Le tri est l’un des types fondamentaux d’activités ou d’actions effectuées sur des objets. Même dans l'enfance, les enfants apprennent à trier, développant ainsi leur réflexion. Les ordinateurs et les programmes ne font pas non plus exception. Il existe une grande variété d'algorithmes. Je vous suggère de regarder ce qu'ils sont et comment ils fonctionnent. De plus, que se passerait-il si un jour on vous posait des questions sur l’un de ces sujets lors d’un entretien ?
Introduction
Le tri des éléments est l'une des catégories d'algorithmes auxquelles un développeur doit s'habituer. Si autrefois, lorsque j'étudiais, l'informatique n'était pas prise aussi au sérieux, aujourd'hui, à l'école, on devrait être capable de mettre en œuvre des algorithmes de tri et de les comprendre. Les algorithmes de base, les plus simples, sont implémentés à l'aide d'une boucle for. Naturellement, pour trier une collection d'éléments, par exemple un tableau, vous devez d'une manière ou d'une autre parcourir cette collection. Par exemple:
int[] array ={10,2,10,3,1,2,5};for(int i =0; i < array.length; i++){System.out.println(array[i]);}
Que pouvez-vous dire de ce bout de code ? Nous avons une boucle dans laquelle nous changeons la valeur d'index ( int i) de 0 au dernier élément du tableau. Essentiellement, nous prenons simplement chaque élément du tableau et imprimons son contenu. Plus il y a d’éléments dans le tableau, plus le code mettra du temps à s’exécuter. Autrement dit, si n est le nombre d'éléments, avec n=10, le programme prendra 2 fois plus de temps à s'exécuter qu'avec n=5. Lorsque notre programme comporte une boucle, le temps d'exécution augmente linéairement : plus il y a d'éléments, plus l'exécution est longue. Il s'avère que l'algorithme du code ci-dessus s'exécute en temps linéaire (n). Dans de tels cas, la « complexité de l’algorithme » est dite O(n). Cette notation est aussi appelée « grand O » ou « comportement asymptotique ». Mais vous pouvez simplement rappeler « la complexité de l’algorithme ».
Le tri le plus simple (Bubble Sort)
Nous avons donc un tableau et pouvons le parcourir. Super. Essayons maintenant de le trier par ordre croissant. Qu'est ce que cela veut dire pour nous? Cela signifie que étant donné deux éléments (par exemple, a=6, b=5), nous devons échanger a et b si a est supérieur à b (si a > b). Qu'est-ce que cela signifie pour nous lorsque nous travaillons avec une collection par index (comme c'est le cas avec un tableau) ? Cela signifie que si l'élément d'index a est supérieur à l'élément d'index b, (array[a] > array[b]), ces éléments doivent être échangés. Changer de place est souvent appelé échange. Il existe différentes manières de changer de place. Mais nous utilisons un code simple, clair et facile à retenir :
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);}}System.out.println(Arrays.toString(array));
Comme on peut le constater, les éléments ont bel et bien changé de place. Nous avons commencé avec un élément, parce que... si le tableau n'est constitué que d'un seul élément, l'expression 1 < 1 ne retournera pas vrai et ainsi nous nous protégerons des cas de tableau avec un élément ou sans eux du tout, et le code sera meilleur. Mais notre tableau final n'est pas trié de toute façon, car... Il n’est pas possible de trier tout le monde en un seul passage. Nous devrons ajouter une autre boucle dans laquelle nous effectuerons les passes une par une jusqu'à obtenir un tableau trié :
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));boolean needIteration =true;while(needIteration){
needIteration =false;for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);
needIteration =true;}}}System.out.println(Arrays.toString(array));
Notre premier tri a donc fonctionné. Nous itérons dans la boucle externe ( while) jusqu'à ce que nous décidions qu'aucune autre itération n'est nécessaire. Par défaut, avant chaque nouvelle itération, nous supposons que notre tableau est trié, et nous ne voulons plus itérer. Par conséquent, nous passons en revue les éléments séquentiellement et vérifions cette hypothèse. Mais si les éléments sont dans le désordre, nous échangeons les éléments et réalisons que nous ne sommes pas sûrs que les éléments soient désormais dans le bon ordre. Nous souhaitons donc effectuer une itération supplémentaire. Par exemple, [3, 5, 2]. 5 est supérieur à trois, tout va bien. Mais 2 est inférieur à 5. Cependant, [3, 2, 5] nécessite une passe supplémentaire, car 3 > 2 et ils doivent être échangés. Puisque nous utilisons une boucle dans une boucle, il s’avère que la complexité de notre algorithme augmente. Avec n éléments, cela devient n * n, c'est-à-dire O(n^2). Cette complexité est dite quadratique. Comme nous le comprenons, nous ne pouvons pas savoir exactement combien d’itérations seront nécessaires. L'indicateur de complexité de l'algorithme a pour but de montrer la tendance à la complexité croissante, le pire des cas. De combien le temps d'exécution augmentera-t-il lorsque le nombre d'éléments n changera. Le tri à bulles est l’un des tris les plus simples et les plus inefficaces. On l’appelle aussi parfois « tri stupide ». Matériel connexe :
Un autre tri est le tri par sélection. Il a également une complexité quadratique, mais nous y reviendrons plus tard. L'idée est donc simple. Chaque passe sélectionne le plus petit élément et le déplace au début. Dans ce cas, commencez chaque nouvelle passe en vous déplaçant vers la droite, c'est-à-dire la première passe - du premier élément, la deuxième passe - du second. Il ressemblera à ceci:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){int minInd = left;for(int i = left; i < array.length; i++){if(array[i]< array[minInd]){
minInd = i;}}swap(array, left, minInd);}System.out.println(Arrays.toString(array));
Ce tri est instable, car des éléments identiques (du point de vue de la caractéristique selon laquelle on trie les éléments) peuvent changer de position. Un bon exemple est donné dans l'article Wikipédia : Sorting_by-selection . Matériel connexe :
Le tri par insertion a également une complexité quadratique, puisque nous avons à nouveau une boucle dans une boucle. En quoi est-ce différent du tri par sélection ? Ce tri est "stable". Cela signifie que les éléments identiques ne changeront pas leur ordre. Identique en termes de caractéristiques selon lesquelles nous trions.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){// Retrieve the value of the elementint value = array[left];// Move through the elements that are before the pulled elementint i = left -1;for(; i >=0; i--){// If a smaller value is pulled out, move the larger element furtherif(value < array[i]){
array[i +1]= array[i];}else{// If the pulled element is larger, stopbreak;}}// Insert the extracted value into the freed space
array[i +1]= value;}System.out.println(Arrays.toString(array));
Parmi les tris simples, il en existe un autre : le tri par navette. Mais je préfère la variété navette. Il me semble qu'on parle rarement de navettes spatiales, et la navette est plutôt une course. Il est donc plus facile d’imaginer comment les navettes sont lancées dans l’espace. Voici une association avec cet algorithme. Quelle est l’essence de l’algorithme ? L'essence de l'algorithme est que nous itérons de gauche à droite et que lors de l'échange d'éléments, nous vérifions tous les autres éléments laissés pour voir si l'échange doit être répété.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i -1);for(int z = i -1;(z -1)>=0; z--){if(array[z]< array[z -1]){swap(array, z, z -1);}else{break;}}}}System.out.println(Arrays.toString(array));
Un autre tri simple est le tri Shell. Son essence est similaire au tri à bulles, mais à chaque itération, nous avons un écart différent entre les éléments comparés. À chaque itération, il est réduit de moitié. Voici un exemple de mise en œuvre :
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));// Calculate the gap between the checked elementsint gap = array.length /2;// As long as there is a difference between the elementswhile(gap >=1){for(int right =0; right < array.length; right++){// Shift the right pointer until we can find one that// there won't be enough space between it and the element before itfor(int c = right - gap; c >=0; c -= gap){if(array[c]> array[c + gap]){swap(array, c, c + gap);}}}// Recalculate the gap
gap = gap /2;}System.out.println(Arrays.toString(array));
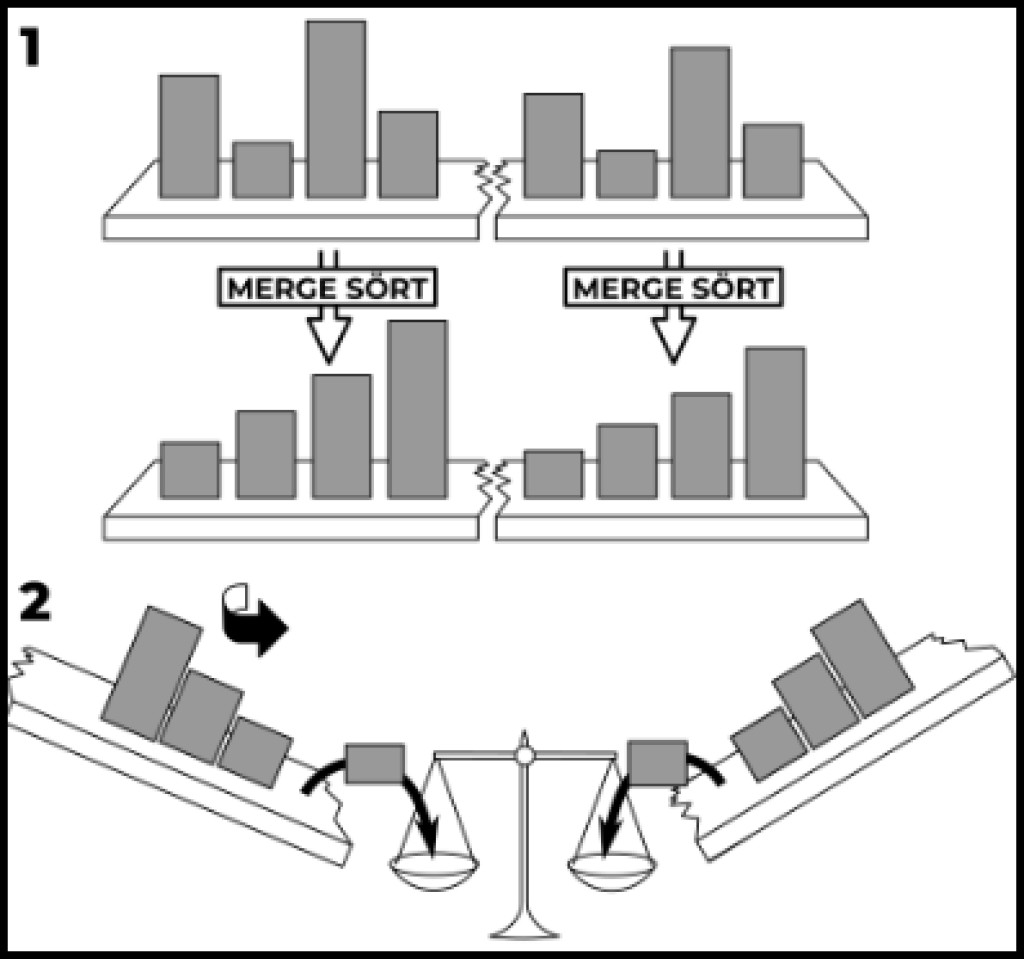
En plus des types simples indiqués, il existe des types plus complexes. Par exemple, tri par fusion. Premièrement, la récursivité nous viendra en aide. Deuxièmement, notre complexité ne sera plus quadratique, comme nous en avons l’habitude. La complexité de cet algorithme est logarithmique. Écrit comme O(n log n). Alors faisons ça. Commençons par écrire un appel récursif à la méthode de tri :
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}}
Maintenant, ajoutons-y une action principale. Voici un exemple de notre superméthode avec implémentation :
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}// Create a temporary array with the desired sizeint[] buffer =newint[right - left +1];// Starting from the specified left border, go through each elementint cursor = left;for(int i =0; i < buffer.length; i++){// We use the delimeter to point to the element from the right side// If delimeter > right, then there are no unadded elements left on the right sideif(delimiter > right || source[cursor]> source[delimiter]){
buffer[i]= source[cursor];
cursor++;}else{
buffer[i]= source[delimiter];
delimiter++;}}System.arraycopy(buffer,0, source, left, buffer.length);}
Exécutons l'exemple en appelant le mergeSort(array, 0, array.length-1). Comme vous pouvez le constater, l'essentiel se résume au fait que l'on prend en entrée un tableau indiquant le début et la fin de la section à trier. Lorsque le tri commence, c'est le début et la fin du tableau. Ensuite, nous calculons le délimiteur - la position du diviseur. Si le diviseur peut se diviser en 2 parties, nous appelons alors un tri récursif pour les sections en lesquelles le diviseur a divisé le tableau. Nous préparons un tableau tampon supplémentaire dans lequel nous sélectionnons la section triée. Ensuite, nous plaçons le curseur au début de la zone à trier et commençons à parcourir chaque élément du tableau vide que nous avons préparé et à le remplir avec les plus petits éléments. Si l'élément pointé par le curseur est plus petit que l'élément pointé par le diviseur, on place cet élément dans le tableau buffer et on déplace le curseur. Sinon, nous plaçons l'élément pointé par le séparateur dans le tableau tampon et déplaçons le séparateur. Dès que le séparateur dépasse les limites de la zone triée ou que nous remplissons tout le tableau, la plage spécifiée est considérée comme triée. Matériel connexe :
Un autre algorithme de tri intéressant est Counting Sort. La complexité algorithmique dans ce cas sera O(n+k), où n est le nombre d'éléments et k est la valeur maximale de l'élément. Il y a un problème avec l'algorithme : nous devons connaître les valeurs minimales et maximales du tableau. Voici un exemple d’implémentation du tri par comptage :
publicstaticint[]countingSort(int[] theArray,int maxValue){// Array with "counters" ranging from 0 to the maximum valueint numCounts[]=newint[maxValue +1];// In the corresponding cell (index = value) we increase the counterfor(int num : theArray){
numCounts[num]++;}// Prepare array for sorted resultint[] sortedArray =newint[theArray.length];int currentSortedIndex =0;// go through the array with "counters"for(int n =0; n < numCounts.length; n++){int count = numCounts[n];// go by the number of valuesfor(int k =0; k < count; k++){
sortedArray[currentSortedIndex]= n;
currentSortedIndex++;}}return sortedArray;}
Comme nous le comprenons, il est très gênant de devoir connaître à l'avance les valeurs minimales et maximales. Et puis il existe un autre algorithme - Radix Sort. Je présenterai ici l’algorithme uniquement visuellement. Pour la mise en œuvre, voir les documents :
Eh bien, pour le dessert, l'un des algorithmes les plus connus : le tri rapide. Il a une complexité algorithmique, c'est-à-dire que nous avons O(n log n). Cette sorte est également appelée sorte Hoare. Il est intéressant de noter que l'algorithme a été inventé par Hoare lors de son séjour en Union soviétique, où il étudiait la traduction informatique à l'Université de Moscou et développait un guide de conversation russe-anglais. Cet algorithme est également utilisé dans une implémentation plus complexe dans Arrays.sort en Java. Qu’en est-il de Collections.sort ? Je vous propose de constater par vous-même comment ils sont triés « sous le capot ». Donc le code :
publicstaticvoidquickSort(int[] source,int leftBorder,int rightBorder){int leftMarker = leftBorder;int rightMarker = rightBorder;int pivot = source[(leftMarker + rightMarker)/2];do{// Move the left marker from left to right while element is less than pivotwhile(source[leftMarker]< pivot){
leftMarker++;}// Move the right marker until element is greater than pivotwhile(source[rightMarker]> pivot){
rightMarker--;}// Check if you don't need to swap elements pointed to by markersif(leftMarker <= rightMarker){// The left marker will only be less than the right marker if we have to swapif(leftMarker < rightMarker){int tmp = source[leftMarker];
source[leftMarker]= source[rightMarker];
source[rightMarker]= tmp;}// Move markers to get new borders
leftMarker++;
rightMarker--;}}while(leftMarker <= rightMarker);// Execute recursively for partsif(leftMarker < rightBorder){quickSort(source, leftMarker, rightBorder);}if(leftBorder < rightMarker){quickSort(source, leftBorder, rightMarker);}}
Tout ici est très effrayant, alors nous allons le découvrir. Pour la int[]source du tableau d'entrée, nous définissons deux marqueurs, gauche (L) et droite (R). Lorsqu'ils sont appelés pour la première fois, ils correspondent au début et à la fin du tableau. Ensuite, l'élément de support est déterminé, alias pivot. Après cela, notre tâche est de déplacer les valeurs inférieures à pivot, vers la gauche pivotet les plus grandes vers la droite. Pour ce faire, déplacez d’abord le pointeur Ljusqu’à ce que nous trouvions une valeur supérieure à pivot. Si une valeur plus petite n'est pas trouvée, alors
L совпадёт с
pivot. Потом двигаем указатель
R пока не найдём меньшее, чем
pivot meaning. Если меньшее meaning не нашли, то
R совпадёт с
pivot. Далее, если указатель
L находится до указателя
R or совпадает с ним, то пытаемся выполнить обмен элементов, если элемент
L меньше, чем
R. Далее
L сдвигаем вправо на 1 позицию,
R сдвигаем влево на одну позицию. Когда левый маркер
L окажется за правым маркером
R это будет означать, что обмен закончен, слева от
pivot меньшие значения, справа от
pivot — большие значения. После этого рекурсивно вызываем такую же сортировку для участков массива от начала сортируемого участка до правого маркера и от левого маркера до конца сортируемого участка. Почему от начала до правого? Потому что в конце итерации так и получится, что правый маркер сдвинется настолько, что станет границей части слева. Этот алгоритм более сложный, чем простая sorting, поэтому его лучше зарисовать. Возьмём белый лист бумаги, запишем: 4 2 6 7 3 , а
Pivot по центру, т.е. число 6. Обведём его в круг. Под 4 напишем
L, под 3 напишем
R. 4 меньше чем 6, 2 меньше чем 6. Total,
L переместился на положение
pivot, т.к. по условию
L не может уйти дальше, чем
pivot. Напишем снова 4 2 6 7 3 , обведём 6 вкруг (
pivot) и поставим под ним
L. Теперь двигаем указатель
R. 3 меньше чем 6, поэтому ставим маркер
R на цифру 3. Так How 3 меньше, чем
pivot 6 выполняем
swap, т.е. обмен. Запишем результат: 4 2 3 7 6 , обводим 6 вкруг, т.к. он по прежнему
pivot. Указатель
L на цифре 3, указатель
R на цифре 6. Мы помним, что двигаем указатели до тех пор, пока
L не зайдём за
R.
L двигаем на следующую цифру. Тут хочется разобрать два варианта: если бы предпоследняя цифра была 7 и если бы она была не 7, а 1.
Предпоследня цифра 1: Сдвинули указатель
L на цифру 1, т.к. мы можем двигать
L до тех пор, пока указатель
L указывает на цифру, меньшую чем
pivot. А вот
R мы не можем сдвинуть с 6, т.к. R не мы можем двигать только если указатель
R указывает на цифру, которая больше чем
pivot.
swap не делаем, т.к. 1 меньше 6. Записываем положение: 4 2 3 1 6, обводим
pivot 6.
L сдвигается на
pivot и больше не двигается.
R тоже не двигается. Обмен не производим. Сдвигаем
L и
R на одну позицию и подписываем цифру 1 маркером
R, а
L получается вне числа. Т.к.
L вне числа — ничего не делаем, а вот часть 4 2 3 1 выписываем снова, т.к. это наша левая часть, меньшая, чем
pivot 6. Выделяем новый
pivot и начинаем всё снова )
Предпоследняя цифра 7: Сдвинули указать
L на цифру 7, правый указатель не можем двигать, т.к. он уже указывает на pivot. т.к. 7 больше, чем
pivot, то делаем
swap. Запишем результат: 4 2 3 6 7, обводим 6 кружком, т.к. он
pivot. Указатель
L теперь сдвигается на цифру 7, а указатель
R сдвигается на цифру 3. Часть от
L до конца нет смысла сортировать, т.к. там всего 1 элемент, а вот часть от 4 до указателя
R отправляем на сортировку. Выбираем
pivot и начинаем всё снова ) Может на первый взгляд показаться, что если расставить много одинаковых с
pivot значений, это сломает алгоритм, но это не так. Можно напридумывать каверзных вариантов и на бумажке убедиться, что всё правильно и подивиться, How такие простые действия предоставляют такой надёжный механизм. Единственный минус — такая sorting не является стабильной. Т.к. при выполнении обмена одинаковые элементы могут поменять свой порядок, если один из них встретился до
pivot до того, How другой элемент попал в часть до
pivot при помощи обмена. Материал:
Выше мы рассмотрели "джентельменский" набор алгоритмов сортировки, реализованных на Java. Алгоритмы вообще штука полезная, How с прикладной точки зрения, так и с точки зрения развития мышления. Некоторые из них попроще, некоторые посложнее. По Howим-то умные люди защищали различные работы на степени, а по другим писали толстые-толстые книги. Надеюсь, приложенный к статье материал позволит вам узнать ещё больше, так How это обзорная статья, которая и так получилась увесистой. И цель её — дать небольшое вступление. Про введение в алгоритмы можно так же прочитать ознакомиться с книгой "
Грокаем Алгоримы". Также мне нравится плэйлист от Jack Brown —
AQA Decision 1 1.01 Tracing an Algorithm. Ради интереса можно посмотреть на визуализацию алгоритмов на
sorting.at и
visualgo.net. Ну и весь Youtube к вашим услугам.









GO TO FULL VERSION