A classificação é um dos tipos básicos de atividades ou ações executadas em objetos. Ainda na infância, as crianças são ensinadas a classificar, desenvolvendo o pensamento. Computadores e programas também não são exceção. Existe uma grande variedade de algoritmos. Eu sugiro que você veja o que eles são e como funcionam. Além disso, e se um dia você for questionado sobre um desses itens em uma entrevista?
Introdução
A classificação de elementos é uma das categorias de algoritmos com as quais um desenvolvedor deve se acostumar. Se antigamente, quando eu estudava, a ciência da computação não era levada tão a sério, agora na escola eles deveriam ser capazes de implementar algoritmos de ordenação e entendê-los. Algoritmos básicos, os mais simples, são implementados através de um loop for. Naturalmente, para classificar uma coleção de elementos, por exemplo, um array, você precisa percorrer de alguma forma essa coleção. Por exemplo:
int[] array ={10,2,10,3,1,2,5};for(int i =0; i < array.length; i++){System.out.println(array[i]);}
O que você pode dizer sobre esse trecho de código? Temos um loop no qual alteramos o valor do índice ( int i) de 0 até o último elemento do array. Essencialmente, estamos simplesmente pegando cada elemento do array e imprimindo seu conteúdo. Quanto mais elementos houver no array, mais tempo o código levará para ser executado. Ou seja, se n for o número de elementos, com n=10 o programa demorará 2 vezes mais para ser executado do que com n=5. Quando nosso programa possui um loop, o tempo de execução aumenta linearmente: quanto mais elementos, mais longa será a execução. Acontece que o algoritmo do código acima roda em tempo linear (n). Nesses casos, a “complexidade do algoritmo” é considerada O(n). Essa notação também é chamada de "grande O" ou "comportamento assintótico". Mas você pode simplesmente lembrar “a complexidade do algoritmo”.
A classificação mais simples (Bubble Sort)
Portanto, temos um array e podemos iterá-lo. Ótimo. Vamos agora tentar classificá-lo em ordem crescente. O que isso significa para nós? Isso significa que dados dois elementos (por exemplo, a=6, b=5), devemos trocar a e b se a for maior que b (se a > b). O que isso significa para nós quando trabalhamos com uma coleção por índice (como é o caso de um array)? Isso significa que se o elemento com índice a for maior que o elemento com índice b, (array[a] > array[b]), tais elementos deverão ser trocados. A mudança de lugar costuma ser chamada de troca. Existem várias maneiras de mudar de lugar. Mas usamos um código simples, claro e fácil de lembrar:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);}}System.out.println(Arrays.toString(array));
Como podemos ver, os elementos realmente mudaram de lugar. Começamos com um elemento, porque... se o array consistir em apenas um elemento, a expressão 1 < 1 não retornará verdadeiro e assim nos protegeremos de casos de um array com um elemento ou sem ele, e o código ficará melhor. Mas nosso array final não está classificado de qualquer maneira, porque... Não é possível classificar todos de uma só vez. Teremos que adicionar outro loop no qual realizaremos passagens uma por uma até obtermos um array ordenado:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));boolean needIteration =true;while(needIteration){
needIteration =false;for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);
needIteration =true;}}}System.out.println(Arrays.toString(array));
Então nossa primeira classificação funcionou. Iteramos no loop externo ( while) até decidirmos que não são necessárias mais iterações. Por padrão, antes de cada nova iteração, assumimos que nosso array está classificado e não queremos mais iterar. Portanto, percorremos os elementos sequencialmente e verificamos essa suposição. Mas se os elementos estiverem fora de ordem, trocamos os elementos e percebemos que não temos certeza se os elementos estão agora na ordem correta. Portanto, queremos realizar mais uma iteração. Por exemplo, [3, 5, 2]. 5 é maior que três, está tudo bem. Mas 2 é menor que 5. No entanto, [3, 2, 5] requer mais uma passagem, porque 3 > 2 e eles precisam ser trocados. Como usamos um loop dentro de um loop, a complexidade do nosso algoritmo aumenta. Com n elementos torna-se n * n, ou seja, O(n^2). Essa complexidade é chamada quadrática. Pelo que entendemos, não podemos saber exatamente quantas iterações serão necessárias. O indicador de complexidade do algoritmo serve para mostrar a tendência de aumento da complexidade, no pior caso. Quanto aumentará o tempo de execução quando o número de elementos n mudar. A classificação por bolha é uma das classificações mais simples e ineficientes. Às vezes também é chamada de "classificação estúpida". Materiais relacionados:
Outra classificação é a classificação por seleção. Também possui complexidade quadrática, mas falaremos mais sobre isso mais tarde. Então a ideia é simples. Cada passagem seleciona o menor elemento e o move para o início. Neste caso, inicie cada nova passagem movendo para a direita, ou seja, a primeira passagem - do primeiro elemento, a segunda passagem - do segundo. Isso parecerá assim:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){int minInd = left;for(int i = left; i < array.length; i++){if(array[i]< array[minInd]){
minInd = i;}}swap(array, left, minInd);}System.out.println(Arrays.toString(array));
Essa classificação é instável, porque elementos idênticos (do ponto de vista da característica pela qual classificamos os elementos) podem mudar de posição. Um bom exemplo é dado no artigo da Wikipedia: Sorting_by-selection . Materiais relacionados:
A ordenação por inserção também possui complexidade quadrática, pois novamente temos um loop dentro de um loop. Como é diferente da classificação por seleção? Essa classificação é "estável". Isso significa que elementos idênticos não mudarão sua ordem. Idêntico em termos das características pelas quais classificamos.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){// Retrieve the value of the elementint value = array[left];// Move through the elements that are before the pulled elementint i = left -1;for(; i >=0; i--){// If a smaller value is pulled out, move the larger element furtherif(value < array[i]){
array[i +1]= array[i];}else{// If the pulled element is larger, stopbreak;}}// Insert the extracted value into the freed space
array[i +1]= value;}System.out.println(Arrays.toString(array));
Entre os tipos simples, existe outro - a classificação por transporte. Mas eu prefiro a variedade de transporte. Parece-me que raramente falamos sobre ônibus espaciais, e o ônibus espacial é mais uma corrida. Portanto, é mais fácil imaginar como os ônibus espaciais são lançados ao espaço. Aqui está uma associação com este algoritmo. Qual é a essência do algoritmo? A essência do algoritmo é iterar da esquerda para a direita e, ao trocar elementos, verificamos todos os outros elementos deixados para trás para ver se a troca precisa ser repetida.
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i -1);for(int z = i -1;(z -1)>=0; z--){if(array[z]< array[z -1]){swap(array, z, z -1);}else{break;}}}}System.out.println(Arrays.toString(array));
Outra classificação simples é a classificação Shell. Sua essência é semelhante ao bubble sort, mas a cada iteração temos uma lacuna diferente entre os elementos que estão sendo comparados. Cada iteração é dividido pela metade. Aqui está um exemplo de implementação:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));// Calculate the gap between the checked elementsint gap = array.length /2;// As long as there is a difference between the elementswhile(gap >=1){for(int right =0; right < array.length; right++){// Shift the right pointer until we can find one that// there won't be enough space between it and the element before itfor(int c = right - gap; c >=0; c -= gap){if(array[c]> array[c + gap]){swap(array, c, c + gap);}}}// Recalculate the gap
gap = gap /2;}System.out.println(Arrays.toString(array));
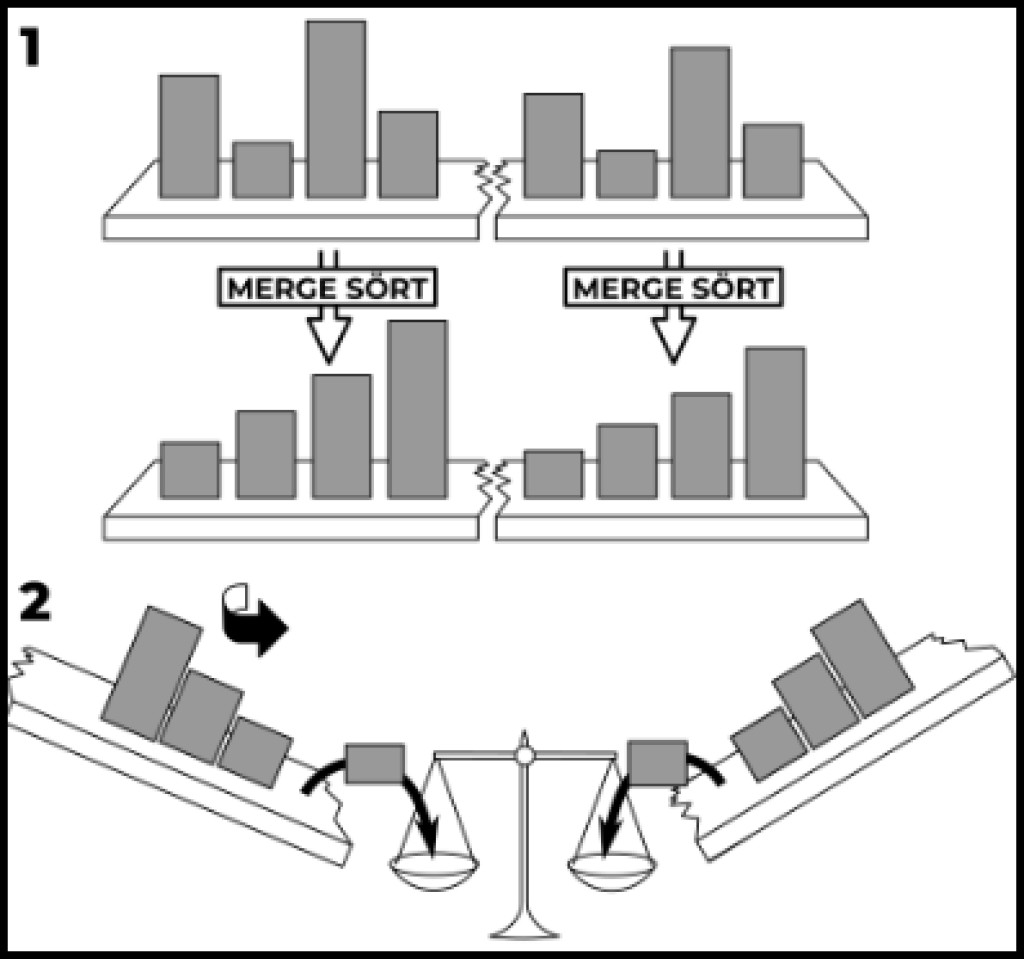
Além das classificações simples indicadas, existem classificações mais complexas. Por exemplo, classificação por mesclagem. Primeiro, a recursão virá em nosso auxílio. Em segundo lugar, a nossa complexidade não será mais quadrática, como estamos habituados. A complexidade deste algoritmo é logarítmica. Escrito como O(n log n). Então vamos fazer isso. Primeiro, vamos escrever uma chamada recursiva para o método de classificação:
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}}
Agora, vamos adicionar uma ação principal a ele. Aqui está um exemplo do nosso supermétodo com implementação:
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}// Create a temporary array with the desired sizeint[] buffer =newint[right - left +1];// Starting from the specified left border, go through each elementint cursor = left;for(int i =0; i < buffer.length; i++){// We use the delimeter to point to the element from the right side// If delimeter > right, then there are no unadded elements left on the right sideif(delimiter > right || source[cursor]> source[delimiter]){
buffer[i]= source[cursor];
cursor++;}else{
buffer[i]= source[delimiter];
delimiter++;}}System.arraycopy(buffer,0, source, left, buffer.length);}
Vamos executar o exemplo chamando o mergeSort(array, 0, array.length-1). Como você pode ver, a essência se resume ao fato de tomarmos como entrada um array indicando o início e o fim da seção a ser ordenada. Quando a classificação começa, este é o início e o fim da matriz. A seguir calculamos o delimitador - a posição do divisor. Se o divisor puder ser dividido em 2 partes, chamaremos classificação recursiva para as seções nas quais o divisor dividiu a matriz. Preparamos um array de buffer adicional no qual selecionamos a seção classificada. A seguir, colocamos o cursor no início da área a ser ordenada e começamos a percorrer cada elemento do array vazio que preparamos e preenchê-lo com os menores elementos. Se o elemento apontado pelo cursor for menor que o elemento apontado pelo divisor, colocamos este elemento no array buffer e movemos o cursor. Caso contrário, colocamos o elemento apontado pelo separador na matriz buffer e movemos o separador. Assim que o separador ultrapassar os limites da área classificada ou preenchermos todo o array, o intervalo especificado será considerado classificado. Materiais relacionados:
Outro algoritmo de classificação interessante é o Counting Sort. A complexidade algorítmica neste caso será O(n+k), onde n é o número de elementos e k é o valor máximo do elemento. Há um problema com o algoritmo: precisamos saber os valores mínimo e máximo do array. Aqui está um exemplo de implementação de classificação por contagem:
publicstaticint[]countingSort(int[] theArray,int maxValue){// Array with "counters" ranging from 0 to the maximum valueint numCounts[]=newint[maxValue +1];// In the corresponding cell (index = value) we increase the counterfor(int num : theArray){
numCounts[num]++;}// Prepare array for sorted resultint[] sortedArray =newint[theArray.length];int currentSortedIndex =0;// go through the array with "counters"for(int n =0; n < numCounts.length; n++){int count = numCounts[n];// go by the number of valuesfor(int k =0; k < count; k++){
sortedArray[currentSortedIndex]= n;
currentSortedIndex++;}}return sortedArray;}
Pelo que entendemos, é muito inconveniente quando temos que saber antecipadamente os valores mínimos e máximos. E há outro algoritmo - Radix Sort. Apresentarei o algoritmo aqui apenas visualmente. Para implementação, consulte os materiais:
Bem, para a sobremesa - um dos algoritmos mais famosos: classificação rápida. Possui complexidade algorítmica, ou seja, temos O(n log n). Essa classificação também é chamada de classificação Hoare. Curiosamente, o algoritmo foi inventado por Hoare durante sua estada na União Soviética, onde estudou tradução computacional na Universidade de Moscou e estava desenvolvendo um livro de frases russo-inglês. Este algoritmo também é usado em uma implementação mais complexa em Arrays.sort em Java. E quanto a Collections.sort? Eu sugiro que você veja por si mesmo como eles são classificados “nos bastidores”. Então, o código:
publicstaticvoidquickSort(int[] source,int leftBorder,int rightBorder){int leftMarker = leftBorder;int rightMarker = rightBorder;int pivot = source[(leftMarker + rightMarker)/2];do{// Move the left marker from left to right while element is less than pivotwhile(source[leftMarker]< pivot){
leftMarker++;}// Move the right marker until element is greater than pivotwhile(source[rightMarker]> pivot){
rightMarker--;}// Check if you don't need to swap elements pointed to by markersif(leftMarker <= rightMarker){// The left marker will only be less than the right marker if we have to swapif(leftMarker < rightMarker){int tmp = source[leftMarker];
source[leftMarker]= source[rightMarker];
source[rightMarker]= tmp;}// Move markers to get new borders
leftMarker++;
rightMarker--;}}while(leftMarker <= rightMarker);// Execute recursively for partsif(leftMarker < rightBorder){quickSort(source, leftMarker, rightBorder);}if(leftBorder < rightMarker){quickSort(source, leftBorder, rightMarker);}}
Tudo aqui é muito assustador, então vamos descobrir. Para a int[]fonte do array de entrada, definimos dois marcadores, esquerdo (L) e direito (R). Quando chamados pela primeira vez, eles correspondem ao início e ao fim do array. Em seguida, é determinado o elemento de suporte, também conhecido como pivot. Depois disso, nossa tarefa é mover os valores menores que pivotpara a esquerda pivote os maiores para a direita. Para fazer isso, primeiro mova o ponteiro Laté encontrar um valor maior que pivot. Se um valor menor não for encontrado, então
L совпадёт с
pivot. Потом двигаем указатель
R пока не найдём меньшее, чем
pivot meaning. Если меньшее meaning не нашли, то
R совпадёт с
pivot. Далее, если указатель
L находится до указателя
R or совпадает с ним, то пытаемся выполнить обмен элементов, если элемент
L меньше, чем
R. Далее
L сдвигаем вправо на 1 позицию,
R сдвигаем влево на одну позицию. Когда левый маркер
L окажется за правым маркером
R это будет означать, что обмен закончен, слева от
pivot меньшие значения, справа от
pivot — большие значения. После этого рекурсивно вызываем такую же сортировку для участков массива от начала сортируемого участка до правого маркера и от левого маркера до конца сортируемого участка. Почему от начала до правого? Потому что в конце итерации так и получится, что правый маркер сдвинется настолько, что станет границей части слева. Этот алгоритм более сложный, чем простая sorting, поэтому его лучше зарисовать. Возьмём белый лист бумаги, запишем: 4 2 6 7 3 , а
Pivot по центру, т.е. число 6. Обведём его в круг. Под 4 напишем
L, под 3 напишем
R. 4 меньше чем 6, 2 меньше чем 6. Total,
L переместился на положение
pivot, т.к. по условию
L не может уйти дальше, чем
pivot. Напишем снова 4 2 6 7 3 , обведём 6 вкруг (
pivot) и поставим под ним
L. Теперь двигаем указатель
R. 3 меньше чем 6, поэтому ставим маркер
R на цифру 3. Так How 3 меньше, чем
pivot 6 выполняем
swap, т.е. обмен. Запишем результат: 4 2 3 7 6 , обводим 6 вкруг, т.к. он по прежнему
pivot. Указатель
L на цифре 3, указатель
R на цифре 6. Мы помним, что двигаем указатели до тех пор, пока
L не зайдём за
R.
L двигаем на следующую цифру. Тут хочется разобрать два варианта: если бы предпоследняя цифра была 7 и если бы она была не 7, а 1.
Предпоследня цифра 1: Сдвинули указатель
L на цифру 1, т.к. мы можем двигать
L до тех пор, пока указатель
L указывает на цифру, меньшую чем
pivot. А вот
R мы не можем сдвинуть с 6, т.к. R не мы можем двигать только если указатель
R указывает на цифру, которая больше чем
pivot.
swap не делаем, т.к. 1 меньше 6. Записываем положение: 4 2 3 1 6, обводим
pivot 6.
L сдвигается на
pivot и больше не двигается.
R тоже не двигается. Обмен не производим. Сдвигаем
L и
R на одну позицию и подписываем цифру 1 маркером
R, а
L получается вне числа. Т.к.
L вне числа — ничего не делаем, а вот часть 4 2 3 1 выписываем снова, т.к. это наша левая часть, меньшая, чем
pivot 6. Выделяем новый
pivot и начинаем всё снова )
Предпоследняя цифра 7: Сдвинули указать
L на цифру 7, правый указатель не можем двигать, т.к. он уже указывает на pivot. т.к. 7 больше, чем
pivot, то делаем
swap. Запишем результат: 4 2 3 6 7, обводим 6 кружком, т.к. он
pivot. Указатель
L теперь сдвигается на цифру 7, а указатель
R сдвигается на цифру 3. Часть от
L до конца нет смысла сортировать, т.к. там всего 1 элемент, а вот часть от 4 до указателя
R отправляем на сортировку. Выбираем
pivot и начинаем всё снова ) Может на первый взгляд показаться, что если расставить много одинаковых с
pivot значений, это сломает алгоритм, но это не так. Можно напридумывать каверзных вариантов и на бумажке убедиться, что всё правильно и подивиться, How такие простые действия предоставляют такой надёжный механизм. Единственный минус — такая sorting не является стабильной. Т.к. при выполнении обмена одинаковые элементы могут поменять свой порядок, если один из них встретился до
pivot до того, How другой элемент попал в часть до
pivot при помощи обмена. Материал:
Выше мы рассмотрели "джентельменский" набор алгоритмов сортировки, реализованных на Java. Алгоритмы вообще штука полезная, How с прикладной точки зрения, так и с точки зрения развития мышления. Некоторые из них попроще, некоторые посложнее. По Howим-то умные люди защищали различные работы на степени, а по другим писали толстые-толстые книги. Надеюсь, приложенный к статье материал позволит вам узнать ещё больше, так How это обзорная статья, которая и так получилась увесистой. И цель её — дать небольшое вступление. Про введение в алгоритмы можно так же прочитать ознакомиться с книгой "
Грокаем Алгоримы". Также мне нравится плэйлист от Jack Brown —
AQA Decision 1 1.01 Tracing an Algorithm. Ради интереса можно посмотреть на визуализацию алгоритмов на
sorting.at и
visualgo.net. Ну и весь Youtube к вашим услугам.









GO TO FULL VERSION