Sortowanie jest jednym z podstawowych rodzajów czynności lub akcji wykonywanych na obiektach. Już w dzieciństwie dzieci uczy się sortowania, rozwijając w ten sposób myślenie. Komputery i programy również nie są wyjątkiem. Istnieje ogromna różnorodność algorytmów. Sugeruję przyjrzeć się temu, czym są i jak działają. Poza tym, co się stanie, jeśli pewnego dnia zostaniesz zapytany o jedno z nich w rozmowie kwalifikacyjnej?
Wstęp
Sortowanie elementów to jedna z kategorii algorytmów, do których programista musi się przyzwyczaić. Jeśli kiedyś, gdy ja studiowałem, informatyki nie traktowano tak poważnie, teraz w szkole powinni umieć wdrażać algorytmy sortowania i je rozumieć. Podstawowe algorytmy, te najprostsze, realizowane są za pomocą pętli for. Naturalnie, aby posortować zbiór elementów, np. tablicę, trzeba jakoś przez ten zbiór przejść. Na przykład:
int[] array ={10,2,10,3,1,2,5};for(int i =0; i < array.length; i++){System.out.println(array[i]);}
Co możesz powiedzieć o tym fragmencie kodu? Mamy pętlę, w której zmieniamy wartość indeksu ( int i) z 0 na ostatni element tablicy. W rzeczywistości po prostu bierzemy każdy element tablicy i drukujemy jego zawartość. Im więcej elementów w tablicy, tym dłużej trwa wykonanie kodu. Oznacza to, że jeśli n jest liczbą elementów, przy n=10 wykonanie programu będzie trwało 2 razy dłużej niż przy n=5. Gdy nasz program ma jedną pętlę, czas wykonania rośnie liniowo: im więcej elementów, tym dłuższe wykonanie. Okazuje się, że algorytm powyższego kodu działa w czasie liniowym (n). W takich przypadkach mówi się, że „złożoność algorytmu” wynosi O(n). Zapis ten nazywany jest także „dużym O” lub „zachowaniem asymptotycznym”. Ale możesz po prostu zapamiętać „złożoność algorytmu”.
Najprostsze sortowanie (Bubble Sort)
Mamy więc tablicę i możemy po niej iterować. Świetnie. Spróbujmy teraz posortować to w kolejności rosnącej. Co to oznacza dla nas? Oznacza to, że biorąc pod uwagę dwa elementy (na przykład a=6, b=5), musimy zamienić a i b, jeśli a jest większe niż b (jeśli a > b). Co to dla nas oznacza podczas pracy z kolekcją według indeksu (tak jak w przypadku tablicy)? Oznacza to, że jeśli element o indeksie a jest większy od elementu o indeksie b (tablica[a] > tablica[b]), to elementy te należy zamienić miejscami. Zmiana miejsca jest często nazywana zamianą. Są różne sposoby zmiany miejsca. Ale używamy prostego, jasnego i łatwego do zapamiętania kodu:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);}}System.out.println(Arrays.toString(array));
Jak widzimy, elementy rzeczywiście zamieniły się miejscami. Zaczęliśmy od jednego elementu, bo... jeśli tablica składa się tylko z jednego elementu, wyrażenie 1 < 1 nie zwróci prawdy i w ten sposób zabezpieczymy się przed przypadkami tablicy z jednym elementem lub w ogóle bez nich, a kod będzie wyglądał lepiej. Ale nasza ostateczna tablica i tak nie jest posortowana, ponieważ... Nie da się posortować wszystkich w jednym przebiegu. Będziemy musieli dodać kolejną pętlę, w której będziemy wykonywać przejścia jeden po drugim, aż otrzymamy posortowaną tablicę:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));boolean needIteration =true;while(needIteration){
needIteration =false;for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);
needIteration =true;}}}System.out.println(Arrays.toString(array));
Zatem nasze pierwsze sortowanie zadziałało. Wykonujemy iterację w pętli zewnętrznej ( while), dopóki nie zdecydujemy, że nie są potrzebne żadne dalsze iteracje. Domyślnie przed każdą nową iteracją zakładamy, że nasza tablica jest posortowana i nie chcemy już iterować. Dlatego przeglądamy elementy sekwencyjnie i sprawdzamy to założenie. Jeśli jednak elementy nie są w porządku, zamieniamy je miejscami i zdajemy sobie sprawę, że nie jesteśmy pewni, czy elementy są teraz we właściwej kolejności. Dlatego chcemy wykonać jeszcze jedną iterację. Na przykład [3, 5, 2]. 5 to więcej niż trzy, wszystko jest w porządku. Ale 2 to mniej niż 5. Jednak [3, 2, 5] wymaga jeszcze jednego przejścia, ponieważ 3 > 2 i trzeba je zamienić. Ponieważ używamy pętli w pętli, okazuje się, że złożoność naszego algorytmu wzrasta. Przy n elementach staje się n * n, czyli O(n^2). Złożoność tę nazywamy kwadratową. Jak rozumiemy, nie możemy dokładnie wiedzieć, ile iteracji będzie potrzebnych. Wskaźnik złożoności algorytmu służy do pokazania tendencji wzrostu złożoności, w najgorszym przypadku. O ile wzrośnie czas działania, gdy zmieni się liczba elementów n. Sortowanie bąbelkowe jest jednym z najprostszych i najbardziej nieefektywnych. Czasami nazywa się to także „głupim sortowaniem”. Powiązany materiał:
Innym rodzajem jest sortowanie przez wybór. Ma również złożoność kwadratową, ale o tym później. Pomysł jest więc prosty. Każde przejście wybiera najmniejszy element i przenosi go na początek. W takim przypadku każdy nowy przebieg należy rozpoczynać od ruchu w prawo, czyli pierwszy przebieg – od pierwszego elementu, drugi – od drugiego. Będzie to wyglądać tak:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){int minInd = left;for(int i = left; i < array.length; i++){if(array[i]< array[minInd]){
minInd = i;}}swap(array, left, minInd);}System.out.println(Arrays.toString(array));
To sortowanie jest niestabilne, ponieważ identyczne elementy (z punktu widzenia cechy, według której sortujemy elementy) mogą zmieniać swoje położenie. Dobry przykład podano w artykule w Wikipedii: Sorting_by-selection . Powiązany materiał:
Sortowanie przez wstawianie ma również złożoność kwadratową, ponieważ znowu mamy pętlę w pętli. Czym różni się od sortowania przez wybór? Sortowanie to jest „stabilne”. Oznacza to, że identyczne elementy nie zmienią swojej kolejności. Identyczne pod względem cech, według których sortujemy.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){// Pobierz wartość elementuint value = array[left];// Przechodzenie przez elementy, które znajdują się przed wyciągniętym elementemint i = left -1;for(; i >=0; i--){// Jeśli wyciągnięta zostanie mniejsza wartość, przesuń większy element dalejif(value < array[i]){
array[i +1]= array[i];}else{// Jeśli ciągnięty element jest większy, zatrzymaj siębreak;}}// Wstaw wyodrębnioną wartość w zwolnione miejsce
array[i +1]= value;}System.out.println(Arrays.toString(array));
Wśród sortowania prostego jest jeszcze jeden – sortowanie wahadłowe. Ale bardziej podoba mi się odmiana wahadłowa. Wydaje mi się, że rzadko mówimy o promach kosmicznych, a prom jest raczej biegiem. Dlatego łatwiej jest sobie wyobrazić, w jaki sposób promy są wystrzeliwane w przestrzeń kosmiczną. Oto skojarzenie z tym algorytmem. Jaka jest istota algorytmu? Istota algorytmu polega na tym, że iterujemy od lewej do prawej, a podczas zamiany elementów sprawdzamy wszystkie pozostałe elementy, które pozostały, aby zobaczyć, czy zamiana wymaga powtórzenia.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i -1);for(int z = i -1;(z -1)>=0; z--){if(array[z]< array[z -1]){swap(array, z, z -1);}else{break;}}}}System.out.println(Arrays.toString(array));
Innym prostym sortowaniem jest sortowanie powłoki. Jego istota jest podobna do sortowania bąbelkowego, z tą różnicą, że w każdej iteracji mamy inny odstęp pomiędzy porównywanymi elementami. W każdej iteracji jest zmniejszany o połowę. Oto przykładowa implementacja:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));// Oblicz odstęp między zaznaczonymi elementamiint gap = array.length /2;// Tak długo, jak istnieje różnica między elementamiwhile(gap >=1){for(int right =0; right < array.length; right++){// Przesuń prawy wskaźnik, aż znajdziemy taki// nie będzie wystarczająco dużo miejsca między nim a poprzedzającym go elementemfor(int c = right - gap; c >=0; c -= gap){if(array[c]> array[c + gap]){swap(array, c, c + gap);}}}// Ponownie oblicz odstęp
gap = gap /2;}System.out.println(Arrays.toString(array));
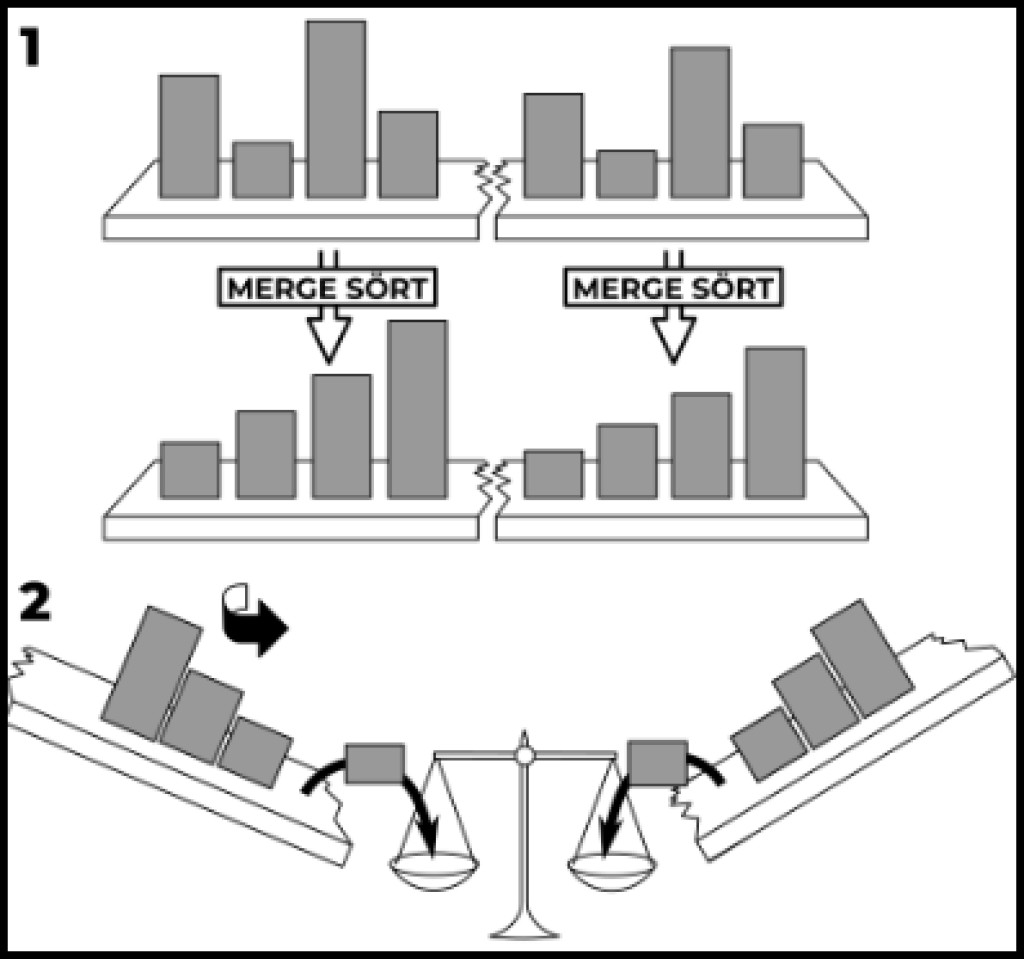
Oprócz wskazanych prostych rodzajów, istnieją bardziej złożone rodzaje. Na przykład sortowanie przez scalanie. Po pierwsze, z pomocą przyjdzie nam rekurencja. Po drugie, nasza złożoność nie będzie już kwadratowa, jak jesteśmy przyzwyczajeni. Złożoność tego algorytmu jest logarytmiczna. Zapisywane jako O(n log n). Więc zróbmy to. Najpierw napiszmy rekurencyjne wywołanie metody sortowania:
publicstaticvoidmergeSort(int[] source,int left,int right){// Wybierz separator, tj. podzielić tablicę wejściową na półint delimiter = left +((right - left)/2)+1;// Wykonaj tę funkcję rekurencyjnie dla dwóch połówek (jeśli możemy podzielić (if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}}
Teraz dodajmy do tego akcję główną. Oto przykład naszej supermetody z implementacją:
publicstaticvoidmergeSort(int[] source,int left,int right){// Wybierz separator, tj. podzielić tablicę wejściową na półint delimiter = left +((right - left)/2)+1;// Wykonaj tę funkcję rekurencyjnie dla dwóch połówek (jeśli możemy podzielić (if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}// Utwórz tymczasową tablicę o żądanym rozmiarzeint[] buffer =newint[right - left +1];// Rozpoczynając od określonej lewej krawędzi, przejdź przez każdy elementint cursor = left;for(int i =0; i < buffer.length; i++){// Używamy ogranicznika, aby wskazać element z prawej strony// Jeśli delimeter > right, to po prawej stronie nie ma żadnych niedodanych elementówif(delimiter > right || source[cursor]> source[delimiter]){
buffer[i]= source[cursor];
cursor++;}else{
buffer[i]= source[delimiter];
delimiter++;}}System.arraycopy(buffer,0, source, left, buffer.length);}
Uruchommy przykład, wywołując metodę mergeSort(array, 0, array.length-1). Jak widać istota sprowadza się do tego, że na wejściu przyjmujemy tablicę wskazującą początek i koniec sortowanej sekcji. Kiedy rozpoczyna się sortowanie, jest to początek i koniec tablicy. Następnie obliczamy ogranicznik - położenie dzielnika. Jeśli dzielnik może podzielić tablicę na 2 części, sortowaniem rekurencyjnym nazywamy sekcje, na które dzielnik podzielił tablicę. Przygotowujemy dodatkową tablicę buforów, w której wybieramy posortowaną sekcję. Następnie stawiamy kursor na początku obszaru przeznaczonego do sortowania i zaczynamy przeglądać każdy element przygotowanej przez nas pustej tablicy i wypełniać ją najmniejszymi elementami. Jeżeli element wskazywany przez kursor jest mniejszy od elementu wskazywanego przez dzielnik, umieszczamy ten element w tablicy buforów i przesuwamy kursor. W przeciwnym razie umieszczamy element wskazywany przez separator w tablicy buforów i przesuwamy separator. Gdy tylko separator wyjdzie poza granice posortowanego obszaru lub zapełnimy całą tablicę, określony zakres uważa się za posortowany. Powiązany materiał:
Innym interesującym algorytmem sortowania jest sortowanie zliczające. Złożoność algorytmiczna w tym przypadku będzie wynosić O(n+k), gdzie n jest liczbą elementów, a k jest maksymalną wartością elementu. Algorytm ma jeden problem: musimy znać wartości minimalne i maksymalne w tablicy. Oto przykładowa implementacja sortowania przez zliczanie:
publicstaticint[]countingSort(int[] theArray,int maxValue){// Tablica z "licznikami" w zakresie od 0 do wartości maksymalnejint numCounts[]=newint[maxValue +1];// W odpowiedniej komórce (indeks = wartość) zwiększamy licznikfor(int num : theArray){
numCounts[num]++;}// Przygotuj tablicę dla posortowanego wynikuint[] sortedArray =newint[theArray.length];int currentSortedIndex =0;// przejrzyj tablicę z "licznikami"for(int n =0; n < numCounts.length; n++){int count = numCounts[n];// przejdź przez liczbę wartościfor(int k =0; k < count; k++){
sortedArray[currentSortedIndex]= n;
currentSortedIndex++;}}return sortedArray;}
Jak rozumiemy, jest to bardzo niewygodne, gdy musimy znać z góry wartości minimalne i maksymalne. A potem jest inny algorytm – Sortowanie Radix. Algorytm przedstawię tutaj jedynie wizualnie. Aby zapoznać się z realizacją, zobacz materiały:
Cóż, na deser - jeden z najbardziej znanych algorytmów: szybkie sortowanie. Ma złożoność algorytmiczną, to znaczy mamy O(n log n). Ten rodzaj nazywa się także sortowaniem Hoare’a. Co ciekawe, algorytm został wymyślony przez Hoare’a podczas jego pobytu w Związku Radzieckim, gdzie studiował tłumaczenie komputerowe na Uniwersytecie Moskiewskim i opracowywał rozmówki rosyjsko-angielskie. Algorytm ten jest również używany w bardziej złożonej implementacji w Arrays.sort w Javie. A co z Collections.sort? Sugeruję, abyś sam przekonał się, jak są one sortowane „pod maską”. Zatem kod:
publicstaticvoidquickSort(int[] source,int leftBorder,int rightBorder){int leftMarker = leftBorder;int rightMarker = rightBorder;int pivot = source[(leftMarker + rightMarker)/2];do{// Przesuń lewy znacznik z lewej na prawą, gdy element jest mniejszy niż obrótwhile(source[leftMarker]< pivot){
leftMarker++;}// Przesuń prawy znacznik, aż element będzie większy niż obrótwhile(source[rightMarker]> pivot){
rightMarker--;}// Sprawdź, czy nie musisz zamieniać elementów wskazywanych przez znacznikiif(leftMarker <= rightMarker){// Lewy znacznik będzie mniejszy niż prawy tylko wtedy, gdy będziemy musieli zamienićif(leftMarker < rightMarker){int tmp = source[leftMarker];
source[leftMarker]= source[rightMarker];
source[rightMarker]= tmp;}// Przesuń znaczniki, aby uzyskać nowe granice
leftMarker++;
rightMarker--;}}while(leftMarker <= rightMarker);// Wykonaj rekurencyjnie dla częściif(leftMarker < rightBorder){quickSort(source, leftMarker, rightBorder);}if(leftBorder < rightMarker){quickSort(source, leftBorder, rightMarker);}}
Wszystko tutaj jest bardzo przerażające, więc rozwiążemy to. Dla źródła tablicy wejściowej int[]ustawiamy dwa znaczniki, lewy (L) i prawy (R). Przy pierwszym wywołaniu dopasowują początek i koniec tablicy. Następnie określany jest element nośny, czyli pivot. Następnie naszym zadaniem jest przesunięcie wartości mniejszych niż pivot, w lewo pivoti większych w prawo. Aby to zrobić, najpierw przesuwaj wskaźnik, Laż znajdziemy wartość większą niż pivot. Jeśli nie zostanie znaleziona mniejsza wartość, wówczas
L совпадёт с
pivot. Потом двигаем указатель
R пока не найдём меньшее, чем
pivot oznaczający. Если меньшее oznaczający не нашли, то
R совпадёт с
pivot. Далее, если указатель
L находится до указателя
R Lub совпадает с ним, то пытаемся выполнить обмен элементов, если элемент
L меньше, чем
R. Далее
L сдвигаем вправо на 1 позицию,
R сдвигаем влево на одну позицию. Когда левый маркер
L окажется за правым маркером
R это будет означать, что обмен закончен, слева от
pivot меньшие значения, справа от
pivot — большие значения. После этого рекурсивно вызываем такую же сортировку для участков массива от начала сортируемого участка до правого маркера и от левого маркера до конца сортируемого участка. Почему от начала до правого? Потому что в конце итерации так и получится, что правый маркер сдвинется настолько, что станет границей части слева. Этот алгоритм более сложный, чем простая sortowanie, поэтому его лучше зарисовать. Возьмём белый лист бумаги, запишем: 4 2 6 7 3 , а
Pivot по центру, т.е. число 6. Обведём его в круг. Под 4 напишем
L, под 3 напишем
R. 4 меньше чем 6, 2 меньше чем 6. Całkowity,
L переместился на положение
pivot, т.к. по условию
L не может уйти дальше, чем
pivot. Напишем снова 4 2 6 7 3 , обведём 6 вкруг (
pivot) и поставим под ним
L. Теперь двигаем указатель
R. 3 меньше чем 6, поэтому ставим маркер
R на цифру 3. Так Jak 3 меньше, чем
pivot 6 выполняем
swap, т.е. обмен. Запишем результат: 4 2 3 7 6 , обводим 6 вкруг, т.к. он по прежнему
pivot. Указатель
L на цифре 3, указатель
R на цифре 6. Мы помним, что двигаем указатели до тех пор, пока
L не зайдём за
R.
L двигаем на следующую цифру. Тут хочется разобрать два варианта: если бы предпоследняя цифра была 7 и если бы она была не 7, а 1.
Предпоследня цифра 1: Сдвинули указатель
L на цифру 1, т.к. мы можем двигать
L до тех пор, пока указатель
L указывает на цифру, меньшую чем
pivot. А вот
R мы не можем сдвинуть с 6, т.к. R не мы можем двигать только если указатель
R указывает на цифру, которая больше чем
pivot.
swap не делаем, т.к. 1 меньше 6. Записываем положение: 4 2 3 1 6, обводим
pivot 6.
L сдвигается на
pivot и больше не двигается.
R тоже не двигается. Обмен не производим. Сдвигаем
L и
R на одну позицию и подписываем цифру 1 маркером
R, а
L получается вне числа. Т.к.
L вне числа — ничего не делаем, а вот часть 4 2 3 1 выписываем снова, т.к. это наша левая часть, меньшая, чем
pivot 6. Выделяем новый
pivot и начинаем всё снова )
Предпоследняя цифра 7: Сдвинули указать
L на цифру 7, правый указатель не можем двигать, т.к. он уже указывает на pivot. т.к. 7 больше, чем
pivot, то делаем
swap. Запишем результат: 4 2 3 6 7, обводим 6 кружком, т.к. он
pivot. Указатель
L теперь сдвигается на цифру 7, а указатель
R сдвигается на цифру 3. Часть от
L до конца нет смысла сортировать, т.к. там всего 1 элемент, а вот часть от 4 до указателя
R отправляем на сортировку. Выбираем
pivot и начинаем всё снова ) Может на первый взгляд показаться, что если расставить много одинаковых с
pivot значений, это сломает алгоритм, но это не так. Можно напридумывать каверзных вариантов и на бумажке убедиться, что всё правильно и подивиться, Jak такие простые действия предоставляют такой надёжный механизм. Единственный минус — такая sortowanie не является стабильной. Т.к. при выполнении обмена одинаковые элементы могут поменять свой порядок, если один из них встретился до
pivot до того, Jak другой элемент попал в часть до
pivot при помощи обмена. Материал:
Выше мы рассмотрели "джентельменский" набор алгоритмов сортировки, реализованных на Java. Алгоритмы вообще штука полезная, Jak с прикладной точки зрения, так и с точки зрения развития мышления. Некоторые из них попроще, некоторые посложнее. По Jakим-то умные люди защищали различные работы на степени, а по другим писали толстые-толстые книги. Надеюсь, приложенный к статье материал позволит вам узнать ещё больше, так Jak это обзорная статья, которая и так получилась увесистой. И цель её — дать небольшое вступление. Про введение в алгоритмы можно так же прочитать ознакомиться с книгой "
Грокаем Алгоримы". Также мне нравится плэйлист от Jack Brown —
AQA Decision 1 1.01 Tracing an Algorithm. Ради интереса можно посмотреть на визуализацию алгоритмов на
sorting.at и
visualgo.net. Ну и весь Youtube к вашим услугам.









GO TO FULL VERSION