. Let's express this relationship in JPA:
@ManyToOne
@JoinColumn(name = "category_id")
private Category category;
To remember which annotations to put, you can remember that the last part is responsible for the field above which the annotation is indicated.
ToOne- specific instance.
ToMany- collections. Now our connection is one-way. Let's make it a two-way communication. Let's add to
Categorythe knowledge about everyone
Topicthat is included in this category. It must end with
ToMany, because we have a list
Topic. That is, the attitude “To many” topics. The question remains -
OneToManyor
ManyToMany:
A good answer on the same topic can be read here: "
Explain ORM oneToMany, manyToMany relation like I'm five ". If a category has a connection with
ToManytopics, then each of these topics can have only one category, then it will be
One, otherwise
Many. So the
Categorylist of all topics will look like this:
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "topic_id")
private Set<Topic> topics = new HashSet<>();
And let's not forget to essentially
Categorywrite a getter to get a list of all topics:
public Set<Topic> getTopics() {
return this.topics;
}
Bidirectional relationships are a very difficult thing to track automatically. Therefore, JPA shifts this responsibility to the developer. What this means for us is that when we establish an entity
Topicrelationship with
Category, we must ensure data consistency ourselves. This is done simply:
public void setCategory(Category category) {
category.getTopics().add(this);
this.category = category;
}
Let's write a simple test to check:
@Test
public void shouldPersistCategoryAndTopics() {
Category cat = new Category();
cat.setTitle("test");
Topic topic = new Topic();
topic.setTitle("topic");
topic.setCategory(cat);
em.persist(cat);
}
Mapping is a whole separate topic. The purpose of this review is to understand the means by which this is achieved. You can read more about mapping here:
JPQL
JPA introduces an interesting tool - queries in the Java Persistence Query Language. This language is similar to SQL, but uses the Java object model rather than SQL tables. Let's look at an example:
@Test
public void shouldPerformQuery() {
Category cat = new Category();
cat.setTitle("query");
em.persist(cat);
Query query = em.createQuery("SELECT c from Category c WHERE c.title = 'query'");
assertNotNull(query.getSingleResult());
}
As we can see, in the query we used a reference to an entity
Categoryand not a table. And also on the field of this entity
title. JPQL provides many useful features and deserves its own article. More details can be found in the review:
Criteria API
And finally, I would like to touch on the Criteria API. JPA introduces a dynamic query building tool. Example of using the Criteria API:
@Test
public void shouldFindWithCriteriaAPI() {
Category cat = new Category();
em.persist(cat);
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Category> query = cb.createQuery(Category.class);
Root<Category> c = query.from(Category.class);
query.select(c);
List<Category> resultList = em.createQuery(query).getResultList();
assertEquals(1, resultList.size());
}
This example is equivalent to executing the request "
SELECT c FROM Category c".
The Criteria API is a powerful tool. You can read more about it here:
Conclusion
As we can see, JPA provides a huge number of features and tools. Each of them requires experience and knowledge. Even within the framework of the JPA review, it was not possible to mention everything, not to mention a detailed dive. But I hope that after reading it, it became clearer what ORM and JPA are, how it works and what can be done with it. Well, for a snack I offer various materials:
#Viacheslav
 ORM is essentially the concept that a Java object can be represented as data in a database (and vice versa). It was embodied in the form of the JPA specification - Java Persistence API. The specification is already a description of the Java API that expresses this concept. The specification tells us what tools we must be provided with (i.e., what interfaces we can work through) in order to work according to the ORM concept. And how to use these funds. The specification does not describe the implementation of the tools. This makes it possible to use different implementations for one specification. You can simplify it and say that a specification is a description of the API. The text of the JPA specification can be found on the Oracle website: " JSR 338: JavaTM Persistence API ". Therefore, in order to use JPA, we need some implementation with which we will use the technology. JPA implementations are also called JPA Providers. One of the most notable JPA implementations is Hibernate . Therefore, I propose to consider it.
ORM is essentially the concept that a Java object can be represented as data in a database (and vice versa). It was embodied in the form of the JPA specification - Java Persistence API. The specification is already a description of the Java API that expresses this concept. The specification tells us what tools we must be provided with (i.e., what interfaces we can work through) in order to work according to the ORM concept. And how to use these funds. The specification does not describe the implementation of the tools. This makes it possible to use different implementations for one specification. You can simplify it and say that a specification is a description of the API. The text of the JPA specification can be found on the Oracle website: " JSR 338: JavaTM Persistence API ". Therefore, in order to use JPA, we need some implementation with which we will use the technology. JPA implementations are also called JPA Providers. One of the most notable JPA implementations is Hibernate . Therefore, I propose to consider it.

 Here it is worth saying that what we have described is our “domain model”. A domain is a “subject area”. In general, domain is “possession” in Latin. In the Middle Ages, this was the name given to areas owned by kings or feudal lords. And in French it became the word "domaine", which simply translates as "area". Thus we described our “domain model” = “subject model”. Each element of this model is some kind of “essence”, something from real life. In our case, these are entities: Category (
Here it is worth saying that what we have described is our “domain model”. A domain is a “subject area”. In general, domain is “possession” in Latin. In the Middle Ages, this was the name given to areas owned by kings or feudal lords. And in French it became the word "domaine", which simply translates as "area". Thus we described our “domain model” = “subject model”. Each element of this model is some kind of “essence”, something from real life. In our case, these are entities: Category ( 












GO TO FULL VERSION