O mundo do desenvolvimento moderno está repleto de diversas especificações projetadas para facilitar a vida. Conhecendo as ferramentas, você pode escolher a certa. Sem saber, você pode tornar sua vida mais difícil. Esta revisão levantará o véu de sigilo sobre o conceito de JPA - Java Persistence API. Espero que depois de ler você queira mergulhar ainda mais fundo neste mundo misterioso.
Introdução
Como sabemos, uma das principais tarefas dos programas é armazenar e processar dados. Antigamente, as pessoas simplesmente armazenavam dados em arquivos. Mas assim que é necessário acesso simultâneo de leitura e edição, quando há uma carga (ou seja, várias solicitações chegam ao mesmo tempo), armazenar dados simplesmente em arquivos torna-se um problema. Para mais informações sobre quais problemas os bancos de dados resolvem e como, aconselho a leitura do artigo “
Como os bancos de dados são estruturados ”. Isso significa que decidimos armazenar nossos dados em um banco de dados. Há muito tempo, Java é capaz de trabalhar com bancos de dados usando a API JDBC (The Java Database Connectivity). Você pode ler mais sobre JDBC aqui: “
JDBC ou onde tudo começa ”. Mas o tempo passou e os desenvolvedores sempre enfrentaram a necessidade de escrever o mesmo tipo e código de “manutenção” desnecessário (o chamado código Boilerplate) para operações triviais de salvar objetos Java no banco de dados e vice-versa, criando objetos Java usando dados do base de dados. E então, para resolver esses problemas, nasceu um conceito como ORM.
ORM - Mapeamento Objeto-Relacional ou traduzido para o mapeamento objeto-relacional russo. É uma tecnologia de programação que vincula bancos de dados aos conceitos de linguagens de programação orientadas a objetos. Para simplificar, ORM é a conexão entre objetos Java e registros em um banco de dados:
![JPA: Introdução à Tecnologia - 2]()
ORM é essencialmente o conceito de que um objeto Java pode ser representado como dados em um banco de dados (e vice-versa). Foi incorporado na forma da especificação JPA - Java Persistence API. A especificação já é uma descrição da API Java que expressa esse conceito. A especificação nos diz quais ferramentas devemos ter (ou seja, quais interfaces podemos trabalhar) para trabalhar de acordo com o conceito ORM. E como usar esses fundos. A especificação não descreve a implementação das ferramentas. Isto torna possível usar implementações diferentes para uma especificação. Você pode simplificar e dizer que uma especificação é uma descrição da API. O texto da especificação JPA pode ser encontrado no site da Oracle: "
JSR 338: JavaTM Persistence API ". Portanto, para utilizar JPA, precisamos de alguma implementação com a qual utilizaremos a tecnologia. As implementações JPA também são chamadas de Provedores JPA. Uma das implementações JPA mais notáveis é
o Hibernate . Portanto, proponho considerá-lo.
Criando um Projeto
Como JPA é sobre Java, precisaremos de um projeto Java. Poderíamos criar manualmente a estrutura de diretórios e adicionar nós mesmos as bibliotecas necessárias. Mas é muito mais conveniente e correto utilizar sistemas para automatizar a montagem de projetos (ou seja, em essência, este é apenas um programa que irá gerenciar a montagem de projetos para nós. Criar diretórios, adicionar as bibliotecas necessárias ao classpath, etc. .). Um desses sistemas é o Gradle. Você pode ler mais sobre o Gradle aqui: "
Uma breve introdução ao Gradle ". Como sabemos, a funcionalidade do Gradle (ou seja, as coisas que ele pode fazer) é implementada usando vários plug-ins do Gradle. Vamos usar o Gradle e o plugin "
Gradle Build Init Plugin ". Vamos executar o comando:
gradle init --type java-application
Gradle fará a estrutura de diretório necessária para nós e criará uma descrição declarativa básica do projeto no script de construção
build.gradle. Então, temos um aplicativo. Precisamos pensar sobre o que queremos descrever ou modelar com nossa aplicação. Vamos utilizar alguma ferramenta de modelagem, por exemplo:
app.quickdatabasediagrams.com ![JPA: Introdução à Tecnologia - 4]()
Aqui vale dizer que o que descrevemos é o nosso “modelo de domínio”. Um domínio é uma “área de assunto”. Em geral, domínio é “posse” em latim. Na Idade Média, este era o nome dado às áreas pertencentes a reis ou senhores feudais. E em francês tornou-se a palavra "domaine", que se traduz simplesmente como "área". Assim descrevemos nosso “modelo de domínio” = “modelo de assunto”. Cada elemento deste modelo é uma espécie de “essência”, algo da vida real. No nosso caso, são entidades: Categoria (
Category), Assunto (
Topic). Vamos criar um pacote separado para as entidades, por exemplo com o nome model. E vamos adicionar classes Java que descrevem entidades. No código Java, essas entidades são um
POJO regular , que pode ter a seguinte aparência:
public class Category {
private Long id;
private String title;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
Vamos copiar o conteúdo da aula e criar uma aula por analogia
Topic. Ele diferirá apenas no que sabe sobre a categoria à qual pertence. Portanto, vamos adicionar
Topicum campo de categoria e métodos para trabalhar com ele à classe:
private Category category;
public Category getCategory() {
return category;
}
public void setCategory(Category category) {
this.category = category;
}
Agora temos um aplicativo Java que possui seu próprio modelo de domínio. Agora é hora de começar a se conectar ao projeto JPA.
Adicionando JPA
Então, como lembramos, JPA significa que salvaremos algo no banco de dados. Portanto, precisamos de um banco de dados. Para usar uma conexão de banco de dados em nosso projeto, precisamos adicionar uma biblioteca de dependência para conectar-se ao banco de dados. Como lembramos, usamos o Gradle, que criou um script de construção para nós
build.gradle. Nele descreveremos as dependências que nosso projeto necessita. Dependências são aquelas bibliotecas sem as quais nosso código não pode funcionar. Vamos começar com uma descrição da dependência da conexão com o banco de dados. Fazemos isso da mesma forma que faríamos se estivéssemos trabalhando apenas com JDBC:
dependencies {
implementation 'com.h2database:h2:1.4.199'
Agora temos um banco de dados. Agora podemos adicionar uma camada à nossa aplicação que é responsável por mapear nossos objetos Java em conceitos de banco de dados (de Java para SQL). Como lembramos, usaremos uma implementação da especificação JPA chamada Hibernate para isso:
dependencies {
implementation 'com.h2database:h2:1.4.199'
implementation 'org.hibernate:hibernate-core:5.4.2.Final'
Agora precisamos configurar o JPA. Se lermos a especificação e a seção “8.1 Unidade de Persistência”, saberemos que uma Unidade de Persistência é algum tipo de combinação de configurações, metadados e entidades. E para que o JPA funcione, você precisa descrever pelo menos uma Unidade de Persistência no arquivo de configuração, que é chamada
persistence.xml. Sua localização está descrita no capítulo de especificações “8.2 Embalagem de Unidade de Persistência”. De acordo com esta seção, se tivermos um ambiente Java SE, devemos colocá-lo na raiz do diretório META-INF.
Vamos copiar o conteúdo do exemplo dado na especificação JPA no
8.2.1 persistence.xml filecapítulo " ":
<persistence>
<persistence-unit name="JavaRush">
<description>Persistence Unit For test</description>
<class>hibernate.model.Category</class>
<class>hibernate.model.Topic</class>
</persistence-unit>
</persistence>
Mas isto não é o suficiente. Precisamos dizer quem é nosso provedor JPA, ou seja, aquele que implementa a especificação JPA:
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
Agora vamos adicionar configurações (
properties). Algumas delas (começando com
javax.persistence) são configurações JPA padrão e são descritas na especificação JPA na seção "Propriedades 8.2.1.9". Algumas configurações são específicas do provedor (no nosso caso, elas afetam o Hibernate como um provedor Jpa. Nosso bloco de configurações ficará assim:
<properties>
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE" />
<property name="javax.persistence.jdbc.user" value="sa" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
Agora temos uma configuração compatível com JPA
persistence.xml, existe um provedor JPA Hibernate e existe um banco de dados H2, e também existem 2 classes que são nosso modelo de domínio. Vamos finalmente fazer tudo isso funcionar. No catálogo
/test/java, nosso Gradle gentilmente gerou um modelo para testes unitários e o chamou de AppTest. Vamos usá-lo. Conforme declarado no capítulo "7.1 Contextos de Persistência" da especificação JPA, as entidades no mundo JPA vivem em um espaço chamado Contexto de Persistência. Mas não trabalhamos diretamente com Contexto de Persistência. Para isso utilizamos
Entity Managerou “gerente de entidade”. É ele quem conhece o contexto e quais entidades ali vivem. Nós interagimos com
Entity Manager'om. Então só falta entender onde podemos conseguir isso
Entity Manager? De acordo com o capítulo "7.2.2 Obtendo um Gerenciador de Entidades Gerenciado por Aplicativo" da especificação JPA, devemos usar
EntityManagerFactory. Portanto, vamos nos munir da especificação JPA e pegar um exemplo do capítulo “7.3.2 Obtendo uma fábrica do Entity Manager em um ambiente Java SE” e formatá-lo na forma de um teste de unidade simples:
@Test
public void shouldStartHibernate() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
EntityManager entityManager = emf.createEntityManager();
}
Este teste já irá mostrar o erro "JPA persistence.xml versão XSD não reconhecida". O motivo é que
persistence.xmlvocê precisa especificar corretamente o esquema a ser usado, conforme indicado na especificação JPA na seção "Esquema 8.3 persistence.xml":
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
Além disso, a ordem dos elementos é importante. Portanto,
providerdeve ser especificado antes de listar as classes. Depois disso, o teste será executado com sucesso. Concluímos a conexão JPA direta. Antes de prosseguirmos, vamos pensar nos testes restantes. Cada um dos nossos testes exigirá
EntityManager. Vamos garantir que cada teste tenha o seu
EntityManagerno início da execução. Além disso, queremos que o banco de dados seja sempre novo. Pelo fato de utilizarmos
inmemorya opção, basta fechar
EntityManagerFactory. A criação
Factoryé uma operação cara. Mas para testes é justificado. JUnit permite especificar métodos que serão executados antes (Antes) e depois (Depois) da execução de cada teste:
public class AppTest {
private EntityManager em;
@Before
public void init() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
em = emf.createEntityManager();
}
@After
public void close() {
em.getEntityManagerFactory().close();
em.close();
}
Agora, antes de executar qualquer teste, será criado um novo
EntityManagerFactory, o que implicará na criação de um novo banco de dados, pois
hibernate.hbm2ddl.autotem o significado
create. E da nova fábrica teremos uma nova
EntityManager.
Entidades
Como lembramos, criamos anteriormente classes que descrevem nosso modelo de domínio. Já dissemos que estas são as nossas “essências”. Esta é a entidade que iremos gerenciar usando
EntityManager. Vamos escrever um teste simples para salvar a essência de uma categoria:
@Test
public void shouldPersistCategory() {
Category cat = new Category();
cat.setTitle("new category");
em.persist(cat);
}
Mas este teste não funcionará imediatamente, porque... receberemos vários erros que nos ajudarão a entender o que são entidades:
-
Unknown entity: hibernate.model.Category
Por que o Hibernate não entende o que Categoryé isso entity? O problema é que as entidades devem ser descritas de acordo com o padrão JPA.
As classes de entidade devem ser anotadas com a anotação @Entity, conforme indicado no capítulo "2.1 A classe de entidade" da especificação JPA.
-
No identifier specified for entity: hibernate.model.Category
As entidades devem ter um identificador único que possa ser usado para distinguir um registro de outro.
De acordo com o capítulo "2.4 Chaves Primárias e Identidade da Entidade" da especificação JPA, "Toda entidade deve ter uma chave primária", ou seja, Cada entidade deve ter uma “chave primária”. Essa chave primária deve ser especificada pela anotação@Id
-
ids for this class must be manually assigned before calling save()
A identificação tem que vir de algum lugar. Pode ser especificado manualmente ou obtido automaticamente.
Portanto, conforme indicado nos capítulos "11.2.3.3 GeneratedValue" e "11.1.20 GeneratedValue Annotation", podemos especificar a anotação @GeneratedValue.
Então para que a classe categoria se torne uma entidade devemos fazer as seguintes alterações:
@Entity
public class Category {
@Id
@GeneratedValue
private Long id;
Além disso, a anotação
@Idindica qual usar
Access Type. Você pode ler mais sobre o tipo de acesso na especificação JPA, na seção “2.3 Tipo de Acesso”. Resumindo, porque... especificamos
@Idacima do campo (
field), então o tipo de acesso será padrão
field-based, não
property-based. Portanto, o provedor JPA irá ler e armazenar valores diretamente dos campos. Se colocássemos
@Idacima do getter, então
property-basedo acesso seria usado, ou seja, via getter e setter. Ao executar o teste, também vemos quais solicitações são enviadas ao banco de dados (graças à opção
hibernate.show_sql). Mas ao salvar, não vemos nenhum
insert. Acontece que na verdade não salvamos nada? JPA permite sincronizar o contexto de persistência e o banco de dados usando o método
flush:
entityManager.flush();
Mas se executarmos agora, receberemos um erro:
nenhuma transação está em andamento . E agora é hora de aprender como o JPA usa transações.
Transações JPA
Como lembramos, o JPA é baseado no conceito de contexto de persistência. Este é o lugar onde as entidades vivem. E gerenciamos entidades através do
EntityManager. Quando executamos o comando
persist, colocamos a entidade no contexto. Mais precisamente, dizemos
EntityManagerque isso precisa ser feito. Mas este contexto é apenas uma área de armazenamento. Às vezes é até chamado de "cache de primeiro nível". Mas precisa estar conectado ao banco de dados. O comando
flush, que anteriormente falhou com erro, sincroniza dados do contexto de persistência com o banco de dados. Mas isto requer transporte e este transporte é uma transação. As transações em JPA são descritas na seção "7.5 Controle de transações" da especificação. Existe uma API especial para usar transações em JPA:
entityManager.getTransaction().begin();
entityManager.getTransaction().commit();
Precisamos adicionar gerenciamento de transações ao nosso código, que é executado antes e depois dos testes:
@Before
public void init() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
em = emf.createEntityManager();
em.getTransaction().begin();
}
@After
public void close() {
if (em.getTransaction().isActive()) {
em.getTransaction().commit();
}
em.getEntityManagerFactory().close();
em.close();
}
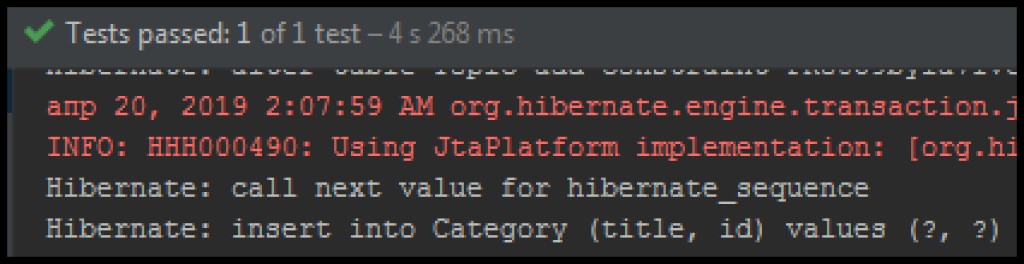
Após adicionar, veremos no log de inserção uma expressão em SQL que não existia antes:
As alterações acumuladas na
EntityManagertransação foram confirmadas (confirmadas e salvas) no banco de dados. Vamos agora tentar encontrar nossa essência. Vamos criar um teste para procurar uma entidade pelo seu ID:
@Test
public void shouldFindCategory() {
Category cat = new Category();
cat.setTitle("test");
em.persist(cat);
Category result = em.find(Category.class, 1L);
assertNotNull(result);
}
Neste caso, receberemos a entidade que salvamos anteriormente, mas não veremos as consultas SELECT no log. E tudo se baseia no que dizemos: “Gerente de entidade, encontre-me a entidade de categoria com ID = 1”. E o gerenciador de entidades primeiro procura no seu contexto (usa uma espécie de cache), e só se não encontrar, vai procurar no banco de dados. Vale a pena mudar o ID para 2 (não existe, salvamos apenas 1 instância), e veremos que
SELECTa solicitação aparece. Como nenhuma entidade foi encontrada no contexto e
EntityManagero banco de dados está tentando encontrar uma entidade, existem diferentes comandos que podemos usar para controlar o estado de uma entidade no contexto. A transição de uma entidade de um estado para outro é chamada de ciclo de vida da entidade -
lifecycle.
Ciclo de Vida da Entidade
O ciclo de vida das entidades está descrito na especificação JPA no capítulo “3.2 Ciclo de Vida da Instância da Entidade”. Porque entidades vivem em um contexto e são controladas por
EntityManager, então dizem que as entidades são controladas, ou seja, gerenciou. Vejamos as fases da vida de uma entidade:
Category cat = new Category();
cat.setTitle("new category");
entityManager.persist(cat);
entityManager.getTransaction().begin();
entityManager.getTransaction().commit();
entityManager.detach(cat);
Category managed = entityManager.merge(cat);
entityManager.remove(managed);
E aqui está um diagrama para consolidá-lo:
Mapeamento
No JPA podemos descrever os relacionamentos das entidades entre si. Vamos lembrar que já examinamos os relacionamentos das entidades entre si quando tratamos do nosso modelo de domínio. Em seguida, usamos o recurso
quickdatabasediagrams.com :
O estabelecimento de conexões entre entidades é chamado de mapeamento ou associação (Mapeamentos de Associação). Os tipos de associações que podem ser estabelecidas utilizando JPA são apresentados a seguir:
Vejamos uma entidade
Topicque descreve um tópico. O que podemos dizer sobre a atitude
Topicem relação a
Category? Muitos
Topicpertencerão a uma categoria. Portanto, precisamos de uma associação
ManyToOne. Vamos expressar esse relacionamento no JPA:
@ManyToOne
@JoinColumn(name = "category_id")
private Category category;
Para lembrar quais anotações colocar, lembre-se que a última parte é responsável pelo campo acima do qual a anotação está indicada.
ToOne- instância específica.
ToMany- coleções. Agora nossa conexão é unilateral. Vamos fazer disso uma comunicação bidirecional. Vamos agregar
Categoryconhecimento sobre todos
Topicque estão incluídos nesta categoria. Deve terminar com
ToMany, porque temos uma lista
Topic. Ou seja, a atitude “Para muitos” tópicos. A questão permanece -
OneToManyou
ManyToMany:
Uma boa resposta sobre o mesmo tópico pode ser lida aqui: "
Explique a relação ORM oneToMany, manyToMany como se eu tivesse cinco anos ". Se uma categoria tiver ligação com
ToManytópicos, então cada um desses tópicos poderá ter apenas uma categoria, então será
One, caso contrário
Many. Portanto, a
Categorylista de todos os tópicos ficará assim:
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "topic_id")
private Set<Topic> topics = new HashSet<>();
E não vamos esquecer de
Categoryescrever essencialmente um getter para obter uma lista de todos os tópicos:
public Set<Topic> getTopics() {
return this.topics;
}
Relacionamentos bidirecionais são algo muito difícil de rastrear automaticamente. Portanto, a JPA transfere essa responsabilidade para o desenvolvedor. O que isso significa para nós é que, quando estabelecemos um
Topicrelacionamento de entidade com o
Category, devemos nós mesmos garantir a consistência dos dados. Isso é feito de forma simples:
public void setCategory(Category category) {
category.getTopics().add(this);
this.category = category;
}
Vamos escrever um teste simples para verificar:
@Test
public void shouldPersistCategoryAndTopics() {
Category cat = new Category();
cat.setTitle("test");
Topic topic = new Topic();
topic.setTitle("topic");
topic.setCategory(cat);
em.persist(cat);
}
Mapeamento é um tópico totalmente separado. Como parte desta revisão, vale a pena entender por que meios isso é alcançado. Você pode ler mais sobre mapeamento aqui:
JPQL
JPA apresenta uma ferramenta interessante - consultas na Java Persistence Query Language. Esta linguagem é semelhante ao SQL, mas usa o modelo de objeto Java em vez de tabelas SQL. Vejamos um exemplo:
@Test
public void shouldPerformQuery() {
Category cat = new Category();
cat.setTitle("query");
em.persist(cat);
Query query = em.createQuery("SELECT c from Category c WHERE c.title = 'query'");
assertNotNull(query.getSingleResult());
}
Como podemos ver, na consulta utilizamos uma referência a uma entidade
Categorye não a uma tabela. E também no terreno desta entidade
title. JPQL oferece muitos recursos úteis e merece seu próprio artigo. Mais detalhes podem ser encontrados na revisão:
API de critérios
E, finalmente, gostaria de abordar a API de critérios. JPA apresenta uma ferramenta de construção de consulta dinâmica. Exemplo de uso da API de critérios:
@Test
public void shouldFindWithCriteriaAPI() {
Category cat = new Category();
em.persist(cat);
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Category> query = cb.createQuery(Category.class);
Root<Category> c = query.from(Category.class);
query.select(c);
List<Category> resultList = em.createQuery(query).getResultList();
assertEquals(1, resultList.size());
}
Este exemplo equivale à execução da solicitação "
SELECT c FROM Category c".
A API de critérios é uma ferramenta poderosa. Você pode ler mais sobre isso aqui:
Conclusão
Como podemos ver, o JPA oferece um grande número de recursos e ferramentas. Cada um deles requer experiência e conhecimento. Mesmo no âmbito da revisão da APP não foi possível falar tudo, muito menos um mergulho detalhado. Mas espero que depois de lê-lo tenha ficado mais claro o que são ORM e JPA, como funcionam e o que pode ser feito com eles. Pois bem, para um lanche ofereço vários materiais:
#Viacheslav
 ORM é essencialmente o conceito de que um objeto Java pode ser representado como dados em um banco de dados (e vice-versa). Foi incorporado na forma da especificação JPA - Java Persistence API. A especificação já é uma descrição da API Java que expressa esse conceito. A especificação nos diz quais ferramentas devemos ter (ou seja, quais interfaces podemos trabalhar) para trabalhar de acordo com o conceito ORM. E como usar esses fundos. A especificação não descreve a implementação das ferramentas. Isto torna possível usar implementações diferentes para uma especificação. Você pode simplificar e dizer que uma especificação é uma descrição da API. O texto da especificação JPA pode ser encontrado no site da Oracle: " JSR 338: JavaTM Persistence API ". Portanto, para utilizar JPA, precisamos de alguma implementação com a qual utilizaremos a tecnologia. As implementações JPA também são chamadas de Provedores JPA. Uma das implementações JPA mais notáveis é o Hibernate . Portanto, proponho considerá-lo.
ORM é essencialmente o conceito de que um objeto Java pode ser representado como dados em um banco de dados (e vice-versa). Foi incorporado na forma da especificação JPA - Java Persistence API. A especificação já é uma descrição da API Java que expressa esse conceito. A especificação nos diz quais ferramentas devemos ter (ou seja, quais interfaces podemos trabalhar) para trabalhar de acordo com o conceito ORM. E como usar esses fundos. A especificação não descreve a implementação das ferramentas. Isto torna possível usar implementações diferentes para uma especificação. Você pode simplificar e dizer que uma especificação é uma descrição da API. O texto da especificação JPA pode ser encontrado no site da Oracle: " JSR 338: JavaTM Persistence API ". Portanto, para utilizar JPA, precisamos de alguma implementação com a qual utilizaremos a tecnologia. As implementações JPA também são chamadas de Provedores JPA. Uma das implementações JPA mais notáveis é o Hibernate . Portanto, proponho considerá-lo.

 Aqui vale dizer que o que descrevemos é o nosso “modelo de domínio”. Um domínio é uma “área de assunto”. Em geral, domínio é “posse” em latim. Na Idade Média, este era o nome dado às áreas pertencentes a reis ou senhores feudais. E em francês tornou-se a palavra "domaine", que se traduz simplesmente como "área". Assim descrevemos nosso “modelo de domínio” = “modelo de assunto”. Cada elemento deste modelo é uma espécie de “essência”, algo da vida real. No nosso caso, são entidades: Categoria (
Aqui vale dizer que o que descrevemos é o nosso “modelo de domínio”. Um domínio é uma “área de assunto”. Em geral, domínio é “posse” em latim. Na Idade Média, este era o nome dado às áreas pertencentes a reis ou senhores feudais. E em francês tornou-se a palavra "domaine", que se traduz simplesmente como "área". Assim descrevemos nosso “modelo de domínio” = “modelo de assunto”. Cada elemento deste modelo é uma espécie de “essência”, algo da vida real. No nosso caso, são entidades: Categoria ( 












GO TO FULL VERSION