97. 等しいを再定義するときに、合意の再定義条件が課されますか?
オーバーライドされたequals()メソッドは、次の条件(ルール)に従う必要があります。-
再帰性- 任意の値x に対して、x.equals(x)のような式は常にtrueを返す必要があります( x != nullの場合)。
-
対称性- xとyの任意の値について、 x.equals(y)形式の式は、y.equals(x) がtrueを返す場合にのみtrueを返す必要があります。
-
推移性- x、y、zの任意の値について、x.equals(y)がtrueを返し、y.equals(z)もtrueを返す場合、x.equals(z) はtrueを返さなければなりません。
-
一貫性- xとyの任意の値について、 x.equals(y)を繰り返し呼び出すと、2 つのオブジェクトの比較に使用されるフィールドが呼び出し間で変更されていない限り、常にこのメソッドへの前回の呼び出しの値が返されます。 。
-
比較 null - 任意の値x に対して、x.equals(null)を呼び出すとfalseが返されます。
98. Equals と HashCode をオーバーライドしないとどうなりますか?
この場合、hashCode() は、指定されたオブジェクトが格納されているメモリ位置に基づいて生成された数値を返します。つまり、まったく同じフィールドを持つ 2 つのオブジェクトは、オーバーライドされていないhashCode()を呼び出すときに異なる値を受け取ります(結局のところ、それらは異なるメモリ場所に格納されます)。オーバーライドされていないequals()は、参照を比較して、参照が同じオブジェクトを指しているかどうかを確認します。つまり、比較は==によって行われ、同じフィールドを持つオブジェクトの場合は常にfalseを返します。同じオブジェクトへの参照を比較する場合にのみTrueになります。これらのメソッドをオーバーライドしない方が合理的な場合もあります。たとえば、特定のクラスのすべてのオブジェクトを一意にしたい場合、これらのメソッドをオーバーライドしても一意性のロジックが損なわれるだけです。重要なことは、オーバーライドされたメソッドとオーバーライドされていないメソッドのニュアンスを理解し、状況に応じて両方のアプローチを使用することです。99. x.equals(y) が true を返す場合にのみ対称性が true になるのはなぜですか?
ちょっと奇妙な質問です。オブジェクト A がオブジェクト B と等しい場合、オブジェクト B はオブジェクト A と等しいです。B がオブジェクト A と等しくない場合、その逆はどのようにして可能でしょうか? これは単純なロジックです。
100. ハッシュコードにおける衝突とは何ですか? どうやって対処すればいいのでしょうか?
ハッシュコードの衝突とは、2 つの異なるオブジェクトが同じハッシュコード値を持つ状況です。これはどのようにして可能でしょうか? 実際、ハッシュコードはInteger型にマップされており、その範囲は -2147483648 から 2147483647 まで、つまり約 40 億の異なる整数になります。この範囲は非常に広いですが、無限ではありません。したがって、2 つのまったく異なるオブジェクトが同じハッシュ コードを持つ状況が発生する可能性があります。これは非常に可能性は低いですが、可能性はあります。ハッシュ関数が適切に実装されていないと、同一のハッシュ コードの頻度が増加する可能性があります。たとえば、狭い範囲の数値が返されるため、衝突の可能性が高くなります。衝突に対処するには、値の広がりを最大にし、値が繰り返される可能性を最小限に抑えるために、 hashCodeメソッドを適切に実装する必要があります。
101. HashCode コントラクトに参加している要素の値が変更された場合はどうなりますか?
ハッシュ コードの計算に関与する要素が変更された場合、オブジェクト自体のハッシュ コードも変更されます (ハッシュ関数が良好な場合)。したがって、HashMapでは、作成後に内部状態 (フィールド) を変更できないため、不変 (変更不可能) オブジェクトをキーとして使用することをお勧めします。したがって、作成後のハッシュコードも変換されません。可変オブジェクトをキーとして使用する場合、このオブジェクトのフィールドを変更すると、そのハッシュ コードが変更され、その結果、HashMap内のこのペアが失われる可能性があります。結局、元のハッシュコードのバケットに保存され、変更後は別のバケットで検索されることになります。
102. String name フィールドと int age フィールドで構成される Student クラスの Equals メソッドと HashCode メソッドを作成します。
public class Student {
int age;
String name;
@Override
public boolean equals(final Object o) {
if (this == o) {
return true;
}
if (o == null || this.getClass() != o.getClass()) {
return false;
}
final Student student = (Student) o;
if (this.age != student.age) {
return false;
}
return this.name != null ? this.name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = this.age;
result = 31 * result + (this.name != null ? this.name.hashCode() : 0);
return result;
}
}-
まず、リンクを直接比較します。リンクが同じオブジェクトへのリンクである場合、チェックを続行する意味はありません。とにかくすべてが真実になります。
-
null と一致するクラス型をチェックします。オブジェクトが null または別の型の引数である場合、オブジェクトが等しくないことを意味するため、falseになります。
-
引数オブジェクトを 1 つの型にキャストします (親型のオブジェクトの場合)。
-
プリミティブ クラス フィールドの比較 (結局のところ、=!による比較で十分です)、フィールドが等しくない場合 - false。
-
非プリミティブ フィールドの null と等しいかどうかをチェックし( Stringではメソッドはオーバーライドされ、正しく比較されます)、両方のフィールドが null または等しい場合、チェックは終了し、メソッドはtrueを返します。
-
初期ハッシュ コード値をオブジェクトのageプリミティブに設定します。
-
現在のハッシュ コードに 31 を乗算し (拡散を拡大するため)、非プリミティブ文字列フィールドのハッシュ コードをそれに追加します (null でない場合)。
-
結果を返します。
-
このハッシュ コード オーバーライドの結果、同じ名前とint値を持つオブジェクトは常に同じ値を返します。
103. if (obj instanceof Student) と if (getClass() == obj.getClass()) の使用の違いは何ですか?
それぞれのアプローチが何を行うかを見てみましょう。-
instanceof は、左側のオブジェクト参照が右側の型またはそのサブタイプのインスタンスであるかどうかを確認します。
-
getClass() == ... 型の同一性をチェックします。
104. clone() メソッドについて簡単に説明します。
Clone()はObjectクラスのメソッドであり、その目的は、現在のオブジェクトのクローン (現在のオブジェクトのコピー) を作成して返すことです。 これを使用するには、 Cloneable マーカー インターフェイスを実装する必要があります。
マーカー インターフェイスを実装する必要があります。
Student implements Cloneable@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}105. 参照型のオブジェクトのフィールドを操作する clone() メソッドの特徴は何ですか?
オブジェクトのクローンを作成する場合、プリミティブ値とオブジェクト参照の値のみがコピーされます。これは、オブジェクトの内部フィールドに別のオブジェクトへのリンクがある場合、このリンクのみが複製され、他のオブジェクト自体は複製されないことを意味します。実際、これは表面クローン作成と呼ばれるものです。では、すべてのネストされたオブジェクトのクローンを作成する本格的なクローン作成が必要な場合はどうすればよいでしょうか? これらがリンクのコピーではなく、ヒープ内の他の占有メモリ セルを持つオブジェクトの本格的なクローンであることを確認するにはどうすればよいでしょうか? 実際、すべては非常に簡単です。このためには、これらの内部オブジェクトの各クラスのclone()メソッドもオーバーライドし、マーカー インターフェイスCloneableを追加する必要があります。この場合、コピーされるのはオブジェクトへの参照ではなく、オブジェクト自体です。これは、オブジェクト自体もコピーできるためです。例外
106. エラーと例外の違いは何ですか?
例外とエラーはどちらもThrowableクラスのサブクラスです。ただし、それぞれに違いがあります。このエラーは、主にシステム リソースの不足によって発生する問題を示します。そして、私たちのアプリケーションはこの種の問題を検出すべきではありません。エラーの例としては、システム クラッシュやメモリ不足エラーなどがあります。エラーはチェックされていないタイプであるため、ほとんどの場合実行時に発生します。 例外とは、実行時およびコンパイル時に発生する可能性のある問題です。通常、これは開発者が作成したコードで発生します。つまり、例外はより予測可能であり、開発者としての私たちへの依存度が高くなります。同時に、エラーはよりランダムであり、私たちとは無関係であり、むしろアプリケーションが実行されるシステム自体の問題に依存します。
例外とは、実行時およびコンパイル時に発生する可能性のある問題です。通常、これは開発者が作成したコードで発生します。つまり、例外はより予測可能であり、開発者としての私たちへの依存度が高くなります。同時に、エラーはよりランダムであり、私たちとは無関係であり、むしろアプリケーションが実行されるシステム自体の問題に依存します。
107. チェック済みとチェックなし、例外、スロー、スローの違いは何ですか。
先ほども述べたように、例外とは、プログラムの実行中およびコンパイル中に、開発者が作成したコード内で(何らかの異常な状況により)発生したエラーです。 Checked は例外の一種であり、常にtry-catchメカニズムを使用して処理するか、上記のメソッドにスローする必要があります。 Throws は、メソッドによってスローされる可能性のある例外を示すためにメソッド ヘッダーで使用されます。つまり、これは上記のメソッドに例外を「スロー」するためのメカニズムです。 未チェックは、処理する必要のない例外の一種であり、通常は予測可能性が低く、発生する可能性も低くなります。ただし、必要に応じて加工することもできます。 Throw は、例外を手動でスローする場合に使用されます。次に例を示します。throw new Exception();108. 例外の階層は何ですか?
例外の階層は非常に大きく広範囲にわたり、ここですべてを説明するには広すぎます。したがって、その主要なリンクのみを考慮します。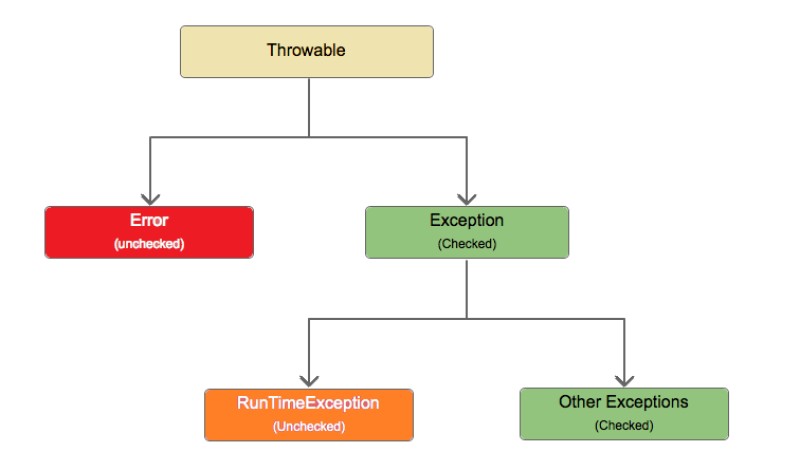 ここでは、階層の最上部に、例外階層の祖先である一般クラスであるクラスThrowableが表示されます。このクラスは、次のように分割されます。
ここでは、階層の最上部に、例外階層の祖先である一般クラスであるクラスThrowableが表示されます。このクラスは、次のように分割されます。
- エラー- 重大なチェック不可能なエラー。
- 例外- チェックされた例外。
109. チェック済み例外とチェックなし例外とは何ですか?
以前お話ししたように:-
チェック済み- 何らかの方法で処理する必要がある例外。つまり、try - catchブロックで処理するか、上記のメソッドに「転送」する必要があります。これを行うには、メソッド シグネチャで、メソッド引数をリストした後、 trows <例外タイプ>キーワードを使用する必要があります。これは、メソッドがこの例外 (警告のようなもの) をスローできることをメソッドのユーザーに示し、例外を処理する責任はこのメソッドのユーザーにあります。
-
未チェック- コンパイル時にチェックされず、一般に予測不可能であるため、処理する必要のない例外。つまり、checked との主な違いは、これらのtry-catchまたは throw メカニズムは同じように機能しますが、必須ではないことです。
101. メソッドの try-catch ブロックで例外をインターセプトして処理する例を作成する
try{ // начало блока перехвата
throw new Exception(); // ручной бросок исключения
} catch (Exception e) { // данное исключение и его потомки будут перехватываться
System.out.println("Упс, что-то пошло не так =("); // вывод некоторого исключения в консоль
}102. 独自の例外を使用して例外をキャッチして処理する例を作成する
まず、独自の例外クラスを作成しましょう。このクラスはExceptionを継承し、そのコンストラクターをエラー メッセージでオーバーライドします。public class CustomException extends Exception {
public CustomException(final String message) {
super(message);
}
}try{
throw new CustomException("Упс, что-то пошло не так =(");
} catch (CustomException e) {
System.out.println(e.getMessage());
} 例外の詳細については、こちらをご覧ください。それでは、今日はここまでです!次のパートでお会いしましょう!
例外の詳細については、こちらをご覧ください。それでは、今日はここまでです!次のパートでお会いしましょう!
GO TO FULL VERSION