プログラミングの基礎に関するハーバード大学コースの講義 CS50 CS50 の課題、第 3 週、パート 1 CS50 の課題、第 3 週、パート 2
![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 1]() しかし、ある時点で二次関数が一次関数を追い越すことになるため、それを回避する方法はありません。もう 1 つの漸近複雑さは、対数時間、つまり O(log n) です。n が増加するにつれて、この関数は非常にゆっくりと増加します。O(log n) は、ソートされた配列における古典的な二分探索アルゴリズムの実行時間です (講義で破れた電話帳を覚えていますか?)。配列を2つに分割し、要素が存在する半分を選択するので、毎回探索範囲を半分に減らして要素を探索します。
しかし、ある時点で二次関数が一次関数を追い越すことになるため、それを回避する方法はありません。もう 1 つの漸近複雑さは、対数時間、つまり O(log n) です。n が増加するにつれて、この関数は非常にゆっくりと増加します。O(log n) は、ソートされた配列における古典的な二分探索アルゴリズムの実行時間です (講義で破れた電話帳を覚えていますか?)。配列を2つに分割し、要素が存在する半分を選択するので、毎回探索範囲を半分に減らして要素を探索します。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 2]() データ配列を初めて半分に分割して、探しているものをすぐに見つけたらどうなるでしょうか? 最高の時間を表す用語があります - オメガラージまたは Ω(n)。二分探索 = Ω(1) の場合 (配列のサイズに関係なく、一定時間で検索されます)。検索対象の要素が最初の要素である場合、線形検索は O(n) および Ω(1) 時間で実行されます。もう 1 つの記号はシータ (Θ(n)) です。最良の選択肢と最悪の選択肢が同じ場合に使用されます。これは、文字列の長さを別の変数に格納した例に適しているため、どのような長さであってもこの変数を参照するだけで十分です。このアルゴリズムの場合、最良のケースと最悪のケースはそれぞれ Ω(1) と O(1) です。これは、アルゴリズムが時間 Θ(1) で実行されることを意味します。
データ配列を初めて半分に分割して、探しているものをすぐに見つけたらどうなるでしょうか? 最高の時間を表す用語があります - オメガラージまたは Ω(n)。二分探索 = Ω(1) の場合 (配列のサイズに関係なく、一定時間で検索されます)。検索対象の要素が最初の要素である場合、線形検索は O(n) および Ω(1) 時間で実行されます。もう 1 つの記号はシータ (Θ(n)) です。最良の選択肢と最悪の選択肢が同じ場合に使用されます。これは、文字列の長さを別の変数に格納した例に適しているため、どのような長さであってもこの変数を参照するだけで十分です。このアルゴリズムの場合、最良のケースと最悪のケースはそれぞれ Ω(1) と O(1) です。これは、アルゴリズムが時間 Θ(1) で実行されることを意味します。
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 3]() LinearSearch 関数は、キー key と配列 array[] という 2 つの引数を入力として受け取ります。キーは目的の値であり、前の例では key = 0 です。配列は、我々が計算する数値のリストです。見ていきます。何も見つからなかった場合、関数は -1 (配列内に存在しない位置) を返します。線形検索で目的の要素が見つかった場合、関数は配列内で目的の要素が配置されている位置を返します。線形検索の良い点は、要素の順序に関係なく、どの配列でも機能することです。配列全体を調べます。これは彼の弱点でもあります。順番にソートされた 200 個の数値の配列から数値 198 を見つける必要がある場合、for ループは 198 ステップを実行します。
LinearSearch 関数は、キー key と配列 array[] という 2 つの引数を入力として受け取ります。キーは目的の値であり、前の例では key = 0 です。配列は、我々が計算する数値のリストです。見ていきます。何も見つからなかった場合、関数は -1 (配列内に存在しない位置) を返します。線形検索で目的の要素が見つかった場合、関数は配列内で目的の要素が配置されている位置を返します。線形検索の良い点は、要素の順序に関係なく、どの配列でも機能することです。配列全体を調べます。これは彼の弱点でもあります。順番にソートされた 200 個の数値の配列から数値 198 を見つける必要がある場合、for ループは 198 ステップを実行します。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 4]() おそらく、ソートされた配列にどの方法がより適しているかはすでに推測できたでしょうか?
おそらく、ソートされた配列にどの方法がより適しているかはすでに推測できたでしょうか?
![Java-университет]()
![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 5]() 直線的には長い時間がかかります。そして、「ディレクトリを半分に分割する方法」を使用すると、ジャスミンに直接アクセスでき、リストの前半を安全に破棄でき、そこにミッキーが存在しないことがわかります。
直線的には長い時間がかかります。そして、「ディレクトリを半分に分割する方法」を使用すると、ジャスミンに直接アクセスでき、リストの前半を安全に破棄でき、そこにミッキーが存在しないことがわかります。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 6]() 同じ原理を使用して、2 番目の列を破棄します。この戦略を続けると、ほんの数ステップでミッキーを見つけることができます。
同じ原理を使用して、2 番目の列を破棄します。この戦略を続けると、ほんの数ステップでミッキーを見つけることができます。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 7]() 数字 144 を見つけてみましょう。リストを半分に分割すると、数字 13 が得られます。探している数字が 13 より大きいか小さいかを評価します。13 < 144 なので、左側にあるものはすべて無視できます
数字 144 を見つけてみましょう。リストを半分に分割すると、数字 13 が得られます。探している数字が 13 より大きいか小さいかを評価します。13 < 144 なので、左側にあるものはすべて無視できます ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 8]() 。 13 とこの数字自体。検索リストは次のようになります。
。 13 とこの数字自体。検索リストは次のようになります。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 9]() 要素の数は偶数であるため、「中間」(先頭または末尾に近い) を選択する原則を選択します。最初に近接する戦略を選択したとしましょう。この場合、「中央」 = 55.
要素の数は偶数であるため、「中間」(先頭または末尾に近い) を選択する原則を選択します。最初に近接する戦略を選択したとしましょう。この場合、「中央」 = 55. ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 10]() 55 < 144 です。リストの左半分を再び破棄します。幸いなことに、次の平均値は 144 です。
55 < 144 です。リストの左半分を再び破棄します。幸いなことに、次の平均値は 144 です。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 11]() 二分探索を使用して、わずか 3 ステップで 13 要素の配列で 144 が見つかりました。線形検索では、同じ状況を最大 12 ステップで処理します。このアルゴリズムは各ステップで配列内の要素の数を半分に減らすため、漸近時間 O(log n) で必要な要素を見つけます (n はリスト内の要素の数です)。つまり、この場合、漸近時間 = O(log 13) (これは 3 より少し大きい) です。二分探索関数の疑似コード:
二分探索を使用して、わずか 3 ステップで 13 要素の配列で 144 が見つかりました。線形検索では、同じ状況を最大 12 ステップで処理します。このアルゴリズムは各ステップで配列内の要素の数を半分に減らすため、漸近時間 O(log n) で必要な要素を見つけます (n はリスト内の要素の数です)。つまり、この場合、漸近時間 = O(log 13) (これは 3 より少し大きい) です。二分探索関数の疑似コード: ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 12]() この関数は入力として 4 つの引数を取ります: 目的のキー、目的のキーが配置されているデータ配列 array []、min と max は配列内の最大値と最小値へのポインターです。私たちはアルゴリズムのこのステップを見ています。この例では、最初に次の図が示されていました。
この関数は入力として 4 つの引数を取ります: 目的のキー、目的のキーが配置されているデータ配列 array []、min と max は配列内の最大値と最小値へのポインターです。私たちはアルゴリズムのこのステップを見ています。この例では、最初に次の図が示されていました。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 13]() コードをさらに分析してみましょう。中間点は配列の中央です。それは極端な点に依存し、それらの間の中心にあります。中央を見つけたら、それがキー番号より小さいかどうかを確認します。
コードをさらに分析してみましょう。中間点は配列の中央です。それは極端な点に依存し、それらの間の中心にあります。中央を見つけたら、それがキー番号より小さいかどうかを確認します。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近表記、ソートおよび検索アルゴリズム - 14]() そうである場合、キーは中央より左側のどの数値よりも大きいので、min = 中間点 + 1 になるだけで、バイナリ関数を再度呼び出すことができます。キー < 中間点であることが判明した場合は、破棄できます。その番号自体と、彼の右側にあるすべての番号。そして、配列の最小値から値 (中点 – 1) までの二分探索を呼び出します。
そうである場合、キーは中央より左側のどの数値よりも大きいので、min = 中間点 + 1 になるだけで、バイナリ関数を再度呼び出すことができます。キー < 中間点であることが判明した場合は、破棄できます。その番号自体と、彼の右側にあるすべての番号。そして、配列の最小値から値 (中点 – 1) までの二分探索を呼び出します。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 15]() 最後に、3 番目の分岐: 中間点の値がキーよりも大きくも小さくもない場合、目的の数値にする以外に選択肢はありません。この場合、それを返してプログラムを終了します。
最後に、3 番目の分岐: 中間点の値がキーよりも大きくも小さくもない場合、目的の数値にする以外に選択肢はありません。この場合、それを返してプログラムを終了します。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 16]() 最後に、探している数値が配列にまったく存在しない場合もあります。このケースを考慮して、次のチェックを実行します。
最後に、探している数値が配列にまったく存在しない場合もあります。このケースを考慮して、次のチェックを実行します。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 17]() そして、何も見つからなかったことを示すために (-1) を返します。二分探索では配列をソートする必要があることはすでにご存知でしょう。したがって、特定の要素を見つける必要がある未ソートの配列がある場合、2 つのオプションがあります。
そして、何も見つからなかったことを示すために (-1) を返します。二分探索では配列をソートする必要があることはすでにご存知でしょう。したがって、特定の要素を見つける必要がある未ソートの配列がある場合、2 つのオプションがあります。
![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 18]() 注意: 「プログラマ」ツリーのルートは、実際のツリーとは異なり、一番上にあります。各セルは頂点と呼ばれ、頂点はエッジによって接続されます。ツリーのルートはセル番号 13 です。下の図では、頂点 3 の左側のサブツリーが色で強調表示されています。
注意: 「プログラマ」ツリーのルートは、実際のツリーとは異なり、一番上にあります。各セルは頂点と呼ばれ、頂点はエッジによって接続されます。ツリーのルートはセル番号 13 です。下の図では、頂点 3 の左側のサブツリーが色で強調表示されています。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 19]() 私たちのツリーは、バイナリ ツリーの要件をすべて満たしています。これは、左側のサブツリーのそれぞれには頂点の値以下の値のみが含まれ、右側のサブツリーには頂点の値以上の値のみが含まれていることを意味します。左と右のサブツリーは両方とも、それ自体バイナリ サブツリーです。二分木を構築する方法は唯一のものではありません。下の図では、同じ数値セットに対する別のオプションが示されていますが、実際には多数のオプションが存在する可能性があります。
私たちのツリーは、バイナリ ツリーの要件をすべて満たしています。これは、左側のサブツリーのそれぞれには頂点の値以下の値のみが含まれ、右側のサブツリーには頂点の値以上の値のみが含まれていることを意味します。左と右のサブツリーは両方とも、それ自体バイナリ サブツリーです。二分木を構築する方法は唯一のものではありません。下の図では、同じ数値セットに対する別のオプションが示されていますが、実際には多数のオプションが存在する可能性があります。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 20]() この構造は検索の実行に役立ちます。毎回上から左、下に移動して最小値を見つけます。
この構造は検索の実行に役立ちます。毎回上から左、下に移動して最小値を見つけます。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 21]() 最大数を見つける必要がある場合は、上から右に向かって進みます。最小値や最大値ではない数値を見つけることも非常に簡単です。探している頂点よりも大きいか小さいかに応じて、ルートから左または右に下降します。したがって、数値 89 を見つける必要がある場合は、次のパスをたどります。
最大数を見つける必要がある場合は、上から右に向かって進みます。最小値や最大値ではない数値を見つけることも非常に簡単です。探している頂点よりも大きいか小さいかに応じて、ルートから左または右に下降します。したがって、数値 89 を見つける必要がある場合は、次のパスをたどります。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 22]() 数値を並べ替え順に表示することもできます。たとえば、すべての数値を昇順で表示する必要がある場合は、左側のサブツリーを取得し、一番左の頂点から上に向かって表示します。ツリーに何かを追加するのも簡単です。覚えておきたいのは構造です。値 7 をツリーに追加する必要があるとします。ルートに移動して確認してみましょう。数字は 7 < 13 なので、左に進みます。
数値を並べ替え順に表示することもできます。たとえば、すべての数値を昇順で表示する必要がある場合は、左側のサブツリーを取得し、一番左の頂点から上に向かって表示します。ツリーに何かを追加するのも簡単です。覚えておきたいのは構造です。値 7 をツリーに追加する必要があるとします。ルートに移動して確認してみましょう。数字は 7 < 13 なので、左に進みます。![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 23]()
![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 24]() そこに 5 があり、7 > 5 であるため、右に進みます。さらに、7 > 8 および 8 には子孫がないため、8 から左への枝を構築し、それに 7 を接続します。また、頂点を削除することもできます。 ツリーですが、これはもう少し複雑です。考慮する必要がある削除シナリオは 3 つあります。
そこに 5 があり、7 > 5 であるため、右に進みます。さらに、7 > 8 および 8 には子孫がないため、8 から左への枝を構築し、それに 7 を接続します。また、頂点を削除することもできます。 ツリーですが、これはもう少し複雑です。考慮する必要がある削除シナリオは 3 つあります。
![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 26]() すべての数値は、前の数値の右側の分岐に単純に追加されます。数字を見つけたい場合は、単純にチェーンをたどっていく以外に選択肢はありません。
すべての数値は、前の数値の右側の分岐に単純に追加されます。数字を見つけたい場合は、単純にチェーンをたどっていく以外に選択肢はありません。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 27]() 線形検索に勝るものはありません。より複雑なデータ構造は他にもあります。しかし、今のところは考慮しません。ソートされたリストからツリーを構築する問題を解決するには、入力データをランダムに混合できるとだけ言っておきましょう。
線形検索に勝るものはありません。より複雑なデータ構造は他にもあります。しかし、今のところは考慮しません。ソートされたリストからツリーを構築する問題を解決するには、入力データをランダムに混合できるとだけ言っておきましょう。
![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 28]() 主なアイデアは、リストを並べ替え済みと並べ替えなしの 2 つの部分に分割することです。アルゴリズムの各ステップで、新しい数値が未ソート部分からソート済み部分に移動され、すべての数値がソート済み部分に収まるまで同様に移動されます。
主なアイデアは、リストを並べ替え済みと並べ替えなしの 2 つの部分に分割することです。アルゴリズムの各ステップで、新しい数値が未ソート部分からソート済み部分に移動され、すべての数値がソート済み部分に収まるまで同様に移動されます。
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 29]() 配列のソートされていない部分 (つまり、このステップでは配列全体) の最小値を見つけます。この数値は 2 です。次に、これをソートされていない配列の最初の数値に変更し、ソートされた配列の最後に置きます (このステップでは最初に)。このステップでは、これは配列内の最初の数値、つまり 3 です。
配列のソートされていない部分 (つまり、このステップでは配列全体) の最小値を見つけます。この数値は 2 です。次に、これをソートされていない配列の最初の数値に変更し、ソートされた配列の最後に置きます (このステップでは最初に)。このステップでは、これは配列内の最初の数値、つまり 3 です。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 30]() ステップ 2。数値 2 には注目しません。これはソートされた部分配列内にすでに存在します。2 番目の要素から始めて最小値を探し始めます。これは 5 です。3 が未ソートの最小値であり、5 が未ソートの最初の要素であることを確認します。それらを交換し、ソートされた部分配列に 3 を追加します。
ステップ 2。数値 2 には注目しません。これはソートされた部分配列内にすでに存在します。2 番目の要素から始めて最小値を探し始めます。これは 5 です。3 が未ソートの最小値であり、5 が未ソートの最初の要素であることを確認します。それらを交換し、ソートされた部分配列に 3 を追加します。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 31]() 3 番目のステップでは、ソートされていない部分配列の最小の数値が 4 であることがわかります。これを、ソートされていないものの最初の数値である 5 に変更します。4 番目のステップでは、ソートされていない配列の
3 番目のステップでは、ソートされていない部分配列の最小の数値が 4 であることがわかります。これを、ソートされていないものの最初の数値である 5 に変更します。4 番目のステップでは、ソートされていない配列の ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 32]() 最小の数値が 5 であることがわかります。これを 6 から変更し、ソートされた部分配列に追加します。
最小の数値が 5 であることがわかります。これを 6 から変更し、ソートされた部分配列に追加します。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 33]() ソートされていない数値の中に 1 つの数値 (最大の数値) だけが残っている場合、これは配列全体がソートされていることを意味します。
ソートされていない数値の中に 1 つの数値 (最大の数値) だけが残っている場合、これは配列全体がソートされていることを意味します。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 34]() コードでの配列の実装は次のようになります。自分で作ってみてください。
コードでの配列の実装は次のようになります。自分で作ってみてください。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 35]() 最良の場合も最悪の場合も、最小の未ソート要素を見つけるには、各要素を未ソートの配列の各要素と比較する必要があり、これを各反復で行います。ただし、リスト全体を表示する必要はなく、未分類の部分のみを表示する必要があります。これによりアルゴリズムの速度は変わりますか? 最初のステップでは、5 つの要素の配列に対して 4 つの比較を行い、2 番目では 3 回、3 番目では 2 回比較します。比較の数を取得するには、これらの数値をすべて合計する必要があります。合計が得られます
最良の場合も最悪の場合も、最小の未ソート要素を見つけるには、各要素を未ソートの配列の各要素と比較する必要があり、これを各反復で行います。ただし、リスト全体を表示する必要はなく、未分類の部分のみを表示する必要があります。これによりアルゴリズムの速度は変わりますか? 最初のステップでは、5 つの要素の配列に対して 4 つの比較を行い、2 番目では 3 回、3 番目では 2 回比較します。比較の数を取得するには、これらの数値をすべて合計する必要があります。合計が得られます ![式]() 。したがって、最良の場合と最悪の場合のアルゴリズムの期待速度は Θ(n 2 ) となります。最も効率的なアルゴリズムではありません。ただし、教育目的や小規模なデータ セットには十分適用できます。
。したがって、最良の場合と最悪の場合のアルゴリズムの期待速度は Θ(n 2 ) となります。最も効率的なアルゴリズムではありません。ただし、教育目的や小規模なデータ セットには十分適用できます。
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 36]() ステップ 1:配列を調べます。アルゴリズムは最初の 2 つの要素 8 と 6 から始まり、それらが正しい順序であるかどうかを確認します。8 > 6 なので、それらを交換します。次に 2 番目と 3 番目の要素を見てみましょう。これらは 8 と 4 です。同じ理由で、これらを入れ替えます。3 回目では、8 と 2 を比較します。合計で 3 つの交換 (8, 6)、(8, 4)、(8, 2) を行います。値 8 は、リストの末尾の正しい位置に「フローティング」されました。
ステップ 1:配列を調べます。アルゴリズムは最初の 2 つの要素 8 と 6 から始まり、それらが正しい順序であるかどうかを確認します。8 > 6 なので、それらを交換します。次に 2 番目と 3 番目の要素を見てみましょう。これらは 8 と 4 です。同じ理由で、これらを入れ替えます。3 回目では、8 と 2 を比較します。合計で 3 つの交換 (8, 6)、(8, 4)、(8, 2) を行います。値 8 は、リストの末尾の正しい位置に「フローティング」されました。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 37]() ステップ 2: (6,4) と (6,2) を交換します。6 は最後から 2 番目の位置にあるため、すでにソートされているリストの「末尾」と比較する必要はありません。
ステップ 2: (6,4) と (6,2) を交換します。6 は最後から 2 番目の位置にあるため、すでにソートされているリストの「末尾」と比較する必要はありません。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 38]() ステップ 3: 4 と 2 を交換します。4 つは適切な場所に「浮き上がり」ます。
ステップ 3: 4 と 2 を交換します。4 つは適切な場所に「浮き上がり」ます。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 39]() ステップ 4:配列を調べますが、何も変更する必要はありません。これは、配列が完全にソートされたことを示します。
ステップ 4:配列を調べますが、何も変更する必要はありません。これは、配列が完全にソートされたことを示します。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近表記、ソートおよび検索アルゴリズム - 40]() そしてこれがアルゴリズムのコードです。Cで実装してみよう! バブル ソートには最悪の場合 (すべての数値が間違っている場合)
そしてこれがアルゴリズムのコードです。Cで実装してみよう! バブル ソートには最悪の場合 (すべての数値が間違っている場合) ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 43]() O(n 2 ) 時間がかかります。これは、反復ごとに n ステップを実行する必要があり、そのうち n ステップも実行する必要があるためです。実際には、選択ソート アルゴリズムの場合と同様に、時間はわずかに短くなります (n 2 /2 – n/2) が、これは無視できます。最良の場合 (すべての要素がすでに配置されている場合)、n ステップ、つまり 3 つのステップで実行できます。Ω(n)。配列を 1 回反復処理して、すべての要素 (つまり、n-1 個の要素) が配置されていることを確認するだけで済みます。
O(n 2 ) 時間がかかります。これは、反復ごとに n ステップを実行する必要があり、そのうち n ステップも実行する必要があるためです。実際には、選択ソート アルゴリズムの場合と同様に、時間はわずかに短くなります (n 2 /2 – n/2) が、これは無視できます。最良の場合 (すべての要素がすでに配置されている場合)、n ステップ、つまり 3 つのステップで実行できます。Ω(n)。配列を 1 回反復処理して、すべての要素 (つまり、n-1 個の要素) が配置されていることを確認するだけで済みます。
![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 41]() 以下の例を使用して、挿入ソートがどのように機能するかを見てみましょう。開始する前に、すべての要素はソートされていないとみなされます。
以下の例を使用して、挿入ソートがどのように機能するかを見てみましょう。開始する前に、すべての要素はソートされていないとみなされます。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 42]() ステップ 1:最初のソートされていない値 (3) を取得し、それをソートされた部分配列に挿入します。このステップでは、ソートされた部分配列全体、その始まりと終わりはまさにこの 3 つになります。
ステップ 1:最初のソートされていない値 (3) を取得し、それをソートされた部分配列に挿入します。このステップでは、ソートされた部分配列全体、その始まりと終わりはまさにこの 3 つになります。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 43]() ステップ 2: 3 > 5 であるため、ソートされた部分配列の 3 の右側に 5 を挿入します。
ステップ 2: 3 > 5 であるため、ソートされた部分配列の 3 の右側に 5 を挿入します。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 44]() ステップ 3:次に、ソートされた配列に数値 2 を挿入します。2 を右から左の値と比較して、正しい位置を見つけます。2 < 5 および 2 < 3 なので、ソートされた部分配列の先頭に到達しました。したがって、3 の左側に 2 を挿入する必要があります。これを行うには、2 のためのスペースができるように 3 と 5 を右に移動し、配列の先頭に挿入します。
ステップ 3:次に、ソートされた配列に数値 2 を挿入します。2 を右から左の値と比較して、正しい位置を見つけます。2 < 5 および 2 < 3 なので、ソートされた部分配列の先頭に到達しました。したがって、3 の左側に 2 を挿入する必要があります。これを行うには、2 のためのスペースができるように 3 と 5 を右に移動し、配列の先頭に挿入します。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、並べ替えおよび検索アルゴリズム - 45]() ステップ 4.幸運なことに、6 > 5 なので、数字 5 の直後にその数字を挿入できます。
ステップ 4.幸運なことに、6 > 5 なので、数字 5 の直後にその数字を挿入できます。 ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 46]() ステップ 5. 4 < 6 および 4 < 5 ですが、4 > 3 です。したがって、4 を次の値に挿入する必要があることがわかります。 3 の右側です。ここでも、5 と 6 を右に移動して、4 のためのギャップを作成する必要があります
ステップ 5. 4 < 6 および 4 < 5 ですが、4 > 3 です。したがって、4 を次の値に挿入する必要があることがわかります。 3 の右側です。ここでも、5 と 6 を右に移動して、4 のためのギャップを作成する必要があります ![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 47]() 。完了です。一般化されたアルゴリズム: n のソートされていない各要素を取得し、n の適切な位置が見つかるまで (つまり、n 未満の最初の数値が見つかった瞬間)、それをソートされた部分配列内の値と右から左に比較します。 。次に、この数値の右側にあるソートされたすべての要素を右にシフトして、n 用のスペースを作り、そこに n を挿入します。これにより、配列のソートされた部分が拡張されます。ソートされていない要素 n ごとに、次のものが必要です。
。完了です。一般化されたアルゴリズム: n のソートされていない各要素を取得し、n の適切な位置が見つかるまで (つまり、n 未満の最初の数値が見つかった瞬間)、それをソートされた部分配列内の値と右から左に比較します。 。次に、この数値の右側にあるソートされたすべての要素を右にシフトして、n 用のスペースを作り、そこに n を挿入します。これにより、配列のソートされた部分が拡張されます。ソートされていない要素 n ごとに、次のものが必要です。
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 48]()
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 49]() 並べ替える要素が n 個あるとします。n < 2 の場合は並べ替えを終了します。そうでない場合は、配列の左部分と右部分を別々に並べ替えてから、それらを結合します。配列をソートしましょう。
並べ替える要素が n 個あるとします。n < 2 の場合は並べ替えを終了します。そうでない場合は、配列の左部分と右部分を別々に並べ替えてから、それらを結合します。配列をソートしましょう。 ![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 50]() 配列を 2 つの部分に分割し、明らかにソートされているサイズ 1 の部分配列が得られるまで分割を続けます。
配列を 2 つの部分に分割し、明らかにソートされているサイズ 1 の部分配列が得られるまで分割を続けます。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 51]() ソートされた 2 つの部分配列は、単純なアルゴリズムを使用して O(n) 時間でマージできます。各部分配列の先頭にある小さい数値を削除し、それをマージされた配列に挿入します。すべての要素がなくなるまで繰り返します。
ソートされた 2 つの部分配列は、単純なアルゴリズムを使用して O(n) 時間でマージできます。各部分配列の先頭にある小さい数値を削除し、それをマージされた配列に挿入します。すべての要素がなくなるまで繰り返します。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 52]()
![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 56]() マージソートにはすべてのケースで O(nlog n) 時間がかかります。各再帰レベルで配列を半分に分割すると、log n が得られます。この場合、部分配列のマージには n 回の比較のみが必要になります。したがって、O(nlog n)となります。マージ ソートの最良の場合と最悪の場合は同じで、アルゴリズムの予想実行時間 = Θ(nlog n) となります。このアルゴリズムは、検討されたアルゴリズムの中で最も効果的です。
マージソートにはすべてのケースで O(nlog n) 時間がかかります。各再帰レベルで配列を半分に分割すると、log n が得られます。この場合、部分配列のマージには n 回の比較のみが必要になります。したがって、O(nlog n)となります。マージ ソートの最良の場合と最悪の場合は同じで、アルゴリズムの予想実行時間 = Θ(nlog n) となります。このアルゴリズムは、検討されたアルゴリズムの中で最も効果的です。 ![CS50 追加資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 53]()
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 58]()
漸近表記
アルゴリズムの速度をリアルタイム (秒単位、分単位) で測定するのは簡単ではありません。あるプログラムが別のプログラムよりも遅くなるのは、そのプログラム自体の効率の悪さではなく、オペレーティング システムの遅さ、ハードウェアとの互換性のなさ、コンピュータ メモリが他のプロセスによって占有されていることが原因です。アルゴリズムの有効性を測定するために、普遍的な概念が発明されてきました。 、プログラムが実行されている環境に関係なく。問題の漸近的な複雑さは、Big O 表記法を使用して測定されます。f(x) と g(x) を x0 の近傍で定義された関数とし、g がそこで消滅しないとすると、定数 C> がある場合、f は (x -> x0) に対して g より「0」大きくなります。 0 、点 x0 の近傍からのすべての x について不等式が成り立つことを意味します。|f(x)| <= C |g(x)| 少し厳密ではありません: 定数 C>0 がある場合、f は g よりも「O」大きく、すべての x > x0 について f(x) <= C*g(x) 心配する必要はありません。正式な定義!基本的に、入力データの量が無限に向かって増加したときのプログラム実行時間の漸近的な増加を決定します。たとえば、1000 要素の配列の並べ替えと 10 要素の配列の並べ替えを比較している場合、プログラムの実行時間がどのように増加するかを理解する必要があります。または、文字列の長さを 1 文字ずつ計算し、各文字に 1 を加算する必要があります。 c - 1 a - 2 t - 3 漸近速度 = O(n) (n は単語内の文字数) となります。この原則に従ってカウントすると、行全体をカウントするのに必要な時間は文字数に比例します。20 文字の文字列の文字数を数えるには、10 文字の文字列の文字数を数えるのに比べて 2 倍の時間がかかります。文字列内の文字数に等しい値を長さ変数に格納したと想像してください。たとえば、length = 1000 です。文字列の長さを取得するには、この変数にアクセスするだけで済み、文字列自体を確認する必要さえありません。そして、長さをどのように変更しても、いつでもこの変数にアクセスできます。この場合、漸近速度 = O(1) となります。入力データを変更しても、このようなタスクの速度は変化せず、検索は一定の時間で完了します。この場合、プログラムは漸近的に一定になります。短所: 追加の変数を保存するためにコンピュータのメモリを無駄にし、その値を更新するために余分な時間を費やします。リニアタイムが悪いと思われる場合は、さらに悪くなる可能性があることを保証します。たとえば、O(n 2 )。この表記は、n が大きくなるにつれて、要素 (または別のアクション) を反復処理するのに必要な時間がますます急激に増加することを意味します。ただし、n が小さい場合、漸近速度 O(n 2 ) のアルゴリズムは、漸近速度 O(n) のアルゴリズムよりも高速に動作します。  しかし、ある時点で二次関数が一次関数を追い越すことになるため、それを回避する方法はありません。もう 1 つの漸近複雑さは、対数時間、つまり O(log n) です。n が増加するにつれて、この関数は非常にゆっくりと増加します。O(log n) は、ソートされた配列における古典的な二分探索アルゴリズムの実行時間です (講義で破れた電話帳を覚えていますか?)。配列を2つに分割し、要素が存在する半分を選択するので、毎回探索範囲を半分に減らして要素を探索します。
しかし、ある時点で二次関数が一次関数を追い越すことになるため、それを回避する方法はありません。もう 1 つの漸近複雑さは、対数時間、つまり O(log n) です。n が増加するにつれて、この関数は非常にゆっくりと増加します。O(log n) は、ソートされた配列における古典的な二分探索アルゴリズムの実行時間です (講義で破れた電話帳を覚えていますか?)。配列を2つに分割し、要素が存在する半分を選択するので、毎回探索範囲を半分に減らして要素を探索します。  データ配列を初めて半分に分割して、探しているものをすぐに見つけたらどうなるでしょうか? 最高の時間を表す用語があります - オメガラージまたは Ω(n)。二分探索 = Ω(1) の場合 (配列のサイズに関係なく、一定時間で検索されます)。検索対象の要素が最初の要素である場合、線形検索は O(n) および Ω(1) 時間で実行されます。もう 1 つの記号はシータ (Θ(n)) です。最良の選択肢と最悪の選択肢が同じ場合に使用されます。これは、文字列の長さを別の変数に格納した例に適しているため、どのような長さであってもこの変数を参照するだけで十分です。このアルゴリズムの場合、最良のケースと最悪のケースはそれぞれ Ω(1) と O(1) です。これは、アルゴリズムが時間 Θ(1) で実行されることを意味します。
データ配列を初めて半分に分割して、探しているものをすぐに見つけたらどうなるでしょうか? 最高の時間を表す用語があります - オメガラージまたは Ω(n)。二分探索 = Ω(1) の場合 (配列のサイズに関係なく、一定時間で検索されます)。検索対象の要素が最初の要素である場合、線形検索は O(n) および Ω(1) 時間で実行されます。もう 1 つの記号はシータ (Θ(n)) です。最良の選択肢と最悪の選択肢が同じ場合に使用されます。これは、文字列の長さを別の変数に格納した例に適しているため、どのような長さであってもこの変数を参照するだけで十分です。このアルゴリズムの場合、最良のケースと最悪のケースはそれぞれ Ω(1) と O(1) です。これは、アルゴリズムが時間 Θ(1) で実行されることを意味します。
線形探索
Web ブラウザを開いて、ページ、情報、ソーシャル ネットワーク上の友達を探すときは、店で適切な靴を見つけるときと同じように、検索を行っていることになります。おそらく、秩序が検索方法に大きな影響を与えることに気づいたでしょう。すべてのシャツがクローゼットにある場合は、通常、部屋中に散乱したシャツの中から必要なシャツを見つけるよりも、その中から必要なシャツを見つける方が簡単です。線形検索は、1 つずつ順番に検索する方法です。Google の検索結果を上から下まで確認すると、線形検索が使用されます。 例。数値のリストがあるとします。2 4 0 5 3 7 8 1 そして、0 を見つける必要があります。それはすぐにわかりますが、コンピューター プログラムはそのようには機能しません。彼女はリストの先頭から始めて、数字の 2 を確認します。次に、2=0 かどうかを確認します。そうではないので、彼女は続けて 2 番目の文字に進みます。そこでも失敗が彼女を待っており、アルゴリズムが必要な数を見つけるのは 3 番目の位置でのみです。線形検索の疑似コード:  LinearSearch 関数は、キー key と配列 array[] という 2 つの引数を入力として受け取ります。キーは目的の値であり、前の例では key = 0 です。配列は、我々が計算する数値のリストです。見ていきます。何も見つからなかった場合、関数は -1 (配列内に存在しない位置) を返します。線形検索で目的の要素が見つかった場合、関数は配列内で目的の要素が配置されている位置を返します。線形検索の良い点は、要素の順序に関係なく、どの配列でも機能することです。配列全体を調べます。これは彼の弱点でもあります。順番にソートされた 200 個の数値の配列から数値 198 を見つける必要がある場合、for ループは 198 ステップを実行します。
LinearSearch 関数は、キー key と配列 array[] という 2 つの引数を入力として受け取ります。キーは目的の値であり、前の例では key = 0 です。配列は、我々が計算する数値のリストです。見ていきます。何も見つからなかった場合、関数は -1 (配列内に存在しない位置) を返します。線形検索で目的の要素が見つかった場合、関数は配列内で目的の要素が配置されている位置を返します。線形検索の良い点は、要素の順序に関係なく、どの配列でも機能することです。配列全体を調べます。これは彼の弱点でもあります。順番にソートされた 200 個の数値の配列から数値 198 を見つける必要がある場合、for ループは 198 ステップを実行します。  おそらく、ソートされた配列にどの方法がより適しているかはすでに推測できたでしょうか?
おそらく、ソートされた配列にどの方法がより適しているかはすでに推測できたでしょうか?

二分探索とツリー
アルファベット順にソートされたディズニー キャラクターのリストがあり、ミッキー マウスを見つける必要があると想像してください。 直線的には長い時間がかかります。そして、「ディレクトリを半分に分割する方法」を使用すると、ジャスミンに直接アクセスでき、リストの前半を安全に破棄でき、そこにミッキーが存在しないことがわかります。
直線的には長い時間がかかります。そして、「ディレクトリを半分に分割する方法」を使用すると、ジャスミンに直接アクセスでき、リストの前半を安全に破棄でき、そこにミッキーが存在しないことがわかります。  同じ原理を使用して、2 番目の列を破棄します。この戦略を続けると、ほんの数ステップでミッキーを見つけることができます。
同じ原理を使用して、2 番目の列を破棄します。この戦略を続けると、ほんの数ステップでミッキーを見つけることができます。  数字 144 を見つけてみましょう。リストを半分に分割すると、数字 13 が得られます。探している数字が 13 より大きいか小さいかを評価します。13 < 144 なので、左側にあるものはすべて無視できます
数字 144 を見つけてみましょう。リストを半分に分割すると、数字 13 が得られます。探している数字が 13 より大きいか小さいかを評価します。13 < 144 なので、左側にあるものはすべて無視できます  。 13 とこの数字自体。検索リストは次のようになります。
。 13 とこの数字自体。検索リストは次のようになります。 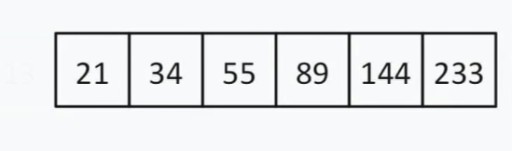 要素の数は偶数であるため、「中間」(先頭または末尾に近い) を選択する原則を選択します。最初に近接する戦略を選択したとしましょう。この場合、「中央」 = 55.
要素の数は偶数であるため、「中間」(先頭または末尾に近い) を選択する原則を選択します。最初に近接する戦略を選択したとしましょう。この場合、「中央」 = 55.  55 < 144 です。リストの左半分を再び破棄します。幸いなことに、次の平均値は 144 です。
55 < 144 です。リストの左半分を再び破棄します。幸いなことに、次の平均値は 144 です。  二分探索を使用して、わずか 3 ステップで 13 要素の配列で 144 が見つかりました。線形検索では、同じ状況を最大 12 ステップで処理します。このアルゴリズムは各ステップで配列内の要素の数を半分に減らすため、漸近時間 O(log n) で必要な要素を見つけます (n はリスト内の要素の数です)。つまり、この場合、漸近時間 = O(log 13) (これは 3 より少し大きい) です。二分探索関数の疑似コード:
二分探索を使用して、わずか 3 ステップで 13 要素の配列で 144 が見つかりました。線形検索では、同じ状況を最大 12 ステップで処理します。このアルゴリズムは各ステップで配列内の要素の数を半分に減らすため、漸近時間 O(log n) で必要な要素を見つけます (n はリスト内の要素の数です)。つまり、この場合、漸近時間 = O(log 13) (これは 3 より少し大きい) です。二分探索関数の疑似コード: 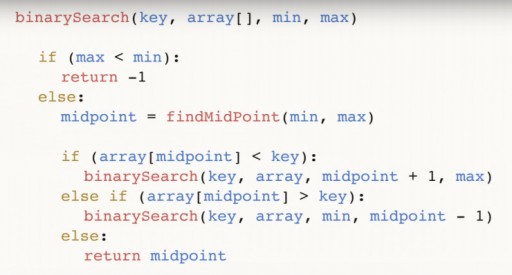 この関数は入力として 4 つの引数を取ります: 目的のキー、目的のキーが配置されているデータ配列 array []、min と max は配列内の最大値と最小値へのポインターです。私たちはアルゴリズムのこのステップを見ています。この例では、最初に次の図が示されていました。
この関数は入力として 4 つの引数を取ります: 目的のキー、目的のキーが配置されているデータ配列 array []、min と max は配列内の最大値と最小値へのポインターです。私たちはアルゴリズムのこのステップを見ています。この例では、最初に次の図が示されていました。  コードをさらに分析してみましょう。中間点は配列の中央です。それは極端な点に依存し、それらの間の中心にあります。中央を見つけたら、それがキー番号より小さいかどうかを確認します。
コードをさらに分析してみましょう。中間点は配列の中央です。それは極端な点に依存し、それらの間の中心にあります。中央を見つけたら、それがキー番号より小さいかどうかを確認します。  そうである場合、キーは中央より左側のどの数値よりも大きいので、min = 中間点 + 1 になるだけで、バイナリ関数を再度呼び出すことができます。キー < 中間点であることが判明した場合は、破棄できます。その番号自体と、彼の右側にあるすべての番号。そして、配列の最小値から値 (中点 – 1) までの二分探索を呼び出します。
そうである場合、キーは中央より左側のどの数値よりも大きいので、min = 中間点 + 1 になるだけで、バイナリ関数を再度呼び出すことができます。キー < 中間点であることが判明した場合は、破棄できます。その番号自体と、彼の右側にあるすべての番号。そして、配列の最小値から値 (中点 – 1) までの二分探索を呼び出します。  最後に、3 番目の分岐: 中間点の値がキーよりも大きくも小さくもない場合、目的の数値にする以外に選択肢はありません。この場合、それを返してプログラムを終了します。
最後に、3 番目の分岐: 中間点の値がキーよりも大きくも小さくもない場合、目的の数値にする以外に選択肢はありません。この場合、それを返してプログラムを終了します。  最後に、探している数値が配列にまったく存在しない場合もあります。このケースを考慮して、次のチェックを実行します。
最後に、探している数値が配列にまったく存在しない場合もあります。このケースを考慮して、次のチェックを実行します。  そして、何も見つからなかったことを示すために (-1) を返します。二分探索では配列をソートする必要があることはすでにご存知でしょう。したがって、特定の要素を見つける必要がある未ソートの配列がある場合、2 つのオプションがあります。
そして、何も見つからなかったことを示すために (-1) を返します。二分探索では配列をソートする必要があることはすでにご存知でしょう。したがって、特定の要素を見つける必要がある未ソートの配列がある場合、2 つのオプションがあります。
- リストを並べ替えて二分探索を適用する
- リストを常に並べ替えながら、リストに要素を追加したり削除したりすることもできます。
- これはツリーです (ツリー構造をエミュレートするデータ構造 - ルートと他のノード (葉) が「枝」またはサイクルのないエッジで接続されています)
- 各ノードには 0、1、または 2 つの子があります
- 左右のサブツリーは両方とも二分探索ツリーです。
- 任意のノード X の左側のサブツリーのすべてのノードは、ノード X 自体のデータ キーの値よりも小さいデータ キー値を持ちます。
- 任意のノード X の右側のサブツリー内のすべてのノードは、ノード X 自体のデータ キーの値以上のデータ キー値を持ちます。
 注意: 「プログラマ」ツリーのルートは、実際のツリーとは異なり、一番上にあります。各セルは頂点と呼ばれ、頂点はエッジによって接続されます。ツリーのルートはセル番号 13 です。下の図では、頂点 3 の左側のサブツリーが色で強調表示されています。
注意: 「プログラマ」ツリーのルートは、実際のツリーとは異なり、一番上にあります。各セルは頂点と呼ばれ、頂点はエッジによって接続されます。ツリーのルートはセル番号 13 です。下の図では、頂点 3 の左側のサブツリーが色で強調表示されています。 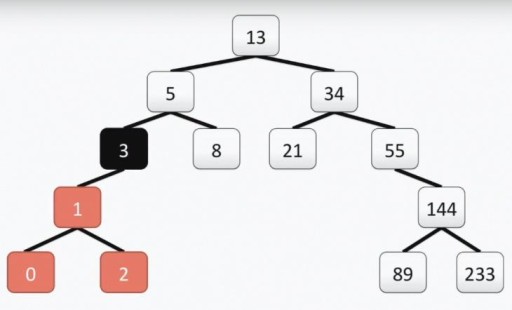 私たちのツリーは、バイナリ ツリーの要件をすべて満たしています。これは、左側のサブツリーのそれぞれには頂点の値以下の値のみが含まれ、右側のサブツリーには頂点の値以上の値のみが含まれていることを意味します。左と右のサブツリーは両方とも、それ自体バイナリ サブツリーです。二分木を構築する方法は唯一のものではありません。下の図では、同じ数値セットに対する別のオプションが示されていますが、実際には多数のオプションが存在する可能性があります。
私たちのツリーは、バイナリ ツリーの要件をすべて満たしています。これは、左側のサブツリーのそれぞれには頂点の値以下の値のみが含まれ、右側のサブツリーには頂点の値以上の値のみが含まれていることを意味します。左と右のサブツリーは両方とも、それ自体バイナリ サブツリーです。二分木を構築する方法は唯一のものではありません。下の図では、同じ数値セットに対する別のオプションが示されていますが、実際には多数のオプションが存在する可能性があります。  この構造は検索の実行に役立ちます。毎回上から左、下に移動して最小値を見つけます。
この構造は検索の実行に役立ちます。毎回上から左、下に移動して最小値を見つけます。 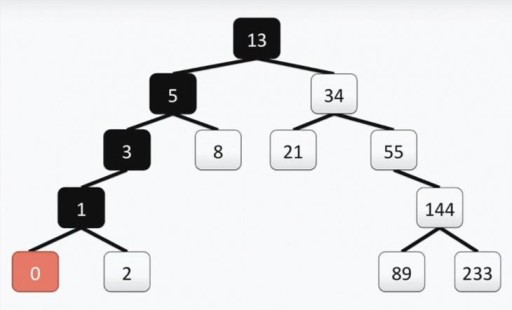 最大数を見つける必要がある場合は、上から右に向かって進みます。最小値や最大値ではない数値を見つけることも非常に簡単です。探している頂点よりも大きいか小さいかに応じて、ルートから左または右に下降します。したがって、数値 89 を見つける必要がある場合は、次のパスをたどります。
最大数を見つける必要がある場合は、上から右に向かって進みます。最小値や最大値ではない数値を見つけることも非常に簡単です。探している頂点よりも大きいか小さいかに応じて、ルートから左または右に下降します。したがって、数値 89 を見つける必要がある場合は、次のパスをたどります。  数値を並べ替え順に表示することもできます。たとえば、すべての数値を昇順で表示する必要がある場合は、左側のサブツリーを取得し、一番左の頂点から上に向かって表示します。ツリーに何かを追加するのも簡単です。覚えておきたいのは構造です。値 7 をツリーに追加する必要があるとします。ルートに移動して確認してみましょう。数字は 7 < 13 なので、左に進みます。
数値を並べ替え順に表示することもできます。たとえば、すべての数値を昇順で表示する必要がある場合は、左側のサブツリーを取得し、一番左の頂点から上に向かって表示します。ツリーに何かを追加するのも簡単です。覚えておきたいのは構造です。値 7 をツリーに追加する必要があるとします。ルートに移動して確認してみましょう。数字は 7 < 13 なので、左に進みます。
 そこに 5 があり、7 > 5 であるため、右に進みます。さらに、7 > 8 および 8 には子孫がないため、8 から左への枝を構築し、それに 7 を接続します。また、頂点を削除することもできます。 ツリーですが、これはもう少し複雑です。考慮する必要がある削除シナリオは 3 つあります。
そこに 5 があり、7 > 5 であるため、右に進みます。さらに、7 > 8 および 8 には子孫がないため、8 から左への枝を構築し、それに 7 を接続します。また、頂点を削除することもできます。 ツリーですが、これはもう少し複雑です。考慮する必要がある削除シナリオは 3 つあります。
- 最も単純なオプション: 子のない頂点を削除する必要があります。たとえば、先ほど追加した数字の 7 です。この場合、単にこの番号の頂点までのパスをたどって削除します。
- 頂点には 1 つの子頂点があります。この場合、目的の頂点を削除できますが、その子孫は「祖父」、つまり直接の祖先が発生した頂点に接続されている必要があります。たとえば、同じツリーから数値 3 を削除する必要があります。この場合、その子孫である 1 をサブツリー全体とともに 5 に結合します。5 の左側にあるすべての頂点は次のとおりになるため、これは簡単に行われます。この数値よりも小さい (およびリモートの 3 倍よりも小さい)。
![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 24]()
- 最も困難なケースは、削除される頂点に 2 つの子がある場合です。ここで最初に行う必要があるのは、次に大きい値が隠されている頂点を見つけて、それらを交換してから、目的の頂点を削除することです。次に高い値の頂点は 2 つの子を持つことができないことに注意してください。その場合、その左側の子が次の値の最良の候補になります。ツリーからルート ノード 13 を削除しましょう。まず、13 に最も近い、それより大きい数値を探します。これは 21 です。21 と 13 を交換し、13 を削除します。
![追加資料 CS50 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 25]()
![CS50 補足資料 (第 3 週、講義 7 および 8): 漸近記法、ソートおよび検索アルゴリズム - 27]()



 すべての数値は、前の数値の右側の分岐に単純に追加されます。数字を見つけたい場合は、単純にチェーンをたどっていく以外に選択肢はありません。
すべての数値は、前の数値の右側の分岐に単純に追加されます。数字を見つけたい場合は、単純にチェーンをたどっていく以外に選択肢はありません。  線形検索に勝るものはありません。より複雑なデータ構造は他にもあります。しかし、今のところは考慮しません。ソートされたリストからツリーを構築する問題を解決するには、入力データをランダムに混合できるとだけ言っておきましょう。
線形検索に勝るものはありません。より複雑なデータ構造は他にもあります。しかし、今のところは考慮しません。ソートされたリストからツリーを構築する問題を解決するには、入力データをランダムに混合できるとだけ言っておきましょう。
並べ替えアルゴリズム
数字の配列があります。それを整理する必要があります。簡単にするために、整数を昇順 (最小値から最大値へ) に並べ替えていると仮定します。このプロセスを実行するにはいくつかの既知の方法があります。さらに、いつでもトピックを考え出し、アルゴリズムの修正を思いつくことができます。選択による並べ替え
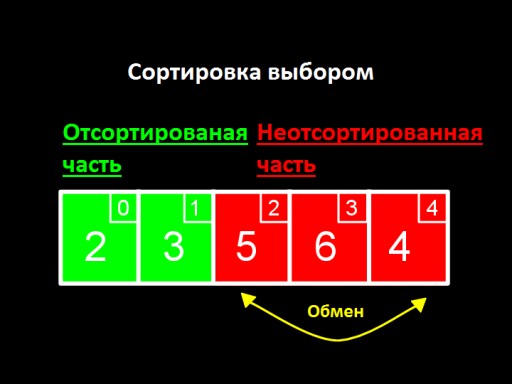 主なアイデアは、リストを並べ替え済みと並べ替えなしの 2 つの部分に分割することです。アルゴリズムの各ステップで、新しい数値が未ソート部分からソート済み部分に移動され、すべての数値がソート済み部分に収まるまで同様に移動されます。
主なアイデアは、リストを並べ替え済みと並べ替えなしの 2 つの部分に分割することです。アルゴリズムの各ステップで、新しい数値が未ソート部分からソート済み部分に移動され、すべての数値がソート済み部分に収まるまで同様に移動されます。
- ソートされていない最小値を見つけます。
- この値をソートされていない最初の値と交換し、ソートされた配列の最後に配置します。
- 未ソートの値が残っている場合は、手順 1 に戻ります。
 配列のソートされていない部分 (つまり、このステップでは配列全体) の最小値を見つけます。この数値は 2 です。次に、これをソートされていない配列の最初の数値に変更し、ソートされた配列の最後に置きます (このステップでは最初に)。このステップでは、これは配列内の最初の数値、つまり 3 です。
配列のソートされていない部分 (つまり、このステップでは配列全体) の最小値を見つけます。この数値は 2 です。次に、これをソートされていない配列の最初の数値に変更し、ソートされた配列の最後に置きます (このステップでは最初に)。このステップでは、これは配列内の最初の数値、つまり 3 です。  ステップ 2。数値 2 には注目しません。これはソートされた部分配列内にすでに存在します。2 番目の要素から始めて最小値を探し始めます。これは 5 です。3 が未ソートの最小値であり、5 が未ソートの最初の要素であることを確認します。それらを交換し、ソートされた部分配列に 3 を追加します。
ステップ 2。数値 2 には注目しません。これはソートされた部分配列内にすでに存在します。2 番目の要素から始めて最小値を探し始めます。これは 5 です。3 が未ソートの最小値であり、5 が未ソートの最初の要素であることを確認します。それらを交換し、ソートされた部分配列に 3 を追加します。  3 番目のステップでは、ソートされていない部分配列の最小の数値が 4 であることがわかります。これを、ソートされていないものの最初の数値である 5 に変更します。4 番目のステップでは、ソートされていない配列の
3 番目のステップでは、ソートされていない部分配列の最小の数値が 4 であることがわかります。これを、ソートされていないものの最初の数値である 5 に変更します。4 番目のステップでは、ソートされていない配列の  最小の数値が 5 であることがわかります。これを 6 から変更し、ソートされた部分配列に追加します。
最小の数値が 5 であることがわかります。これを 6 から変更し、ソートされた部分配列に追加します。 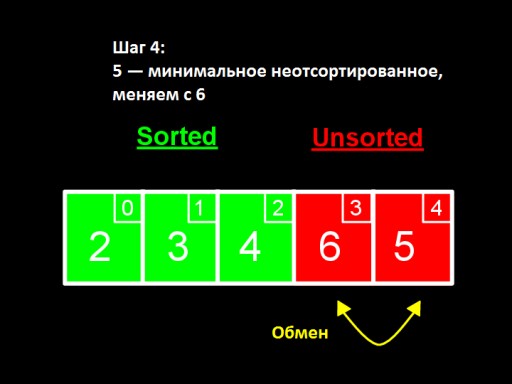 ソートされていない数値の中に 1 つの数値 (最大の数値) だけが残っている場合、これは配列全体がソートされていることを意味します。
ソートされていない数値の中に 1 つの数値 (最大の数値) だけが残っている場合、これは配列全体がソートされていることを意味します。 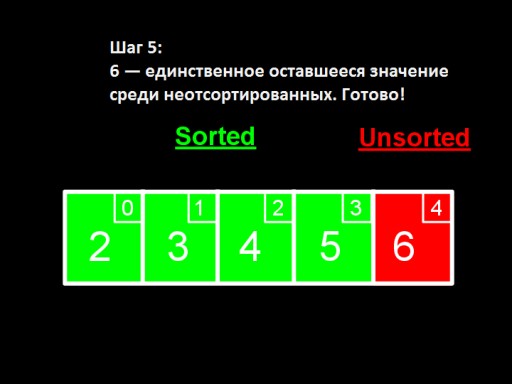 コードでの配列の実装は次のようになります。自分で作ってみてください。
コードでの配列の実装は次のようになります。自分で作ってみてください。  最良の場合も最悪の場合も、最小の未ソート要素を見つけるには、各要素を未ソートの配列の各要素と比較する必要があり、これを各反復で行います。ただし、リスト全体を表示する必要はなく、未分類の部分のみを表示する必要があります。これによりアルゴリズムの速度は変わりますか? 最初のステップでは、5 つの要素の配列に対して 4 つの比較を行い、2 番目では 3 回、3 番目では 2 回比較します。比較の数を取得するには、これらの数値をすべて合計する必要があります。合計が得られます
最良の場合も最悪の場合も、最小の未ソート要素を見つけるには、各要素を未ソートの配列の各要素と比較する必要があり、これを各反復で行います。ただし、リスト全体を表示する必要はなく、未分類の部分のみを表示する必要があります。これによりアルゴリズムの速度は変わりますか? 最初のステップでは、5 つの要素の配列に対して 4 つの比較を行い、2 番目では 3 回、3 番目では 2 回比較します。比較の数を取得するには、これらの数値をすべて合計する必要があります。合計が得られます  。したがって、最良の場合と最悪の場合のアルゴリズムの期待速度は Θ(n 2 ) となります。最も効率的なアルゴリズムではありません。ただし、教育目的や小規模なデータ セットには十分適用できます。
。したがって、最良の場合と最悪の場合のアルゴリズムの期待速度は Θ(n 2 ) となります。最も効率的なアルゴリズムではありません。ただし、教育目的や小規模なデータ セットには十分適用できます。
バブルソート
バブル ソート アルゴリズムは、最も単純なアルゴリズムの 1 つです。配列全体に沿って、隣接する 2 つの要素を比較します。順番が間違っている場合は交換させていただきます。最初のパスでは、最小の要素 (「float」) が最後に表示されます (降順でソートした場合)。前のステップで少なくとも 1 つの交換が完了した場合は、最初のステップを繰り返します。配列を並べ替えてみましょう。 ステップ 1:配列を調べます。アルゴリズムは最初の 2 つの要素 8 と 6 から始まり、それらが正しい順序であるかどうかを確認します。8 > 6 なので、それらを交換します。次に 2 番目と 3 番目の要素を見てみましょう。これらは 8 と 4 です。同じ理由で、これらを入れ替えます。3 回目では、8 と 2 を比較します。合計で 3 つの交換 (8, 6)、(8, 4)、(8, 2) を行います。値 8 は、リストの末尾の正しい位置に「フローティング」されました。
ステップ 1:配列を調べます。アルゴリズムは最初の 2 つの要素 8 と 6 から始まり、それらが正しい順序であるかどうかを確認します。8 > 6 なので、それらを交換します。次に 2 番目と 3 番目の要素を見てみましょう。これらは 8 と 4 です。同じ理由で、これらを入れ替えます。3 回目では、8 と 2 を比較します。合計で 3 つの交換 (8, 6)、(8, 4)、(8, 2) を行います。値 8 は、リストの末尾の正しい位置に「フローティング」されました。  ステップ 2: (6,4) と (6,2) を交換します。6 は最後から 2 番目の位置にあるため、すでにソートされているリストの「末尾」と比較する必要はありません。
ステップ 2: (6,4) と (6,2) を交換します。6 は最後から 2 番目の位置にあるため、すでにソートされているリストの「末尾」と比較する必要はありません。  ステップ 3: 4 と 2 を交換します。4 つは適切な場所に「浮き上がり」ます。
ステップ 3: 4 と 2 を交換します。4 つは適切な場所に「浮き上がり」ます。  ステップ 4:配列を調べますが、何も変更する必要はありません。これは、配列が完全にソートされたことを示します。
ステップ 4:配列を調べますが、何も変更する必要はありません。これは、配列が完全にソートされたことを示します。 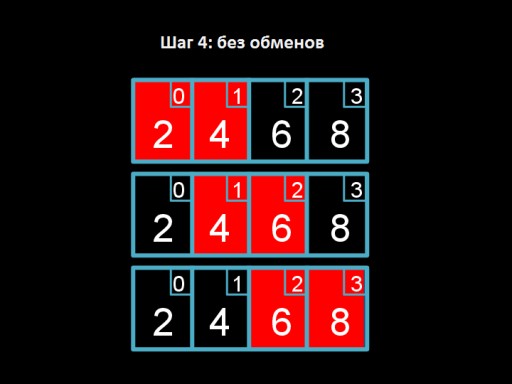 そしてこれがアルゴリズムのコードです。Cで実装してみよう! バブル ソートには最悪の場合 (すべての数値が間違っている場合)
そしてこれがアルゴリズムのコードです。Cで実装してみよう! バブル ソートには最悪の場合 (すべての数値が間違っている場合)  O(n 2 ) 時間がかかります。これは、反復ごとに n ステップを実行する必要があり、そのうち n ステップも実行する必要があるためです。実際には、選択ソート アルゴリズムの場合と同様に、時間はわずかに短くなります (n 2 /2 – n/2) が、これは無視できます。最良の場合 (すべての要素がすでに配置されている場合)、n ステップ、つまり 3 つのステップで実行できます。Ω(n)。配列を 1 回反復処理して、すべての要素 (つまり、n-1 個の要素) が配置されていることを確認するだけで済みます。
O(n 2 ) 時間がかかります。これは、反復ごとに n ステップを実行する必要があり、そのうち n ステップも実行する必要があるためです。実際には、選択ソート アルゴリズムの場合と同様に、時間はわずかに短くなります (n 2 /2 – n/2) が、これは無視できます。最良の場合 (すべての要素がすでに配置されている場合)、n ステップ、つまり 3 つのステップで実行できます。Ω(n)。配列を 1 回反復処理して、すべての要素 (つまり、n-1 個の要素) が配置されていることを確認するだけで済みます。
挿入ソート
このアルゴリズムの主なアイデアは、配列をソートされた部分とソートされていない部分の 2 つの部分に分割することです。アルゴリズムの各ステップで、数値は未ソート部分からソート済み部分に移動します。 以下の例を使用して、挿入ソートがどのように機能するかを見てみましょう。開始する前に、すべての要素はソートされていないとみなされます。
以下の例を使用して、挿入ソートがどのように機能するかを見てみましょう。開始する前に、すべての要素はソートされていないとみなされます。  ステップ 1:最初のソートされていない値 (3) を取得し、それをソートされた部分配列に挿入します。このステップでは、ソートされた部分配列全体、その始まりと終わりはまさにこの 3 つになります。
ステップ 1:最初のソートされていない値 (3) を取得し、それをソートされた部分配列に挿入します。このステップでは、ソートされた部分配列全体、その始まりと終わりはまさにこの 3 つになります。  ステップ 2: 3 > 5 であるため、ソートされた部分配列の 3 の右側に 5 を挿入します。
ステップ 2: 3 > 5 であるため、ソートされた部分配列の 3 の右側に 5 を挿入します。  ステップ 3:次に、ソートされた配列に数値 2 を挿入します。2 を右から左の値と比較して、正しい位置を見つけます。2 < 5 および 2 < 3 なので、ソートされた部分配列の先頭に到達しました。したがって、3 の左側に 2 を挿入する必要があります。これを行うには、2 のためのスペースができるように 3 と 5 を右に移動し、配列の先頭に挿入します。
ステップ 3:次に、ソートされた配列に数値 2 を挿入します。2 を右から左の値と比較して、正しい位置を見つけます。2 < 5 および 2 < 3 なので、ソートされた部分配列の先頭に到達しました。したがって、3 の左側に 2 を挿入する必要があります。これを行うには、2 のためのスペースができるように 3 と 5 を右に移動し、配列の先頭に挿入します。  ステップ 4.幸運なことに、6 > 5 なので、数字 5 の直後にその数字を挿入できます。
ステップ 4.幸運なことに、6 > 5 なので、数字 5 の直後にその数字を挿入できます。  ステップ 5. 4 < 6 および 4 < 5 ですが、4 > 3 です。したがって、4 を次の値に挿入する必要があることがわかります。 3 の右側です。ここでも、5 と 6 を右に移動して、4 のためのギャップを作成する必要があります
ステップ 5. 4 < 6 および 4 < 5 ですが、4 > 3 です。したがって、4 を次の値に挿入する必要があることがわかります。 3 の右側です。ここでも、5 と 6 を右に移動して、4 のためのギャップを作成する必要があります  。完了です。一般化されたアルゴリズム: n のソートされていない各要素を取得し、n の適切な位置が見つかるまで (つまり、n 未満の最初の数値が見つかった瞬間)、それをソートされた部分配列内の値と右から左に比較します。 。次に、この数値の右側にあるソートされたすべての要素を右にシフトして、n 用のスペースを作り、そこに n を挿入します。これにより、配列のソートされた部分が拡張されます。ソートされていない要素 n ごとに、次のものが必要です。
。完了です。一般化されたアルゴリズム: n のソートされていない各要素を取得し、n の適切な位置が見つかるまで (つまり、n 未満の最初の数値が見つかった瞬間)、それをソートされた部分配列内の値と右から左に比較します。 。次に、この数値の右側にあるソートされたすべての要素を右にシフトして、n 用のスペースを作り、そこに n を挿入します。これにより、配列のソートされた部分が拡張されます。ソートされていない要素 n ごとに、次のものが必要です。
- 配列のソートされた部分内で n を挿入する位置を決定します。
- ソートされた要素を右にシフトして n 分のギャップを作成します
- 配列のソートされた部分の結果のギャップに n を挿入します。

アルゴリズムの漸近速度
最悪の場合、2 番目の要素と 1 回の比較、3 番目の要素と 2 回の比較を行うことになります。したがって、速度は O(n 2 ) です。せいぜい、すでにソート済みの配列を操作することになります。要素の挿入や移動を行わずに左から右に構築するソートされた部分には、Ω(n) の時間がかかります。マージソート
このアルゴリズムは再帰的であり、1 つの大きな並べ替え問題をサブタスクに分割し、サブタスクを実行すると元の大きな問題の解決に近づきます。主なアイデアは、ソートされていない配列を 2 つの部分に分割し、それぞれの半分を再帰的にソートすることです。 並べ替える要素が n 個あるとします。n < 2 の場合は並べ替えを終了します。そうでない場合は、配列の左部分と右部分を別々に並べ替えてから、それらを結合します。配列をソートしましょう。
並べ替える要素が n 個あるとします。n < 2 の場合は並べ替えを終了します。そうでない場合は、配列の左部分と右部分を別々に並べ替えてから、それらを結合します。配列をソートしましょう。  配列を 2 つの部分に分割し、明らかにソートされているサイズ 1 の部分配列が得られるまで分割を続けます。
配列を 2 つの部分に分割し、明らかにソートされているサイズ 1 の部分配列が得られるまで分割を続けます。  ソートされた 2 つの部分配列は、単純なアルゴリズムを使用して O(n) 時間でマージできます。各部分配列の先頭にある小さい数値を削除し、それをマージされた配列に挿入します。すべての要素がなくなるまで繰り返します。
ソートされた 2 つの部分配列は、単純なアルゴリズムを使用して O(n) 時間でマージできます。各部分配列の先頭にある小さい数値を削除し、それをマージされた配列に挿入します。すべての要素がなくなるまで繰り返します。 
 マージソートにはすべてのケースで O(nlog n) 時間がかかります。各再帰レベルで配列を半分に分割すると、log n が得られます。この場合、部分配列のマージには n 回の比較のみが必要になります。したがって、O(nlog n)となります。マージ ソートの最良の場合と最悪の場合は同じで、アルゴリズムの予想実行時間 = Θ(nlog n) となります。このアルゴリズムは、検討されたアルゴリズムの中で最も効果的です。
マージソートにはすべてのケースで O(nlog n) 時間がかかります。各再帰レベルで配列を半分に分割すると、log n が得られます。この場合、部分配列のマージには n 回の比較のみが必要になります。したがって、O(nlog n)となります。マージ ソートの最良の場合と最悪の場合は同じで、アルゴリズムの予想実行時間 = Θ(nlog n) となります。このアルゴリズムは、検討されたアルゴリズムの中で最も効果的です。 

GO TO FULL VERSION