Medir a velocidade de um algoritmo em tempo real – em segundos e minutos – não é fácil. Um programa pode rodar mais devagar que outro não por sua própria ineficiência, mas por causa da lentidão do sistema operacional, da incompatibilidade com o hardware, da memória do computador ocupada por outros processos... Para medir a eficácia dos algoritmos, foram inventados conceitos universais. , independentemente do ambiente em que o programa está sendo executado. A complexidade assintótica de um problema é medida usando a notação Big O. Sejam f(x) e g(x) funções definidas em uma certa vizinhança de x0, e g não desaparece aí. Então f é “O” maior que g para (x -> x0) se houver uma constante C> 0 , que para todo x de alguma vizinhança do ponto x0 a desigualdade é válida. |f(x)| <= C |g(x)| Um pouco menos estrita: f é “O” maior que g se houver uma constante C>0, que para todo x > x0 f(x) <= C*g(x) Não tenha medo de a definição formal! Essencialmente, ele determina o aumento assintótico no tempo de execução do programa quando a quantidade de dados de entrada cresce em direção ao infinito. Por exemplo, você está comparando a classificação de um array de 1.000 elementos e 10 elementos e precisa entender como o tempo de execução do programa aumentará. Ou você precisa calcular o comprimento de uma sequência de caracteres analisando caractere por caractere e adicionando 1 para cada caractere: c - 1 a - 2 t - 3 Sua velocidade assintótica = O(n), onde n é o número de letras na palavra. Se contarmos de acordo com este princípio, o tempo necessário para contar a linha inteira será proporcional ao número de caracteres. Contar o número de caracteres em uma sequência de 20 caracteres leva o dobro do tempo que contar o número de caracteres em uma sequência de dez caracteres. Imagine que na variável length você armazenou um valor igual ao número de caracteres da string. Por exemplo, comprimento = 1000. Para obter o comprimento de uma string, você só precisa acessar esta variável, nem precisa olhar a string em si. E não importa como alteramos o comprimento, sempre podemos acessar esta variável. Neste caso, velocidade assintótica = O(1). Alterar os dados de entrada não altera a velocidade de tal tarefa; a pesquisa é concluída em um tempo constante. Neste caso, o programa é assintoticamente constante. Desvantagem: Você desperdiça memória do computador armazenando uma variável adicional e tempo adicional atualizando seu valor. Se você acha que o tempo linear é ruim, podemos garantir que pode ser muito pior. Por exemplo, O(n 2 ). Esta notação significa que à medida que n cresce, o tempo necessário para iterar através dos elementos (ou outra ação) crescerá cada vez mais acentuadamente. Mas para n pequeno, algoritmos com velocidade assintótica O(n 2 ) podem funcionar mais rápido do que algoritmos com velocidade assintótica O(n). Mas em algum momento a função quadrática ultrapassará a linear, não há como evitar isso. Outra complexidade assintótica é o tempo logarítmico ou O(log n). À medida que n aumenta, esta função aumenta muito lentamente. O(log n) é o tempo de execução do algoritmo clássico de busca binária em uma matriz ordenada (lembra da lista telefônica rasgada na palestra?). O array é dividido em dois, então é selecionada a metade em que o elemento está localizado, e assim, cada vez reduzindo a área de busca pela metade, buscamos o elemento. O que acontece se tropeçarmos imediatamente no que procuramos, dividindo nossa matriz de dados ao meio pela primeira vez? Existe um termo para o melhor momento - Omega-grande ou Ω(n). No caso de busca binária = Ω(1) (encontra em tempo constante, independente do tamanho do array). A pesquisa linear é executada em tempo O(n) e Ω(1) se o elemento que está sendo pesquisado for o primeiro. Outro símbolo é teta (Θ(n)). É usado quando as melhores e piores opções são iguais. Isso é adequado para um exemplo em que armazenamos o comprimento de uma string em uma variável separada, portanto, para qualquer comprimento, é suficiente referir-se a essa variável. Para este algoritmo, o melhor e o pior caso são Ω(1) e O(1), respectivamente. Isso significa que o algoritmo é executado no tempo Θ(1).
Pesquisa linear
Ao abrir um navegador, procurar uma página, informações, amigos nas redes sociais, você está fazendo uma pesquisa, como se estivesse tentando encontrar o par de sapatos certo em uma loja. Você provavelmente já percebeu que a ordem tem um grande impacto na forma como você pesquisa. Se você tem todas as camisas no armário, geralmente é mais fácil encontrar a que precisa entre elas do que entre aquelas espalhadas sem sistema pelo cômodo. A pesquisa linear é um método de pesquisa sequencial, um por um. Ao revisar os resultados de pesquisa do Google de cima para baixo, você está usando uma pesquisa linear. Exemplo . Digamos que temos uma lista de números: 2 4 0 5 3 7 8 1 E precisamos encontrar 0. Vemos isso imediatamente, mas um programa de computador não funciona assim. Ela começa no início da lista e vê o número 2. Depois verifica, 2=0? Não é, então ela continua e passa para o segundo personagem. O fracasso também a espera lá, e somente na terceira posição o algoritmo encontra o número necessário. Pseudocódigo para pesquisa linear: A função linearSearch recebe dois argumentos como entrada - a chave key e o array array[]. A chave é o valor desejado, no exemplo anterior key = 0. O array é uma lista de números que nós vai dar uma olhada. Se não encontrarmos nada, a função retornará -1 (uma posição que não existe no array). Se a busca linear encontrar o elemento desejado, a função retornará a posição em que o elemento desejado está localizado no array. O bom da pesquisa linear é que ela funcionará para qualquer array, independentemente da ordem dos elementos: ainda percorreremos todo o array. Esta é também a sua fraqueza. Se você precisar encontrar o número 198 em uma matriz de 200 números classificados em ordem, o loop for passará por 198 etapas. Você provavelmente já adivinhou qual método funciona melhor para um array ordenado?
Pesquisa binária e árvores
Imagine que você tem uma lista de personagens da Disney classificados em ordem alfabética e precisa encontrar o Mickey Mouse. Linearmente levaria muito tempo. E se usarmos o “método de dividir o diretório ao meio”, chegaremos direto ao Jasmine e poderemos descartar com segurança a primeira metade da lista, percebendo que Mickey não pode estar lá. Usando o mesmo princípio, descartamos a segunda coluna. Continuando esta estratégia, encontraremos o Mickey em apenas alguns passos. Vamos encontrar o número 144. Dividimos a lista ao meio e chegamos ao número 13. Avaliamos se o número que procuramos é maior ou menor que 13. 13 < 144, para que possamos ignorar tudo à esquerda de 13 e este próprio número. Agora nossa lista de pesquisa fica assim: Há um número par de elementos, então escolhemos o princípio pelo qual selecionamos o “meio” (mais próximo do início ou do fim). Digamos que escolhemos a estratégia de proximidade ao início. Neste caso, nosso “meio” = 55. 55 < 144. Descartamos novamente a metade esquerda da lista. Felizmente para nós, o próximo número médio é 144. Encontramos 144 em uma matriz de 13 elementos usando pesquisa binária em apenas três etapas. Uma pesquisa linear resolveria a mesma situação em até 12 etapas. Como este algoritmo reduz pela metade o número de elementos no array a cada passo, ele encontrará o necessário em um tempo assintótico O (log n), onde n é o número de elementos na lista. Ou seja, no nosso caso, o tempo assintótico = O(log 13) (isto é um pouco mais que três). Pseudocódigo da função de pesquisa binária: A função recebe 4 argumentos como entrada: a chave desejada, o array de dados array [], no qual o desejado está localizado, min e max são ponteiros para o número máximo e mínimo no array, que estamos examinando esta etapa do algoritmo. Para o nosso exemplo, inicialmente foi fornecida a seguinte imagem: Vamos analisar o código mais detalhadamente. ponto médio é o nosso meio do array. Depende dos pontos extremos e está centrado entre eles. Depois de encontrarmos o meio, verificamos se é menor que o nosso número chave. Nesse caso, então a chave também é maior que qualquer um dos números à esquerda do meio, e podemos chamar a função binária novamente, só que agora nosso min = ponto médio + 1. Se acontecer que chave < ponto médio, podemos descartar esse número em si e todos os números, à sua direita. E chamamos uma pesquisa binária através do array do número mínimo até o valor (ponto médio – 1). Finalmente, o terceiro ramo: se o valor no ponto médio não for maior nem menor que a chave, não há escolha senão ser o número desejado. Neste caso, devolvemos e finalizamos o programa. Finalmente, pode acontecer que o número que você está procurando não esteja na matriz. Para levar este caso em consideração, realizamos a seguinte verificação: E retornamos (-1) para indicar que não encontramos nada. Você já sabe que a pesquisa binária requer que o array seja classificado. Assim, se tivermos um array não classificado no qual precisamos encontrar um determinado elemento, temos duas opções:
Classifique a lista e aplique a pesquisa binária
Mantenha a lista sempre ordenada enquanto adiciona e remove elementos dela simultaneamente.
Uma maneira de manter as listas ordenadas é usar uma árvore de pesquisa binária. Uma árvore de pesquisa binária é uma estrutura de dados que atende aos seguintes requisitos:
É uma árvore (uma estrutura de dados que emula uma estrutura de árvore - possui uma raiz e outros nós (folhas) conectados por “ramos” ou arestas sem ciclos)
Cada nó tem 0, 1 ou 2 filhos
As subárvores esquerda e direita são árvores de pesquisa binária.
Todos os nós da subárvore esquerda de um nó arbitrário X têm valores de chave de dados menores que o valor da chave de dados do próprio nó X.
Todos os nós na subárvore direita de um nó arbitrário X têm valores de chave de dados maiores ou iguais ao valor da chave de dados do próprio nó X.
Atenção: a raiz da árvore do “programador”, ao contrário da real, está no topo. Cada célula é chamada de vértice e os vértices são conectados por arestas. A raiz da árvore é a célula número 13. A subárvore esquerda do vértice 3 está destacada em cores na figura abaixo: Nossa árvore atende a todos os requisitos para árvores binárias. Isso significa que cada uma de suas subárvores esquerdas contém apenas valores menores ou iguais ao valor do vértice, enquanto a subárvore direita contém apenas valores maiores ou iguais ao valor do vértice. As subárvores esquerda e direita são subárvores binárias. O método de construção de uma árvore binária não é o único: abaixo na imagem você vê outra opção para o mesmo conjunto de números, e pode haver muitos deles na prática. Esta estrutura ajuda a realizar a pesquisa: encontramos o valor mínimo movendo de cima para a esquerda e para baixo a cada vez. Se você precisar encontrar o número máximo, vamos de cima para baixo e para a direita. Encontrar um número que não seja mínimo ou máximo também é bastante simples. Descemos da raiz para a esquerda ou para a direita, dependendo se o nosso vértice é maior ou menor que o que procuramos. Então, se precisarmos encontrar o número 89, seguimos este caminho: Você também pode exibir os números em ordem de classificação. Por exemplo, se precisarmos exibir todos os números em ordem crescente, pegamos a subárvore esquerda e, começando no vértice mais à esquerda, subimos. Adicionar algo à árvore também é fácil. A principal coisa a lembrar é a estrutura. Digamos que precisamos adicionar à árvore o valor 7. Vamos até a raiz e verificamos. O número 7 <13, então vamos para a esquerda. Vemos 5 ali e vamos para a direita, já que 7 > 5. Além disso, como 7 > 8 e 8 não tem descendentes, construímos um ramo de 8 para a esquerda e anexamos 7 a ele. Você também pode remover vértices de a árvore, mas isso é um pouco mais complicado. Existem três cenários de exclusão diferentes que precisamos considerar.
A opção mais simples: precisamos deletar um vértice que não tenha filhos. Por exemplo, o número 7 que acabamos de adicionar. Neste caso, simplesmente seguimos o caminho até o vértice com este número e o excluímos.
Um vértice possui um vértice filho. Nesse caso, pode-se deletar o vértice desejado, mas seu descendente deve estar conectado ao “avô”, ou seja, o vértice a partir do qual cresceu seu ancestral imediato. Por exemplo, da mesma árvore precisamos retirar o número 3. Neste caso, juntamos seu descendente, um, junto com toda a subárvore até 5. Isso é feito de forma simples, pois todos os vértices à esquerda de 5 serão menos que esse número (e menos que o triplo remoto).
O caso mais difícil é quando o vértice excluído tem dois filhos. Agora a primeira coisa que precisamos fazer é encontrar o vértice no qual o próximo valor maior está oculto, precisamos trocá-los e, em seguida, excluir o vértice desejado. Observe que o próximo vértice de valor mais alto não pode ter dois filhos, então seu filho esquerdo será o melhor candidato para o próximo valor. Vamos remover da nossa árvore o nó raiz 13. Primeiro, procuramos o número mais próximo de 13, que é maior que ele. Isto é 21. Troque 21 por 13 e exclua 13.
Existem diferentes maneiras de construir árvores binárias, algumas boas, outras nem tanto. O que acontece se tentarmos construir uma árvore binária a partir de uma lista ordenada? Todos os números serão simplesmente adicionados ao ramo direito do anterior. Se quisermos encontrar um número, não teremos escolha senão simplesmente seguir a cadeia para baixo. Não é melhor que a pesquisa linear. Existem outras estruturas de dados que são mais complexas. Mas não vamos considerá-los por enquanto. Digamos apenas que para resolver o problema de construir uma árvore a partir de uma lista ordenada, você pode misturar aleatoriamente os dados de entrada.
Algoritmos de classificação
Existe uma série de números. Precisamos resolver isso. Para simplificar, assumiremos que estamos classificando os inteiros em ordem crescente (do menor para o maior). Existem várias maneiras conhecidas de realizar esse processo. Além disso, você sempre pode inventar o assunto e propor uma modificação no algoritmo.
Classificando por seleção
A ideia principal é dividir nossa lista em duas partes, ordenada e não ordenada. A cada passo do algoritmo, um novo número é movido da parte não ordenada para a parte ordenada, e assim por diante, até que todos os números estejam na parte ordenada.
Encontre o valor mínimo não classificado.
Trocamos esse valor pelo primeiro valor não classificado, colocando-o no final do array classificado.
Se ainda restarem valores não classificados, volte para a etapa 1.
Na primeira etapa, todos os valores não são classificados. Vamos chamar a parte não classificada de Unsorted e a parte classificada de Sorted (essas são apenas palavras em inglês, e fazemos isso apenas porque Sorted é muito mais curto que “Parte classificada” e ficará melhor nas fotos). Encontramos o número mínimo na parte não classificada do array (ou seja, nesta etapa - em todo o array). Este número é 2. Agora vamos trocá-lo pelo primeiro entre os não classificados e colocá-lo no final do array ordenado (nesta etapa - em primeiro lugar). Nesta etapa, este é o primeiro número do array, ou seja, 3. Etapa dois. Não olhamos para o número 2; ele já está na submatriz ordenada. Começamos a procurar o mínimo, a partir do segundo elemento, que é 5. Certificamo-nos de que 3 é o mínimo entre os não ordenados, 5 é o primeiro entre os não ordenados. Nós os trocamos e adicionamos 3 ao subarray classificado. Na terceira etapa , vemos que o menor número na submatriz não classificada é 4. Nós o trocamos pelo primeiro número entre os não classificados - 5. Na quarta etapa, descobrimos que na matriz não classificada o menor número é 5. Nós o alteramos de 6 e o adicionamos ao subarray classificado. Quando resta apenas um número entre os não classificados (o maior), isso significa que todo o array está classificado! Esta é a aparência da implementação do array no código. Experimente fazer você mesmo. Tanto no melhor quanto no pior caso, para encontrar o elemento mínimo não classificado, devemos comparar cada elemento com cada elemento do array não classificado, e faremos isso a cada iteração. Mas não precisamos visualizar a lista inteira, mas apenas a parte não classificada. Isso altera a velocidade do algoritmo? Na primeira etapa, para um array de 5 elementos, fazemos 4 comparações, na segunda - 3, na terceira - 2. Para obter o número de comparações, precisamos somar todos esses números. Obtemos a soma. Assim, a velocidade esperada do algoritmo no melhor e no pior caso é Θ(n 2 ). Não é o algoritmo mais eficiente! No entanto, para fins educacionais e para pequenos conjuntos de dados é bastante aplicável.
Tipo de bolha
O algoritmo de classificação por bolha é um dos mais simples. Percorremos todo o array e comparamos 2 elementos vizinhos. Se estiverem na ordem errada, nós os trocamos. Na primeira passagem, o menor elemento aparecerá (“float”) no final (se ordenarmos em ordem decrescente). Repita a primeira etapa se pelo menos uma troca foi concluída na etapa anterior. Vamos classificar o array. Etapa 1: percorra a matriz. O algoritmo começa com os dois primeiros elementos, 8 e 6, e verifica se estão na ordem correta. 8 > 6, então nós os trocamos. A seguir olhamos para o segundo e terceiro elementos, agora são 8 e 4. Pelas mesmas razões, nós os trocamos. Pela terceira vez comparamos 8 e 2. No total, fazemos três trocas (8, 6), (8, 4), (8, 2). O valor 8 “flutuou” até o final da lista na posição correta. Etapa 2: troque (6,4) e (6,2). 6 está agora na penúltima posição e não há necessidade de compará-lo com a “cauda” já ordenada da lista. Passo 3: troque 4 e 2. Os quatro “flutuam” para seu devido lugar. Passo 4: percorremos o array, mas não temos nada para mudar. Isso sinaliza que a matriz está completamente classificada. E este é o código do algoritmo. Tente implementá-lo em C! A classificação por bolha leva tempo O(n 2 ) no pior caso (todos os números estão errados), pois precisamos executar n etapas em cada iteração, das quais também existem n. Na verdade, como no caso do algoritmo de ordenação por seleção, o tempo será um pouco menor (n 2/2 – n/2), mas isso pode ser desprezado. Na melhor das hipóteses (se todos os elementos já estiverem instalados), podemos fazer isso em n etapas, ou seja, Ω(n), já que precisaremos apenas percorrer o array uma vez e ter certeza de que todos os elementos estão no lugar (ou seja, até mesmo n-1 elementos).
Classificação de inserção
A ideia principal deste algoritmo é dividir nosso array em duas partes, ordenada e não ordenada. Em cada etapa do algoritmo, o número passa da parte não classificada para a parte classificada. Vejamos como funciona a classificação por inserção usando o exemplo abaixo. Antes de começarmos, todos os elementos são considerados não classificados. Etapa 1: pegue o primeiro valor não classificado (3) e insira-o no subarray classificado. Nesta etapa, todo o subarray classificado, seu início e fim serão estes mesmos três. Etapa 2: Como 3> 5, inseriremos 5 no subarray classificado à direita de 3. Etapa 3: Agora trabalhamos na inserção do número 2 em nosso array classificado. Comparamos 2 com valores da direita para a esquerda para encontrar a posição correta. Desde 2 <5 e 2 <3 e chegamos ao início do subarray classificado. Portanto, devemos inserir 2 à esquerda de 3. Para isso, mova 3 e 5 para a direita para que haja espaço para o 2 e insira-o no início do array. Passo 4. Temos sorte: 6 > 5, então podemos inserir esse número logo após o número 5. Passo 5. 4 < 6 e 4 < 5, mas 4 > 3. Portanto, sabemos que 4 deve ser inserido para à direita de 3. Novamente, somos forçados a mover 5 e 6 para a direita para criar uma lacuna para 4. Pronto! Algoritmo generalizado: pegue cada elemento não classificado de n e compare-o com os valores no subarray classificado da direita para a esquerda até encontrar uma posição adequada para n (ou seja, o momento em que encontramos o primeiro número menor que n) . Em seguida, deslocamos todos os elementos classificados que estão à direita desse número para a direita para abrir espaço para o nosso n, e o inserimos lá, expandindo assim a parte classificada do array. Para cada elemento não classificado n você precisa:
Determine o local na parte classificada do array onde n deve ser inserido
Desloque os elementos classificados para a direita para criar uma lacuna para n
Insira n na lacuna resultante na parte classificada da matriz.
E aqui está o código! Recomendamos escrever sua própria versão do programa de classificação.
Velocidade assintótica do algoritmo
Na pior das hipóteses, faremos uma comparação com o segundo elemento, duas comparações com o terceiro e assim por diante. Portanto, nossa velocidade é O(n 2 ). Na melhor das hipóteses, estaremos trabalhando com um array já ordenado. A parte ordenada, que construímos da esquerda para a direita sem inserções e movimentos de elementos, levará um tempo Ω(n).
Mesclar classificação
Este algoritmo é recursivo; ele divide um grande problema de classificação em subtarefas, cuja execução o aproxima da solução do grande problema original. A ideia principal é dividir um array não classificado em duas partes e classificar as metades individuais recursivamente. Digamos que temos n elementos para classificar. Se n <2, terminamos a classificação, caso contrário, classificamos as partes esquerda e direita do array separadamente e depois as combinamos. Vamos classificar o array. Divida-o em duas partes e continue dividindo até obtermos subarrays de tamanho 1, que estão obviamente classificados. Duas submatrizes classificadas podem ser mescladas em tempo O(n) usando um algoritmo simples: remova o número menor no início de cada submatriz e insira-o na matriz mesclada. Repita até que todos os elementos desapareçam. A classificação por mesclagem leva tempo O (nlog n) para todos os casos. Enquanto dividimos os arrays em metades em cada nível de recursão, obtemos log n. Então, mesclar as submatrizes requer apenas n comparações. Portanto O(nlog n). O melhor e o pior caso para classificação por mesclagem são os mesmos, o tempo de execução esperado do algoritmo = Θ (nlog n). Este algoritmo é o mais eficaz entre os considerados.
 Mas em algum momento a função quadrática ultrapassará a linear, não há como evitar isso. Outra complexidade assintótica é o tempo logarítmico ou O(log n). À medida que n aumenta, esta função aumenta muito lentamente. O(log n) é o tempo de execução do algoritmo clássico de busca binária em uma matriz ordenada (lembra da lista telefônica rasgada na palestra?). O array é dividido em dois, então é selecionada a metade em que o elemento está localizado, e assim, cada vez reduzindo a área de busca pela metade, buscamos o elemento.
Mas em algum momento a função quadrática ultrapassará a linear, não há como evitar isso. Outra complexidade assintótica é o tempo logarítmico ou O(log n). À medida que n aumenta, esta função aumenta muito lentamente. O(log n) é o tempo de execução do algoritmo clássico de busca binária em uma matriz ordenada (lembra da lista telefônica rasgada na palestra?). O array é dividido em dois, então é selecionada a metade em que o elemento está localizado, e assim, cada vez reduzindo a área de busca pela metade, buscamos o elemento.  O que acontece se tropeçarmos imediatamente no que procuramos, dividindo nossa matriz de dados ao meio pela primeira vez? Existe um termo para o melhor momento - Omega-grande ou Ω(n). No caso de busca binária = Ω(1) (encontra em tempo constante, independente do tamanho do array). A pesquisa linear é executada em tempo O(n) e Ω(1) se o elemento que está sendo pesquisado for o primeiro. Outro símbolo é teta (Θ(n)). É usado quando as melhores e piores opções são iguais. Isso é adequado para um exemplo em que armazenamos o comprimento de uma string em uma variável separada, portanto, para qualquer comprimento, é suficiente referir-se a essa variável. Para este algoritmo, o melhor e o pior caso são Ω(1) e O(1), respectivamente. Isso significa que o algoritmo é executado no tempo Θ(1).
O que acontece se tropeçarmos imediatamente no que procuramos, dividindo nossa matriz de dados ao meio pela primeira vez? Existe um termo para o melhor momento - Omega-grande ou Ω(n). No caso de busca binária = Ω(1) (encontra em tempo constante, independente do tamanho do array). A pesquisa linear é executada em tempo O(n) e Ω(1) se o elemento que está sendo pesquisado for o primeiro. Outro símbolo é teta (Θ(n)). É usado quando as melhores e piores opções são iguais. Isso é adequado para um exemplo em que armazenamos o comprimento de uma string em uma variável separada, portanto, para qualquer comprimento, é suficiente referir-se a essa variável. Para este algoritmo, o melhor e o pior caso são Ω(1) e O(1), respectivamente. Isso significa que o algoritmo é executado no tempo Θ(1).
 função linearSearch recebe dois argumentos como entrada - a chave key e o array array[]. A chave é o valor desejado, no exemplo anterior key = 0. O array é uma lista de números que nós vai dar uma olhada. Se não encontrarmos nada, a função retornará -1 (uma posição que não existe no array). Se a busca linear encontrar o elemento desejado, a função retornará a posição em que o elemento desejado está localizado no array. O bom da pesquisa linear é que ela funcionará para qualquer array, independentemente da ordem dos elementos: ainda percorreremos todo o array. Esta é também a sua fraqueza. Se você precisar encontrar o número 198 em uma matriz de 200 números classificados em ordem, o loop for passará por 198 etapas.
função linearSearch recebe dois argumentos como entrada - a chave key e o array array[]. A chave é o valor desejado, no exemplo anterior key = 0. O array é uma lista de números que nós vai dar uma olhada. Se não encontrarmos nada, a função retornará -1 (uma posição que não existe no array). Se a busca linear encontrar o elemento desejado, a função retornará a posição em que o elemento desejado está localizado no array. O bom da pesquisa linear é que ela funcionará para qualquer array, independentemente da ordem dos elementos: ainda percorreremos todo o array. Esta é também a sua fraqueza. Se você precisar encontrar o número 198 em uma matriz de 200 números classificados em ordem, o loop for passará por 198 etapas.  Você provavelmente já adivinhou qual método funciona melhor para um array ordenado?
Você provavelmente já adivinhou qual método funciona melhor para um array ordenado?

 Linearmente levaria muito tempo. E se usarmos o “método de dividir o diretório ao meio”, chegaremos direto ao Jasmine e poderemos descartar com segurança a primeira metade da lista, percebendo que Mickey não pode estar lá.
Linearmente levaria muito tempo. E se usarmos o “método de dividir o diretório ao meio”, chegaremos direto ao Jasmine e poderemos descartar com segurança a primeira metade da lista, percebendo que Mickey não pode estar lá.  Usando o mesmo princípio, descartamos a segunda coluna. Continuando esta estratégia, encontraremos o Mickey em apenas alguns passos.
Usando o mesmo princípio, descartamos a segunda coluna. Continuando esta estratégia, encontraremos o Mickey em apenas alguns passos.  Vamos encontrar o número 144. Dividimos a lista ao meio e chegamos ao número 13. Avaliamos se o número que procuramos é maior ou menor que 13. 13
Vamos encontrar o número 144. Dividimos a lista ao meio e chegamos ao número 13. Avaliamos se o número que procuramos é maior ou menor que 13. 13  < 144, para que possamos ignorar tudo à esquerda de 13 e este próprio número. Agora nossa lista de pesquisa fica assim:
< 144, para que possamos ignorar tudo à esquerda de 13 e este próprio número. Agora nossa lista de pesquisa fica assim: 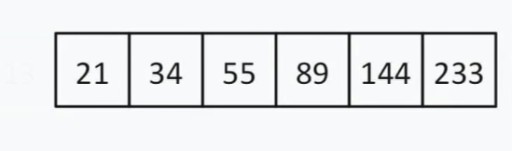 Há um número par de elementos, então escolhemos o princípio pelo qual selecionamos o “meio” (mais próximo do início ou do fim). Digamos que escolhemos a estratégia de proximidade ao início. Neste caso, nosso “meio” = 55.
Há um número par de elementos, então escolhemos o princípio pelo qual selecionamos o “meio” (mais próximo do início ou do fim). Digamos que escolhemos a estratégia de proximidade ao início. Neste caso, nosso “meio” = 55.  55 < 144. Descartamos novamente a metade esquerda da lista. Felizmente para nós, o próximo número médio é 144.
55 < 144. Descartamos novamente a metade esquerda da lista. Felizmente para nós, o próximo número médio é 144.  Encontramos 144 em uma matriz de 13 elementos usando pesquisa binária em apenas três etapas. Uma pesquisa linear resolveria a mesma situação em até 12 etapas. Como este algoritmo reduz pela metade o número de elementos no array a cada passo, ele encontrará o necessário em um tempo assintótico O (log n), onde n é o número de elementos na lista. Ou seja, no nosso caso, o tempo assintótico = O(log 13) (isto é um pouco mais que três). Pseudocódigo da função de pesquisa binária:
Encontramos 144 em uma matriz de 13 elementos usando pesquisa binária em apenas três etapas. Uma pesquisa linear resolveria a mesma situação em até 12 etapas. Como este algoritmo reduz pela metade o número de elementos no array a cada passo, ele encontrará o necessário em um tempo assintótico O (log n), onde n é o número de elementos na lista. Ou seja, no nosso caso, o tempo assintótico = O(log 13) (isto é um pouco mais que três). Pseudocódigo da função de pesquisa binária: 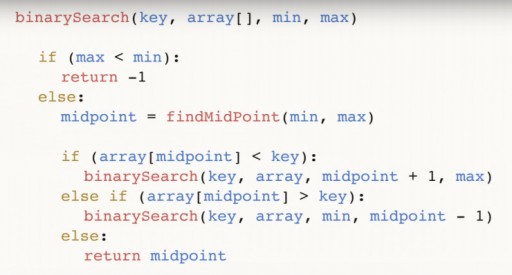 A função recebe 4 argumentos como entrada: a chave desejada, o array de dados array [], no qual o desejado está localizado, min e max são ponteiros para o número máximo e mínimo no array, que estamos examinando esta etapa do algoritmo. Para o nosso exemplo, inicialmente foi fornecida a seguinte imagem:
A função recebe 4 argumentos como entrada: a chave desejada, o array de dados array [], no qual o desejado está localizado, min e max são ponteiros para o número máximo e mínimo no array, que estamos examinando esta etapa do algoritmo. Para o nosso exemplo, inicialmente foi fornecida a seguinte imagem:  Vamos analisar o código mais detalhadamente. ponto médio é o nosso meio do array. Depende dos pontos extremos e está centrado entre eles. Depois de encontrarmos o meio, verificamos se é menor que o nosso número chave.
Vamos analisar o código mais detalhadamente. ponto médio é o nosso meio do array. Depende dos pontos extremos e está centrado entre eles. Depois de encontrarmos o meio, verificamos se é menor que o nosso número chave.  Nesse caso, então a chave também é maior que qualquer um dos números à esquerda do meio, e podemos chamar a função binária novamente, só que agora nosso min = ponto médio + 1. Se acontecer que chave < ponto médio, podemos descartar esse número em si e todos os números, à sua direita. E chamamos uma pesquisa binária através do array do número mínimo até o valor (ponto médio – 1).
Nesse caso, então a chave também é maior que qualquer um dos números à esquerda do meio, e podemos chamar a função binária novamente, só que agora nosso min = ponto médio + 1. Se acontecer que chave < ponto médio, podemos descartar esse número em si e todos os números, à sua direita. E chamamos uma pesquisa binária através do array do número mínimo até o valor (ponto médio – 1).  Finalmente, o terceiro ramo: se o valor no ponto médio não for maior nem menor que a chave, não há escolha senão ser o número desejado. Neste caso, devolvemos e finalizamos o programa.
Finalmente, o terceiro ramo: se o valor no ponto médio não for maior nem menor que a chave, não há escolha senão ser o número desejado. Neste caso, devolvemos e finalizamos o programa.  Finalmente, pode acontecer que o número que você está procurando não esteja na matriz. Para levar este caso em consideração, realizamos a seguinte verificação:
Finalmente, pode acontecer que o número que você está procurando não esteja na matriz. Para levar este caso em consideração, realizamos a seguinte verificação:  E retornamos (-1) para indicar que não encontramos nada. Você já sabe que a pesquisa binária requer que o array seja classificado. Assim, se tivermos um array não classificado no qual precisamos encontrar um determinado elemento, temos duas opções:
E retornamos (-1) para indicar que não encontramos nada. Você já sabe que a pesquisa binária requer que o array seja classificado. Assim, se tivermos um array não classificado no qual precisamos encontrar um determinado elemento, temos duas opções:
 Atenção: a raiz da árvore do “programador”, ao contrário da real, está no topo. Cada célula é chamada de vértice e os vértices são conectados por arestas. A raiz da árvore é a célula número 13. A subárvore esquerda do vértice 3 está destacada em cores na figura abaixo:
Atenção: a raiz da árvore do “programador”, ao contrário da real, está no topo. Cada célula é chamada de vértice e os vértices são conectados por arestas. A raiz da árvore é a célula número 13. A subárvore esquerda do vértice 3 está destacada em cores na figura abaixo: 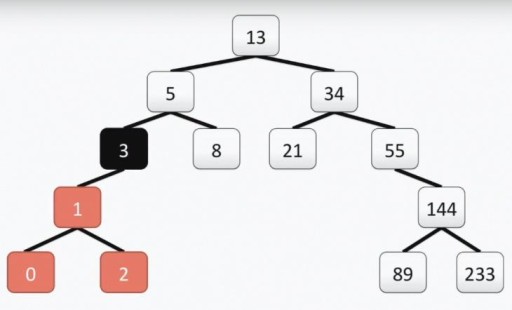 Nossa árvore atende a todos os requisitos para árvores binárias. Isso significa que cada uma de suas subárvores esquerdas contém apenas valores menores ou iguais ao valor do vértice, enquanto a subárvore direita contém apenas valores maiores ou iguais ao valor do vértice. As subárvores esquerda e direita são subárvores binárias. O método de construção de uma árvore binária não é o único: abaixo na imagem você vê outra opção para o mesmo conjunto de números, e pode haver muitos deles na prática.
Nossa árvore atende a todos os requisitos para árvores binárias. Isso significa que cada uma de suas subárvores esquerdas contém apenas valores menores ou iguais ao valor do vértice, enquanto a subárvore direita contém apenas valores maiores ou iguais ao valor do vértice. As subárvores esquerda e direita são subárvores binárias. O método de construção de uma árvore binária não é o único: abaixo na imagem você vê outra opção para o mesmo conjunto de números, e pode haver muitos deles na prática.  Esta estrutura ajuda a realizar a pesquisa: encontramos o valor mínimo movendo de cima para a esquerda e para baixo a cada vez.
Esta estrutura ajuda a realizar a pesquisa: encontramos o valor mínimo movendo de cima para a esquerda e para baixo a cada vez. 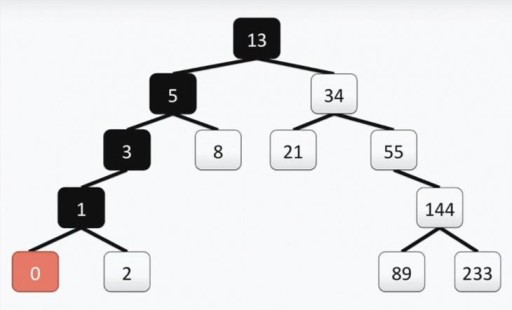 Se você precisar encontrar o número máximo, vamos de cima para baixo e para a direita. Encontrar um número que não seja mínimo ou máximo também é bastante simples. Descemos da raiz para a esquerda ou para a direita, dependendo se o nosso vértice é maior ou menor que o que procuramos. Então, se precisarmos encontrar o número 89, seguimos este caminho:
Se você precisar encontrar o número máximo, vamos de cima para baixo e para a direita. Encontrar um número que não seja mínimo ou máximo também é bastante simples. Descemos da raiz para a esquerda ou para a direita, dependendo se o nosso vértice é maior ou menor que o que procuramos. Então, se precisarmos encontrar o número 89, seguimos este caminho:  Você também pode exibir os números em ordem de classificação. Por exemplo, se precisarmos exibir todos os números em ordem crescente, pegamos a subárvore esquerda e, começando no vértice mais à esquerda, subimos. Adicionar algo à árvore também é fácil. A principal coisa a lembrar é a estrutura. Digamos que precisamos adicionar à árvore o valor 7. Vamos até a raiz e verificamos. O número 7 <13, então vamos para a esquerda. Vemos 5 ali e vamos para a direita, já que 7 > 5. Além disso, como 7 > 8 e 8 não tem descendentes, construímos um ramo de 8 para a esquerda e anexamos 7 a ele. Você também pode remover vértices
Você também pode exibir os números em ordem de classificação. Por exemplo, se precisarmos exibir todos os números em ordem crescente, pegamos a subárvore esquerda e, começando no vértice mais à esquerda, subimos. Adicionar algo à árvore também é fácil. A principal coisa a lembrar é a estrutura. Digamos que precisamos adicionar à árvore o valor 7. Vamos até a raiz e verificamos. O número 7 <13, então vamos para a esquerda. Vemos 5 ali e vamos para a direita, já que 7 > 5. Além disso, como 7 > 8 e 8 não tem descendentes, construímos um ramo de 8 para a esquerda e anexamos 7 a ele. Você também pode remover vértices 
 de a árvore, mas isso é um pouco mais complicado. Existem três cenários de exclusão diferentes que precisamos considerar.
de a árvore, mas isso é um pouco mais complicado. Existem três cenários de exclusão diferentes que precisamos considerar.



 Todos os números serão simplesmente adicionados ao ramo direito do anterior. Se quisermos encontrar um número, não teremos escolha senão simplesmente seguir a cadeia para baixo.
Todos os números serão simplesmente adicionados ao ramo direito do anterior. Se quisermos encontrar um número, não teremos escolha senão simplesmente seguir a cadeia para baixo.  Não é melhor que a pesquisa linear. Existem outras estruturas de dados que são mais complexas. Mas não vamos considerá-los por enquanto. Digamos apenas que para resolver o problema de construir uma árvore a partir de uma lista ordenada, você pode misturar aleatoriamente os dados de entrada.
Não é melhor que a pesquisa linear. Existem outras estruturas de dados que são mais complexas. Mas não vamos considerá-los por enquanto. Digamos apenas que para resolver o problema de construir uma árvore a partir de uma lista ordenada, você pode misturar aleatoriamente os dados de entrada.
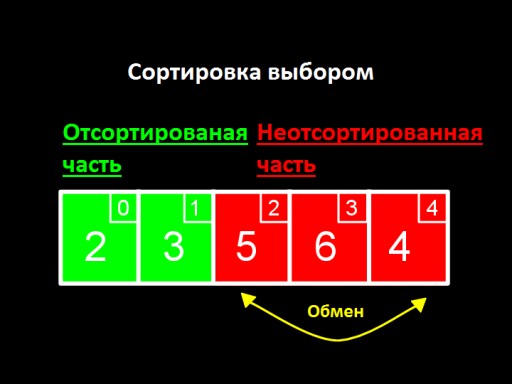 A ideia principal é dividir nossa lista em duas partes, ordenada e não ordenada. A cada passo do algoritmo, um novo número é movido da parte não ordenada para a parte ordenada, e assim por diante, até que todos os números estejam na parte ordenada.
A ideia principal é dividir nossa lista em duas partes, ordenada e não ordenada. A cada passo do algoritmo, um novo número é movido da parte não ordenada para a parte ordenada, e assim por diante, até que todos os números estejam na parte ordenada.
 Encontramos o número mínimo na parte não classificada do array (ou seja, nesta etapa - em todo o array). Este número é 2. Agora vamos trocá-lo pelo primeiro entre os não classificados e colocá-lo no final do array ordenado (nesta etapa - em primeiro lugar). Nesta etapa, este é o primeiro número do array, ou seja, 3.
Encontramos o número mínimo na parte não classificada do array (ou seja, nesta etapa - em todo o array). Este número é 2. Agora vamos trocá-lo pelo primeiro entre os não classificados e colocá-lo no final do array ordenado (nesta etapa - em primeiro lugar). Nesta etapa, este é o primeiro número do array, ou seja, 3.  Etapa dois. Não olhamos para o número 2; ele já está na submatriz ordenada. Começamos a procurar o mínimo, a partir do segundo elemento, que é 5. Certificamo-nos de que 3 é o mínimo entre os não ordenados, 5 é o primeiro entre os não ordenados. Nós os trocamos e adicionamos 3 ao subarray classificado.
Etapa dois. Não olhamos para o número 2; ele já está na submatriz ordenada. Começamos a procurar o mínimo, a partir do segundo elemento, que é 5. Certificamo-nos de que 3 é o mínimo entre os não ordenados, 5 é o primeiro entre os não ordenados. Nós os trocamos e adicionamos 3 ao subarray classificado.  Na terceira etapa , vemos que o menor número na submatriz não classificada é 4. Nós o trocamos pelo primeiro número entre os não classificados - 5.
Na terceira etapa , vemos que o menor número na submatriz não classificada é 4. Nós o trocamos pelo primeiro número entre os não classificados - 5.  Na quarta etapa, descobrimos que na matriz não classificada o menor número é 5. Nós o alteramos de 6 e o adicionamos ao subarray classificado.
Na quarta etapa, descobrimos que na matriz não classificada o menor número é 5. Nós o alteramos de 6 e o adicionamos ao subarray classificado. 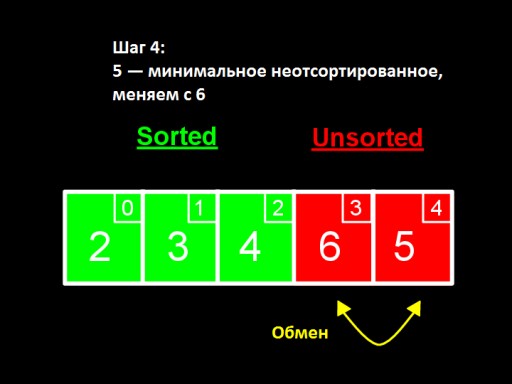 Quando resta apenas um número entre os não classificados (o maior), isso significa que todo o array está classificado!
Quando resta apenas um número entre os não classificados (o maior), isso significa que todo o array está classificado! 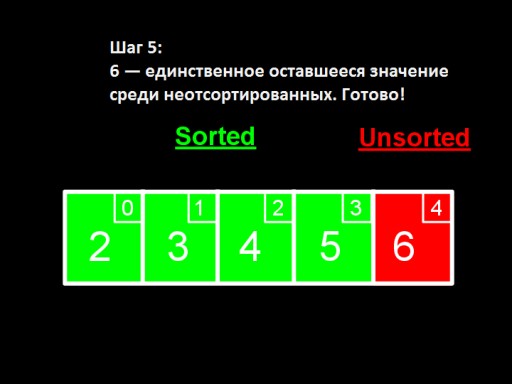 Esta é a aparência da implementação do array no código. Experimente fazer você mesmo.
Esta é a aparência da implementação do array no código. Experimente fazer você mesmo.  Tanto no melhor quanto no pior caso, para encontrar o elemento mínimo não classificado, devemos comparar cada elemento com cada elemento do array não classificado, e faremos isso a cada iteração. Mas não precisamos visualizar a lista inteira, mas apenas a parte não classificada. Isso altera a velocidade do algoritmo? Na primeira etapa, para um array de 5 elementos, fazemos 4 comparações, na segunda - 3, na terceira - 2. Para obter o número de comparações, precisamos somar todos esses números. Obtemos a soma.
Tanto no melhor quanto no pior caso, para encontrar o elemento mínimo não classificado, devemos comparar cada elemento com cada elemento do array não classificado, e faremos isso a cada iteração. Mas não precisamos visualizar a lista inteira, mas apenas a parte não classificada. Isso altera a velocidade do algoritmo? Na primeira etapa, para um array de 5 elementos, fazemos 4 comparações, na segunda - 3, na terceira - 2. Para obter o número de comparações, precisamos somar todos esses números. Obtemos a soma.  Assim, a velocidade esperada do algoritmo no melhor e no pior caso é Θ(n 2 ). Não é o algoritmo mais eficiente! No entanto, para fins educacionais e para pequenos conjuntos de dados é bastante aplicável.
Assim, a velocidade esperada do algoritmo no melhor e no pior caso é Θ(n 2 ). Não é o algoritmo mais eficiente! No entanto, para fins educacionais e para pequenos conjuntos de dados é bastante aplicável.
 Etapa 1: percorra a matriz. O algoritmo começa com os dois primeiros elementos, 8 e 6, e verifica se estão na ordem correta. 8 > 6, então nós os trocamos. A seguir olhamos para o segundo e terceiro elementos, agora são 8 e 4. Pelas mesmas razões, nós os trocamos. Pela terceira vez comparamos 8 e 2. No total, fazemos três trocas (8, 6), (8, 4), (8, 2). O valor 8 “flutuou” até o final da lista na posição correta.
Etapa 1: percorra a matriz. O algoritmo começa com os dois primeiros elementos, 8 e 6, e verifica se estão na ordem correta. 8 > 6, então nós os trocamos. A seguir olhamos para o segundo e terceiro elementos, agora são 8 e 4. Pelas mesmas razões, nós os trocamos. Pela terceira vez comparamos 8 e 2. No total, fazemos três trocas (8, 6), (8, 4), (8, 2). O valor 8 “flutuou” até o final da lista na posição correta.  Etapa 2: troque (6,4) e (6,2). 6 está agora na penúltima posição e não há necessidade de compará-lo com a “cauda” já ordenada da lista.
Etapa 2: troque (6,4) e (6,2). 6 está agora na penúltima posição e não há necessidade de compará-lo com a “cauda” já ordenada da lista.  Passo 3: troque 4 e 2. Os quatro “flutuam” para seu devido lugar.
Passo 3: troque 4 e 2. Os quatro “flutuam” para seu devido lugar.  Passo 4: percorremos o array, mas não temos nada para mudar. Isso sinaliza que a matriz está completamente classificada.
Passo 4: percorremos o array, mas não temos nada para mudar. Isso sinaliza que a matriz está completamente classificada. 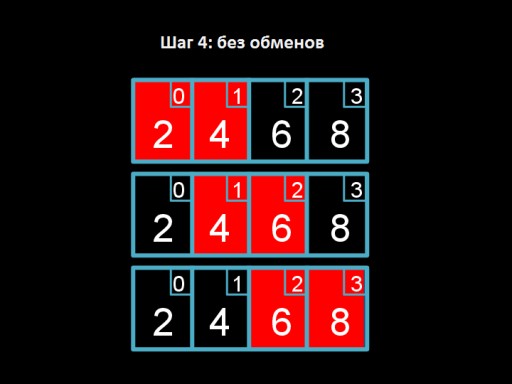 E este é o código do algoritmo. Tente implementá-lo em C!
E este é o código do algoritmo. Tente implementá-lo em C!  A classificação por bolha leva tempo O(n 2 ) no pior caso (todos os números estão errados), pois precisamos executar n etapas em cada iteração, das quais também existem n. Na verdade, como no caso do algoritmo de ordenação por seleção, o tempo será um pouco menor (n 2/2 – n/2), mas isso pode ser desprezado. Na melhor das hipóteses (se todos os elementos já estiverem instalados), podemos fazer isso em n etapas, ou seja, Ω(n), já que precisaremos apenas percorrer o array uma vez e ter certeza de que todos os elementos estão no lugar (ou seja, até mesmo n-1 elementos).
A classificação por bolha leva tempo O(n 2 ) no pior caso (todos os números estão errados), pois precisamos executar n etapas em cada iteração, das quais também existem n. Na verdade, como no caso do algoritmo de ordenação por seleção, o tempo será um pouco menor (n 2/2 – n/2), mas isso pode ser desprezado. Na melhor das hipóteses (se todos os elementos já estiverem instalados), podemos fazer isso em n etapas, ou seja, Ω(n), já que precisaremos apenas percorrer o array uma vez e ter certeza de que todos os elementos estão no lugar (ou seja, até mesmo n-1 elementos).
 Vejamos como funciona a classificação por inserção usando o exemplo abaixo. Antes de começarmos, todos os elementos são considerados não classificados.
Vejamos como funciona a classificação por inserção usando o exemplo abaixo. Antes de começarmos, todos os elementos são considerados não classificados.  Etapa 1: pegue o primeiro valor não classificado (3) e insira-o no subarray classificado. Nesta etapa, todo o subarray classificado, seu início e fim serão estes mesmos três.
Etapa 1: pegue o primeiro valor não classificado (3) e insira-o no subarray classificado. Nesta etapa, todo o subarray classificado, seu início e fim serão estes mesmos três.  Etapa 2: Como 3> 5, inseriremos 5 no subarray classificado à direita de 3.
Etapa 2: Como 3> 5, inseriremos 5 no subarray classificado à direita de 3.  Etapa 3: Agora trabalhamos na inserção do número 2 em nosso array classificado. Comparamos 2 com valores da direita para a esquerda para encontrar a posição correta. Desde 2 <5 e 2 <3 e chegamos ao início do subarray classificado. Portanto, devemos inserir 2 à esquerda de 3. Para isso, mova 3 e 5 para a direita para que haja espaço para o 2 e insira-o no início do array.
Etapa 3: Agora trabalhamos na inserção do número 2 em nosso array classificado. Comparamos 2 com valores da direita para a esquerda para encontrar a posição correta. Desde 2 <5 e 2 <3 e chegamos ao início do subarray classificado. Portanto, devemos inserir 2 à esquerda de 3. Para isso, mova 3 e 5 para a direita para que haja espaço para o 2 e insira-o no início do array.  Passo 4. Temos sorte: 6 > 5, então podemos inserir esse número logo após o número 5.
Passo 4. Temos sorte: 6 > 5, então podemos inserir esse número logo após o número 5.  Passo 5. 4 < 6 e 4 < 5, mas 4 > 3. Portanto, sabemos que 4 deve ser inserido para à direita de 3. Novamente, somos forçados a mover 5 e 6 para a direita para criar uma lacuna para 4.
Passo 5. 4 < 6 e 4 < 5, mas 4 > 3. Portanto, sabemos que 4 deve ser inserido para à direita de 3. Novamente, somos forçados a mover 5 e 6 para a direita para criar uma lacuna para 4.  Pronto! Algoritmo generalizado: pegue cada elemento não classificado de n e compare-o com os valores no subarray classificado da direita para a esquerda até encontrar uma posição adequada para n (ou seja, o momento em que encontramos o primeiro número menor que n) . Em seguida, deslocamos todos os elementos classificados que estão à direita desse número para a direita para abrir espaço para o nosso n, e o inserimos lá, expandindo assim a parte classificada do array. Para cada elemento não classificado n você precisa:
Pronto! Algoritmo generalizado: pegue cada elemento não classificado de n e compare-o com os valores no subarray classificado da direita para a esquerda até encontrar uma posição adequada para n (ou seja, o momento em que encontramos o primeiro número menor que n) . Em seguida, deslocamos todos os elementos classificados que estão à direita desse número para a direita para abrir espaço para o nosso n, e o inserimos lá, expandindo assim a parte classificada do array. Para cada elemento não classificado n você precisa:

 Digamos que temos n elementos para classificar. Se n <2, terminamos a classificação, caso contrário, classificamos as partes esquerda e direita do array separadamente e depois as combinamos. Vamos classificar o array.
Digamos que temos n elementos para classificar. Se n <2, terminamos a classificação, caso contrário, classificamos as partes esquerda e direita do array separadamente e depois as combinamos. Vamos classificar o array.  Divida-o em duas partes e continue dividindo até obtermos subarrays de tamanho 1, que estão obviamente classificados.
Divida-o em duas partes e continue dividindo até obtermos subarrays de tamanho 1, que estão obviamente classificados.  Duas submatrizes classificadas podem ser mescladas em tempo O(n) usando um algoritmo simples: remova o número menor no início de cada submatriz e insira-o na matriz mesclada. Repita até que todos os elementos desapareçam.
Duas submatrizes classificadas podem ser mescladas em tempo O(n) usando um algoritmo simples: remova o número menor no início de cada submatriz e insira-o na matriz mesclada. Repita até que todos os elementos desapareçam. 
 A classificação por mesclagem leva tempo O (nlog n) para todos os casos. Enquanto dividimos os arrays em metades em cada nível de recursão, obtemos log n. Então, mesclar as submatrizes requer apenas n comparações. Portanto O(nlog n). O melhor e o pior caso para classificação por mesclagem são os mesmos, o tempo de execução esperado do algoritmo = Θ (nlog n). Este algoritmo é o mais eficaz entre os considerados.
A classificação por mesclagem leva tempo O (nlog n) para todos os casos. Enquanto dividimos os arrays em metades em cada nível de recursão, obtemos log n. Então, mesclar as submatrizes requer apenas n comparações. Portanto O(nlog n). O melhor e o pior caso para classificação por mesclagem são os mesmos, o tempo de execução esperado do algoritmo = Θ (nlog n). Este algoritmo é o mais eficaz entre os considerados. 

GO TO FULL VERSION