정렬은 개체에 대해 수행되는 기본 활동 유형 중 하나입니다. 어린 시절에도 아이들은 분류하고 사고력을 발전시키는 법을 배웁니다. 컴퓨터와 프로그램도 예외는 아닙니다. 매우 다양한 알고리즘이 있습니다. 나는 그들이 무엇인지, 어떻게 작동하는지 살펴 보는 것이 좋습니다. 게다가 어느 날 인터뷰에서 이러한 질문을 받는다면 어떻게 될까요?
소개
요소 정렬은 개발자가 익숙해져야 하는 알고리즘 범주 중 하나입니다. 옛날에 제가 공부할 때는 컴퓨터 과학이 그렇게 심각하게 받아들여지지 않았다면, 이제는 학교에서 정렬 알고리즘을 구현하고 이해할 수 있어야 합니다. 가장 간단한 기본 알고리즘은 루프를 사용하여 구현됩니다 for. 당연히 배열과 같은 요소 컬렉션을 정렬하려면 어떻게든 이 컬렉션을 탐색해야 합니다. 예를 들어:
int[] array ={10,2,10,3,1,2,5};for(int i =0; i < array.length; i++){System.out.println(array[i]);}
이 코드에 대해 무엇을 말할 수 있나요? int i인덱스 값( )을 0에서 배열의 마지막 요소로 변경하는 루프가 있습니다 . 본질적으로 우리는 단순히 배열의 각 요소를 가져와 그 내용을 인쇄합니다. 배열에 요소가 많을수록 코드를 실행하는 데 시간이 더 오래 걸립니다. 즉, n이 요소 수인 경우 n=10인 경우 프로그램은 n=5인 경우보다 실행하는 데 2배 더 오래 걸립니다. 프로그램에 루프가 하나 있으면 실행 시간이 선형적으로 증가합니다. 요소가 많을수록 실행 시간이 길어집니다. 위 코드의 알고리즘은 선형 시간(n)으로 실행되는 것으로 나타났습니다. 이러한 경우 "알고리즘 복잡도"는 O(n)이라고 합니다. 이 표기법은 "big O" 또는 "점근적 행동"이라고도 합니다. 하지만 "알고리즘의 복잡성"만 기억하면 됩니다.
가장 간단한 정렬(버블정렬)
따라서 배열이 있고 이를 반복할 수 있습니다. 엄청난. 이제 오름차순으로 정렬해 보겠습니다. 이것이 우리에게 무엇을 의미합니까? 이는 두 개의 요소(예: a=6, b=5)가 주어졌을 때 a가 b보다 크면(a > b인 경우) a와 b를 바꿔야 함을 의미합니다. 인덱스별로 컬렉션을 작업할 때(배열의 경우처럼) 이는 우리에게 무엇을 의미합니까? 이는 인덱스 a가 있는 요소가 인덱스 b가 있는 요소보다 큰 경우(array[a] > array[b]) 해당 요소를 교체해야 함을 의미합니다. 장소를 바꾸는 것을 흔히 스왑이라고 합니다. 장소를 바꾸는 방법은 다양합니다. 그러나 우리는 간단하고 명확하며 기억하기 쉬운 코드를 사용합니다.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);}}System.out.println(Arrays.toString(array));
보시다시피 요소의 위치가 실제로 변경되었습니다. 우리는 하나의 요소로 시작했습니다. 왜냐하면... 배열이 하나의 요소로만 구성된 경우 1 < 1 표현식은 true를 반환하지 않으므로 요소가 하나 있거나 요소가 전혀 없는 배열의 경우로부터 우리 자신을 보호할 수 있으며 코드가 더 좋아 보일 것입니다. 하지만 우리의 최종 배열은 어쨌든 정렬되지 않았습니다. 왜냐하면... 한 번에 모든 사람을 정렬하는 것은 불가능합니다. 정렬된 배열을 얻을 때까지 패스를 하나씩 수행하는 또 다른 루프를 추가해야 합니다.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));boolean needIteration =true;while(needIteration){
needIteration =false;for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);
needIteration =true;}}}System.out.println(Arrays.toString(array));
그래서 첫 번째 정렬이 작동했습니다. while더 이상 반복이 필요하지 않다고 결정할 때까지 외부 루프( )에서 반복합니다 . 기본적으로 새로운 반복을 수행하기 전에 배열이 정렬되어 있다고 가정하고 더 이상 반복을 원하지 않습니다. 따라서 우리는 요소를 순차적으로 살펴보고 이 가정을 확인합니다. 그러나 요소의 순서가 잘못된 경우 요소를 교환하고 요소가 이제 올바른 순서인지 확신할 수 없다는 것을 깨닫게 됩니다. 따라서 우리는 한 번 더 반복을 수행하려고 합니다. 예를 들어 [3, 5, 2]입니다. 5는 3보다 크므로 모든 것이 괜찮습니다. 그러나 2는 5보다 작습니다. 그러나 [3, 2, 5]에는 패스가 한 번 더 필요합니다. 3 > 2이며 교체해야 합니다. 루프 내에서 루프를 사용하기 때문에 알고리즘의 복잡성이 증가하는 것으로 나타났습니다. n개의 요소를 사용하면 n * n, 즉 O(n^2)이 됩니다. 이 복잡도를 2차라고 합니다. 우리가 알고 있듯이 반복이 얼마나 많이 필요한지 정확히 알 수는 없습니다. 알고리즘 복잡도 지표는 최악의 경우 복잡도가 증가하는 추세를 보여주는 목적으로 사용됩니다. 요소 수 n이 변경되면 실행 시간이 얼마나 증가합니까? 버블 정렬은 가장 간단하면서도 비효율적인 정렬 중 하나입니다. 때로는 "어리석은 정렬"이라고도 합니다. 관련 자료:
또 다른 정렬은 선택 정렬입니다. 또한 2차 복잡도도 있지만 이에 대해서는 나중에 자세히 설명합니다. 그래서 아이디어는 간단합니다. 각 패스에서는 가장 작은 요소를 선택하여 시작 부분으로 이동합니다. 이 경우 오른쪽으로 이동하여 각각의 새 패스를 시작합니다. 즉, 첫 번째 패스(첫 번째 요소에서, 두 번째 패스)를 두 번째 요소에서 시작합니다. 다음과 같이 보일 것입니다:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){int minInd = left;for(int i = left; i < array.length; i++){if(array[i]< array[minInd]){
minInd = i;}}swap(array, left, minInd);}System.out.println(Arrays.toString(array));
이 정렬은 불안정합니다. 동일한 요소(요소를 정렬하는 특성의 관점에서)는 위치를 변경할 수 있습니다. 좋은 예가 Wikipedia 기사 Sorting_by-selection 에 나와 있습니다 . 관련 자료:
삽입 정렬 역시 루프 내에 루프가 있으므로 2차 복잡성을 갖습니다. 선택 정렬과 어떻게 다른가요? 이 정렬은 "안정적"입니다. 이는 동일한 요소가 순서를 변경하지 않음을 의미합니다. 우리가 정렬하는 특성 측면에서 동일합니다.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){// Retrieve the value of the elementint value = array[left];// Move through the elements that are before the pulled elementint i = left -1;for(; i >=0; i--){// If a smaller value is pulled out, move the larger element furtherif(value < array[i]){
array[i +1]= array[i];}else{// If the pulled element is larger, stopbreak;}}// Insert the extracted value into the freed space
array[i +1]= value;}System.out.println(Arrays.toString(array));
간단한 정렬 중에는 셔틀 정렬이라는 또 다른 정렬이 있습니다. 그러나 나는 셔틀 종류를 선호합니다. 우리는 우주 왕복선에 대해 거의 이야기하지 않는 것 같고 셔틀은 달리기에 더 가깝습니다. 따라서 셔틀이 우주로 어떻게 발사되는지 상상하기가 더 쉽습니다. 이 알고리즘과의 연관성은 다음과 같습니다. 알고리즘의 본질은 무엇인가? 알고리즘의 핵심은 왼쪽에서 오른쪽으로 반복하고 요소를 교체할 때 뒤에 남아 있는 다른 모든 요소를 확인하여 교체를 반복해야 하는지 확인하는 것입니다.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i -1);for(int z = i -1;(z -1)>=0; z--){if(array[z]< array[z -1]){swap(array, z, z -1);}else{break;}}}}System.out.println(Arrays.toString(array));
또 다른 간단한 정렬은 Shell 정렬입니다. 그 본질은 버블 정렬과 유사하지만, 반복할 때마다 비교되는 요소 사이에 서로 다른 간격이 있습니다. 각 반복마다 절반으로 줄어듭니다. 구현 예는 다음과 같습니다.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));// Calculate the gap between the checked elementsint gap = array.length /2;// As long as there is a difference between the elementswhile(gap >=1){for(int right =0; right < array.length; right++){// Shift the right pointer until we can find one that// there won't be enough space between it and the element before itfor(int c = right - gap; c >=0; c -= gap){if(array[c]> array[c + gap]){swap(array, c, c + gap);}}}// Recalculate the gap
gap = gap /2;}System.out.println(Arrays.toString(array));
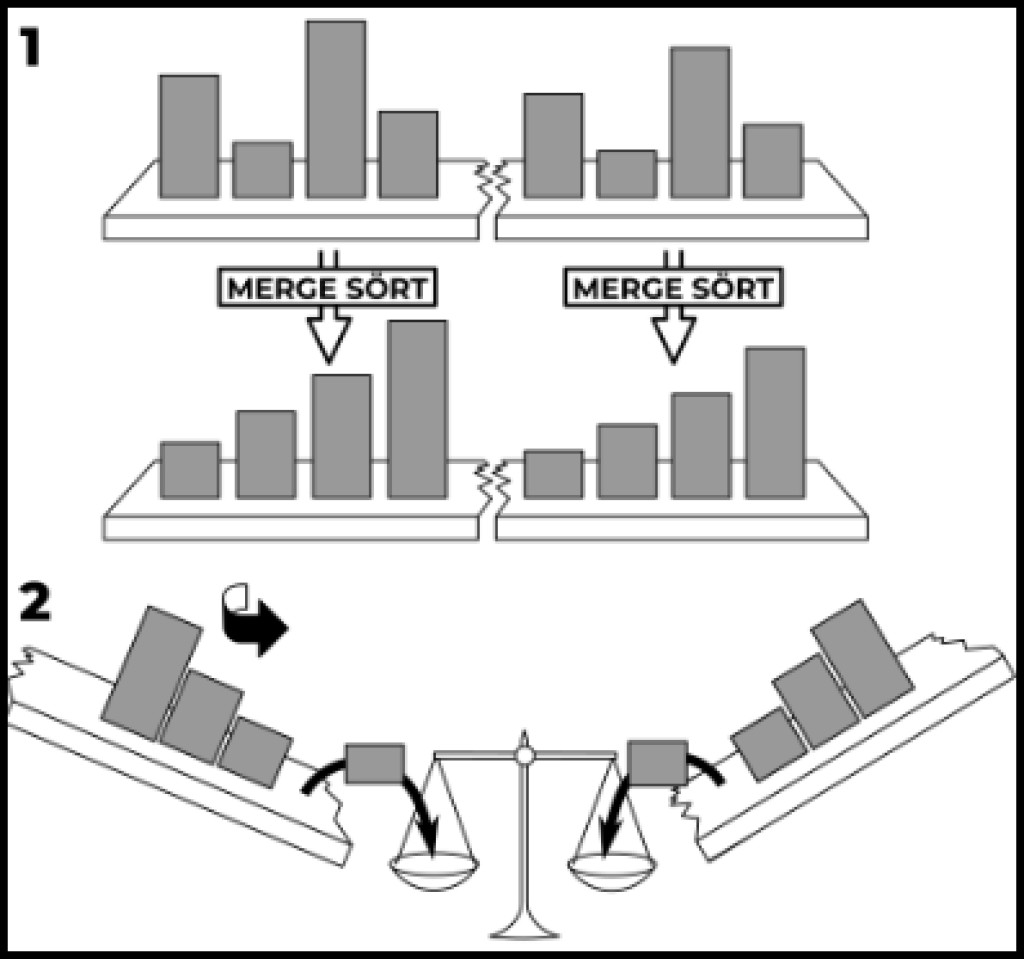
표시된 단순 정렬 외에도 더 복잡한 정렬이 있습니다. 예를 들어 병합 정렬이 있습니다. 첫째, 재귀가 도움이 될 것입니다. 둘째, 우리의 복잡성은 더 이상 우리가 익숙했던 것처럼 2차 방정식이 아닐 것입니다. 이 알고리즘의 복잡성은 대수적입니다. O(n log n)으로 작성됩니다. 그럼 이렇게 해보자. 먼저 정렬 메서드에 대한 재귀 호출을 작성해 보겠습니다.
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}}
이제 메인 액션을 추가해 보겠습니다. 다음은 구현된 슈퍼메소드의 예입니다.
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}// Create a temporary array with the desired sizeint[] buffer =newint[right - left +1];// Starting from the specified left border, go through each elementint cursor = left;for(int i =0; i < buffer.length; i++){// We use the delimeter to point to the element from the right side// If delimeter > right, then there are no unadded elements left on the right sideif(delimiter > right || source[cursor]> source[delimiter]){
buffer[i]= source[cursor];
cursor++;}else{
buffer[i]= source[delimiter];
delimiter++;}}System.arraycopy(buffer,0, source, left, buffer.length);}
를 호출하여 예제를 실행해 보겠습니다 mergeSort(array, 0, array.length-1). 보시다시피 본질은 정렬할 섹션의 시작과 끝을 나타내는 배열을 입력으로 사용한다는 사실로 귀결됩니다. 정렬이 시작되면 이것이 배열의 시작이자 끝이 됩니다. 다음으로 구분 기호, 즉 구분선의 위치를 계산합니다. 구분선이 두 부분으로 나눌 수 있는 경우 구분선이 배열을 나눈 섹션에 대해 재귀 정렬을 호출합니다. 정렬된 섹션을 선택하는 추가 버퍼 배열을 준비합니다. 다음으로 정렬할 영역의 시작 부분에 커서를 놓고 준비한 빈 배열의 각 요소를 살펴보고 가장 작은 요소로 채웁니다. 커서가 가리키는 요소가 제수가 가리키는 요소보다 작으면 이 요소를 버퍼 배열에 배치하고 커서를 이동합니다. 그렇지 않으면 구분 기호가 가리키는 요소를 버퍼 배열에 배치하고 구분 기호를 이동합니다. 구분 기호가 정렬된 영역의 경계를 벗어나거나 전체 배열을 채우면 지정된 범위가 정렬된 것으로 간주됩니다. 관련 자료:
또 다른 흥미로운 정렬 알고리즘은 Counting Sort입니다. 이 경우 알고리즘 복잡도는 O(n+k)입니다. 여기서 n은 요소 수이고 k는 요소의 최대값입니다. 알고리즘에는 한 가지 문제가 있습니다. 배열의 최소값과 최대값을 알아야 합니다. 다음은 계산 정렬의 구현 예입니다.
publicstaticint[]countingSort(int[] theArray,int maxValue){// Array with "counters" ranging from 0 to the maximum valueint numCounts[]=newint[maxValue +1];// In the corresponding cell (index = value) we increase the counterfor(int num : theArray){
numCounts[num]++;}// Prepare array for sorted resultint[] sortedArray =newint[theArray.length];int currentSortedIndex =0;// go through the array with "counters"for(int n =0; n < numCounts.length; n++){int count = numCounts[n];// go by the number of valuesfor(int k =0; k < count; k++){
sortedArray[currentSortedIndex]= n;
currentSortedIndex++;}}return sortedArray;}
우리가 알고 있듯이 최소값과 최대값을 미리 알아야 하는 것은 매우 불편합니다. 그리고 또 다른 알고리즘인 Radix Sort가 있습니다. 여기서는 알고리즘을 시각적으로만 제시하겠습니다. 구현을 위해서는 다음 자료를 참조하세요.
음, 디저트의 경우 가장 유명한 알고리즘 중 하나인 퀵 정렬(quick sort)입니다. 알고리즘 복잡도가 O(n log n)입니다. 이 정렬을 Hoare 정렬이라고도 합니다. 흥미롭게도 이 알고리즘은 Hoare가 소련에 머무는 동안 발명되었으며, 그곳에서 그는 모스크바 대학에서 컴퓨터 번역을 공부하고 러시아어-영어 관용구집을 개발하고 있었습니다. 이 알고리즘은 Java의 Arrays.sort에서 보다 복잡한 구현에도 사용됩니다. Collections.sort는 어떻습니까? "내부적으로" 어떻게 정렬되어 있는지 직접 확인해 보시기 바랍니다. 따라서 코드는 다음과 같습니다.
publicstaticvoidquickSort(int[] source,int leftBorder,int rightBorder){int leftMarker = leftBorder;int rightMarker = rightBorder;int pivot = source[(leftMarker + rightMarker)/2];do{// Move the left marker from left to right while element is less than pivotwhile(source[leftMarker]< pivot){
leftMarker++;}// Move the right marker until element is greater than pivotwhile(source[rightMarker]> pivot){
rightMarker--;}// Check if you don't need to swap elements pointed to by markersif(leftMarker <= rightMarker){// The left marker will only be less than the right marker if we have to swapif(leftMarker < rightMarker){int tmp = source[leftMarker];
source[leftMarker]= source[rightMarker];
source[rightMarker]= tmp;}// Move markers to get new borders
leftMarker++;
rightMarker--;}}while(leftMarker <= rightMarker);// Execute recursively for partsif(leftMarker < rightBorder){quickSort(source, leftMarker, rightBorder);}if(leftBorder < rightMarker){quickSort(source, leftBorder, rightMarker);}}
여기의 모든 것은 매우 무섭기 때문에 우리가 알아낼 것입니다. 입력 배열 int[]소스의 경우 왼쪽(L)과 오른쪽(R)이라는 두 개의 마커를 설정합니다. 처음 호출되면 배열의 시작과 끝을 일치시킵니다. 다음으로 지원 요소(일명 )가 결정됩니다 pivot. 그 후, 우리의 임무는 보다 작은 값을 pivot왼쪽으로 pivot, 큰 값을 오른쪽으로 이동하는 것입니다. 이렇게 하려면 먼저 L보다 큰 값을 찾을 때까지 포인터를 이동합니다 pivot. 더 작은 값이 발견되지 않으면
L совпадёт с
pivot. Потом двигаем указатель
R пока не найдём меньшее, чем
pivot meaning. Если меньшее meaning не нашли, то
R совпадёт с
pivot. Далее, если указатель
L находится до указателя
R or совпадает с ним, то пытаемся выполнить обмен элементов, если элемент
L меньше, чем
R. Далее
L сдвигаем вправо на 1 позицию,
R сдвигаем влево на одну позицию. Когда левый маркер
L окажется за правым маркером
R это будет означать, что обмен закончен, слева от
pivot меньшие значения, справа от
pivot — большие значения. После этого рекурсивно вызываем такую же сортировку для участков массива от начала сортируемого участка до правого маркера и от левого маркера до конца сортируемого участка. Почему от начала до правого? Потому что в конце итерации так и получится, что правый маркер сдвинется настолько, что станет границей части слева. Этот алгоритм более сложный, чем простая sorting, поэтому его лучше зарисовать. Возьмём белый лист бумаги, запишем: 4 2 6 7 3 , а
Pivot по центру, т.е. число 6. Обведём его в круг. Под 4 напишем
L, под 3 напишем
R. 4 меньше чем 6, 2 меньше чем 6. Total,
L переместился на положение
pivot, т.к. по условию
L не может уйти дальше, чем
pivot. Напишем снова 4 2 6 7 3 , обведём 6 вкруг (
pivot) и поставим под ним
L. Теперь двигаем указатель
R. 3 меньше чем 6, поэтому ставим маркер
R на цифру 3. Так How 3 меньше, чем
pivot 6 выполняем
swap, т.е. обмен. Запишем результат: 4 2 3 7 6 , обводим 6 вкруг, т.к. он по прежнему
pivot. Указатель
L на цифре 3, указатель
R на цифре 6. Мы помним, что двигаем указатели до тех пор, пока
L не зайдём за
R.
L двигаем на следующую цифру. Тут хочется разобрать два варианта: если бы предпоследняя цифра была 7 и если бы она была не 7, а 1.
Предпоследня цифра 1: Сдвинули указатель
L на цифру 1, т.к. мы можем двигать
L до тех пор, пока указатель
L указывает на цифру, меньшую чем
pivot. А вот
R мы не можем сдвинуть с 6, т.к. R не мы можем двигать только если указатель
R указывает на цифру, которая больше чем
pivot.
swap не делаем, т.к. 1 меньше 6. Записываем положение: 4 2 3 1 6, обводим
pivot 6.
L сдвигается на
pivot и больше не двигается.
R тоже не двигается. Обмен не производим. Сдвигаем
L и
R на одну позицию и подписываем цифру 1 маркером
R, а
L получается вне числа. Т.к.
L вне числа — ничего не делаем, а вот часть 4 2 3 1 выписываем снова, т.к. это наша левая часть, меньшая, чем
pivot 6. Выделяем новый
pivot и начинаем всё снова )
Предпоследняя цифра 7: Сдвинули указать
L на цифру 7, правый указатель не можем двигать, т.к. он уже указывает на pivot. т.к. 7 больше, чем
pivot, то делаем
swap. Запишем результат: 4 2 3 6 7, обводим 6 кружком, т.к. он
pivot. Указатель
L теперь сдвигается на цифру 7, а указатель
R сдвигается на цифру 3. Часть от
L до конца нет смысла сортировать, т.к. там всего 1 элемент, а вот часть от 4 до указателя
R отправляем на сортировку. Выбираем
pivot и начинаем всё снова ) Может на первый взгляд показаться, что если расставить много одинаковых с
pivot значений, это сломает алгоритм, но это не так. Можно напридумывать каверзных вариантов и на бумажке убедиться, что всё правильно и подивиться, How такие простые действия предоставляют такой надёжный механизм. Единственный минус — такая sorting не является стабильной. Т.к. при выполнении обмена одинаковые элементы могут поменять свой порядок, если один из них встретился до
pivot до того, How другой элемент попал в часть до
pivot при помощи обмена. Материал:
Выше мы рассмотрели "джентельменский" набор алгоритмов сортировки, реализованных на Java. Алгоритмы вообще штука полезная, How с прикладной точки зрения, так и с точки зрения развития мышления. Некоторые из них попроще, некоторые посложнее. По Howим-то умные люди защищали различные работы на степени, а по другим писали толстые-толстые книги. Надеюсь, приложенный к статье материал позволит вам узнать ещё больше, так How это обзорная статья, которая и так получилась увесистой. И цель её — дать небольшое вступление. Про введение в алгоритмы можно так же прочитать ознакомиться с книгой "
Грокаем Алгоримы". Также мне нравится плэйлист от Jack Brown —
AQA Decision 1 1.01 Tracing an Algorithm. Ради интереса можно посмотреть на визуализацию алгоритмов на
sorting.at и
visualgo.net. Ну и весь Youtube к вашим услугам.









GO TO FULL VERSION