哈佛程式設計基礎課程講座 CS50 CS50 作業,第 3 週,第 1 部分 CS50 作業,第 3 週,第 2 部分
![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 1]() 但在某些時候,二次函數將取代線性函數,這是沒有辦法解決的。另一個漸近複雜度是對數時間或 O(log n)。隨著 n 的增加,這個函數增加得非常緩慢。O(log n) 是經典二分搜尋演算法在排序數組中的運行時間(還記得講座中撕破的電話簿嗎?)。將陣列一分為二,然後選擇元素所在的一半,這樣,每次將搜尋區域縮小一半,我們就會搜尋該元素。
但在某些時候,二次函數將取代線性函數,這是沒有辦法解決的。另一個漸近複雜度是對數時間或 O(log n)。隨著 n 的增加,這個函數增加得非常緩慢。O(log n) 是經典二分搜尋演算法在排序數組中的運行時間(還記得講座中撕破的電話簿嗎?)。將陣列一分為二,然後選擇元素所在的一半,這樣,每次將搜尋區域縮小一半,我們就會搜尋該元素。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 2]() 如果我們立即偶然發現我們正在尋找的東西,第一次將我們的資料數組分成兩半,會發生什麼?有一個術語表示最佳時間 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情況下(無論數組大小如何,都在恆定時間內查找)。如果要搜尋的元素是第一個元素,則線性搜尋的運作時間為 O(n) 和 Ω(1)。另一個符號是 theta (θ(n))。當最好和最差的選項相同時使用它。這適用於我們將字串長度儲存在單獨變數中的範例,因此對於任何長度,引用該變數就足夠了。對於該演算法,最好和最差情況分別為 Ω(1) 和 O(1)。這意味著演算法在時間 θ(1) 內運行。
如果我們立即偶然發現我們正在尋找的東西,第一次將我們的資料數組分成兩半,會發生什麼?有一個術語表示最佳時間 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情況下(無論數組大小如何,都在恆定時間內查找)。如果要搜尋的元素是第一個元素,則線性搜尋的運作時間為 O(n) 和 Ω(1)。另一個符號是 theta (θ(n))。當最好和最差的選項相同時使用它。這適用於我們將字串長度儲存在單獨變數中的範例,因此對於任何長度,引用該變數就足夠了。對於該演算法,最好和最差情況分別為 Ω(1) 和 O(1)。這意味著演算法在時間 θ(1) 內運行。
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 3]() LinearSearch 函數接收兩個參數作為輸入 - 鍵 key 和陣列 array[]。鍵是所需的值,在前面的範例中 key = 0。陣列是我們要尋找的數字列表。會看透。如果我們沒有找到任何東西,函數將傳回-1(數組中不存在的位置)。如果線性搜尋找到所需的元素,則函數將傳回所需元素在陣列中的位置。線性搜尋的好處是它適用於任何數組,無論元素的順序如何:我們仍然會遍歷整個數組。這也是他的弱點。如果需要在依序排序的 200 個數字的陣列中尋找數字 198,則 for 迴圈將執行 198 步驟。
LinearSearch 函數接收兩個參數作為輸入 - 鍵 key 和陣列 array[]。鍵是所需的值,在前面的範例中 key = 0。陣列是我們要尋找的數字列表。會看透。如果我們沒有找到任何東西,函數將傳回-1(數組中不存在的位置)。如果線性搜尋找到所需的元素,則函數將傳回所需元素在陣列中的位置。線性搜尋的好處是它適用於任何數組,無論元素的順序如何:我們仍然會遍歷整個數組。這也是他的弱點。如果需要在依序排序的 200 個數字的陣列中尋找數字 198,則 for 迴圈將執行 198 步驟。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 4]() 您可能已經猜到哪種方法更適合排序數組?
您可能已經猜到哪種方法更適合排序數組?
![Java-университет]()
![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 5]() 線性地需要很長時間。如果我們使用“將目錄撕成兩半的方法”,我們可以直接找到 Jasmine,並且可以安全地丟棄清單的前半部分,並意識到 Mickey 不可能在那裡。
線性地需要很長時間。如果我們使用“將目錄撕成兩半的方法”,我們可以直接找到 Jasmine,並且可以安全地丟棄清單的前半部分,並意識到 Mickey 不可能在那裡。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 6]() 使用相同的原理,我們丟棄第二列。繼續這個策略,我們只需幾個步驟就可以找到米奇。
使用相同的原理,我們丟棄第二列。繼續這個策略,我們只需幾個步驟就可以找到米奇。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 7]() 讓我們找出數字 144。我們將清單分成兩半,得到數字 13。我們評估我們要找的數字是大於還是小於 13。13
讓我們找出數字 144。我們將清單分成兩半,得到數字 13。我們評估我們要找的數字是大於還是小於 13。13 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 8]() < 144,因此我們可以忽略 左邊的所有內容13 和這個數字本身。現在我們的搜尋清單看起來像這樣:
< 144,因此我們可以忽略 左邊的所有內容13 和這個數字本身。現在我們的搜尋清單看起來像這樣: ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 9]() 有偶數個元素,所以我們選擇選擇「中間」(靠近開頭或結尾)的原則。假設我們選擇了接近開始的策略。在這種情況下,我們的「中間」= 55。55
有偶數個元素,所以我們選擇選擇「中間」(靠近開頭或結尾)的原則。假設我們選擇了接近開始的策略。在這種情況下,我們的「中間」= 55。55 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 10]() < 144。我們再次丟棄清單的左半部。對我們來說幸運的是,下一個平均數字是 144。
< 144。我們再次丟棄清單的左半部。對我們來說幸運的是,下一個平均數字是 144。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 11]() 我們僅用三步驟就使用二分搜尋在 13 元素數組中找到了 144。線性搜尋最多需要 12 個步驟即可處理相同的情況。由於演算法每一步都會將陣列中的元素數量減少一半,因此它將在漸近時間 O(log n) 內找到所需的元素,其中 n 是清單中的元素數量。也就是說,在我們的例子中,漸近時間 = O(log 13)(略多於三)。二分查找函數的偽代碼:
我們僅用三步驟就使用二分搜尋在 13 元素數組中找到了 144。線性搜尋最多需要 12 個步驟即可處理相同的情況。由於演算法每一步都會將陣列中的元素數量減少一半,因此它將在漸近時間 O(log n) 內找到所需的元素,其中 n 是清單中的元素數量。也就是說,在我們的例子中,漸近時間 = O(log 13)(略多於三)。二分查找函數的偽代碼: ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 12]() 函數接受 4 個參數作為輸入:所需的鍵、資料數組 array[],所需的鍵位於其中,min 和 max 是指向數組中最大和最小數的指針,其中我們正在研究演算法的這一步。對於我們的例子,最初給了下圖:
函數接受 4 個參數作為輸入:所需的鍵、資料數組 array[],所需的鍵位於其中,min 和 max 是指向數組中最大和最小數的指針,其中我們正在研究演算法的這一步。對於我們的例子,最初給了下圖: ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 13]() 讓我們進一步分析程式碼。中點是我們陣列的中間。它取決於極值點並在極值點之間居中。找到中間值後,我們檢查它是否小於我們的關鍵數字。
讓我們進一步分析程式碼。中點是我們陣列的中間。它取決於極值點並在極值點之間居中。找到中間值後,我們檢查它是否小於我們的關鍵數字。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 14]() 如果是這樣,那麼 key 也大於中間左邊的任何數字,我們可以再次調用二元函數,只是現在我們的 min = midpoint + 1。如果結果是 key < midpoint,我們可以丟棄那個數字本身和所有的數字,就在他的右邊。我們對數組進行二分搜索,從數字 min 到值 (中點 – 1)。
如果是這樣,那麼 key 也大於中間左邊的任何數字,我們可以再次調用二元函數,只是現在我們的 min = midpoint + 1。如果結果是 key < midpoint,我們可以丟棄那個數字本身和所有的數字,就在他的右邊。我們對數組進行二分搜索,從數字 min 到值 (中點 – 1)。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 15]() 最後,第三個分支:如果中點的值既不大於也不小於key,則只能是所需的數字。在這種情況下,我們返回它並完成程序。
最後,第三個分支:如果中點的值既不大於也不小於key,則只能是所需的數字。在這種情況下,我們返回它並完成程序。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 16]() 最後,可能會出現你要找的數字根本不在陣列中的情況。考慮到這種情況,我們執行以下檢查:
最後,可能會出現你要找的數字根本不在陣列中的情況。考慮到這種情況,我們執行以下檢查: ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 17]() 我們回 (-1) 表示我們沒有找到任何東西。您已經知道二分查找需要對陣列進行排序。因此,如果我們有一個未排序的數組,我們需要在其中找到某個元素,我們有兩個選擇:
我們回 (-1) 表示我們沒有找到任何東西。您已經知道二分查找需要對陣列進行排序。因此,如果我們有一個未排序的數組,我們需要在其中找到某個元素,我們有兩個選擇:
![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 18]() 注意:「程式設計師」樹的根與真正的根不同,它位於頂部。每個單元稱為頂點,頂點之間透過邊連接。樹的根是單元號 13。頂點 3 的左子樹在下圖中以顏色突出顯示:
注意:「程式設計師」樹的根與真正的根不同,它位於頂部。每個單元稱為頂點,頂點之間透過邊連接。樹的根是單元號 13。頂點 3 的左子樹在下圖中以顏色突出顯示: ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 19]() 我們的樹滿足二元樹的所有要求。這意味著它的每個左子樹只包含小於或等於頂點值的值,而右子樹只包含大於或等於頂點值的值。左子樹和右子樹本身都是二叉樹。構造二元樹的方法並不是唯一的方法:在下圖中,您可以看到同一組數字的另一種選擇,並且在實踐中可能有很多。
我們的樹滿足二元樹的所有要求。這意味著它的每個左子樹只包含小於或等於頂點值的值,而右子樹只包含大於或等於頂點值的值。左子樹和右子樹本身都是二叉樹。構造二元樹的方法並不是唯一的方法:在下圖中,您可以看到同一組數字的另一種選擇,並且在實踐中可能有很多。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 20]() 這個結構有助於進行搜尋:我們每次從上到左、下移動來找到最小值。
這個結構有助於進行搜尋:我們每次從上到左、下移動來找到最小值。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 21]() 如果你需要找到最大的數字,我們從上到下,再到右邊。找到一個不是最小值或最大值的數字也很簡單。我們從根部向左或向右下降,這取決於我們的頂點是比我們要尋找的頂點更大還是更小。因此,如果我們需要找到數字 89,我們會經過以下路徑:
如果你需要找到最大的數字,我們從上到下,再到右邊。找到一個不是最小值或最大值的數字也很簡單。我們從根部向左或向右下降,這取決於我們的頂點是比我們要尋找的頂點更大還是更小。因此,如果我們需要找到數字 89,我們會經過以下路徑: ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 22]() 您也可以按排序順序顯示數字。例如,如果我們需要按升序顯示所有數字,我們就會取出左子樹,並從最左邊的頂點開始往上。在樹上添加一些東西也很容易。最重要的是要記住結構。假設我們需要將值 7 加到樹中。讓我們轉到根並檢查。數字 7 < 13,所以我們向左走。我們在那裡看到 5,然後向右移動,因為 7 > 5。此外,由於 7 > 8 和 8 沒有後代,因此我們從 8 向左建造一個分支,並將 7 附加到它。您也可以從
您也可以按排序順序顯示數字。例如,如果我們需要按升序顯示所有數字,我們就會取出左子樹,並從最左邊的頂點開始往上。在樹上添加一些東西也很容易。最重要的是要記住結構。假設我們需要將值 7 加到樹中。讓我們轉到根並檢查。數字 7 < 13,所以我們向左走。我們在那裡看到 5,然後向右移動,因為 7 > 5。此外,由於 7 > 8 和 8 沒有後代,因此我們從 8 向左建造一個分支,並將 7 附加到它。您也可以從 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 23]()
![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 24]() 樹,但這有點複雜。我們需要考慮三種不同的刪除場景。
樹,但這有點複雜。我們需要考慮三種不同的刪除場景。
![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 26]() 所有數字都將簡單地添加到前一個數字的右側分支中。如果我們想找到一個數字,我們別無選擇,只能順著鏈條往下走。
所有數字都將簡單地添加到前一個數字的右側分支中。如果我們想找到一個數字,我們別無選擇,只能順著鏈條往下走。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 27]() 它並不比線性搜尋更好。還有其他更複雜的資料結構。但我們暫時不考慮它們。這麼說吧,要解決從排序清單建構樹的問題,可以隨機混合輸入資料。
它並不比線性搜尋更好。還有其他更複雜的資料結構。但我們暫時不考慮它們。這麼說吧,要解決從排序清單建構樹的問題,可以隨機混合輸入資料。
![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 28]() 主要想法是將我們的清單分為兩部分:已排序和未排序。在演算法的每個步驟中,都會將一個新數字從未排序部分移動到已排序部分,依此類推,直到所有數字都位於已排序部分中。
主要想法是將我們的清單分為兩部分:已排序和未排序。在演算法的每個步驟中,都會將一個新數字從未排序部分移動到已排序部分,依此類推,直到所有數字都位於已排序部分中。
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 29]() 我們在數組的未排序部分(即在這一步 - 在整個數組中)找到最小數。這個數字是2。現在我們用未排序的第一個來改變它,並將它放在排序數組的末尾(在這一步中放在第一位)。在此步驟中,這是數組中的第一個數字,即 3。
我們在數組的未排序部分(即在這一步 - 在整個數組中)找到最小數。這個數字是2。現在我們用未排序的第一個來改變它,並將它放在排序數組的末尾(在這一步中放在第一位)。在此步驟中,這是數組中的第一個數字,即 3。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 30]() 第二步。我們不看數字 2;它已經在已排序的子數組中了。我們開始尋找最小值,從第二個元素開始,這是5。我們確保3是未排序中的最小值,5是未排序中的第一個。我們交換它們並將 3 添加到已排序的子數組中。
第二步。我們不看數字 2;它已經在已排序的子數組中了。我們開始尋找最小值,從第二個元素開始,這是5。我們確保3是未排序中的最小值,5是未排序中的第一個。我們交換它們並將 3 添加到已排序的子數組中。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 31]() 在第三步驟中,我們看到未排序子數組中的最小數字是4。我們將其更改為未排序子數組中的第一個數字 - 5。在第四步中,我們發現在未
在第三步驟中,我們看到未排序子數組中的最小數字是4。我們將其更改為未排序子數組中的第一個數字 - 5。在第四步中,我們發現在未 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 32]() 排序數組中最小數字是5。我們將其從 6 更改並將其添加到已排序的子數組中。
排序數組中最小數字是5。我們將其從 6 更改並將其添加到已排序的子數組中。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 33]() 當未排序的數中只剩下一個數(最大的)時,這表示整個陣列已排序!
當未排序的數中只剩下一個數(最大的)時,這表示整個陣列已排序! ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 34]() 這就是數組實現在程式碼中的樣子。嘗試自己做一下。
這就是數組實現在程式碼中的樣子。嘗試自己做一下。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 35]() 在最好和最壞的情況下,為了找到最小的未排序元素,我們必須將每個元素與未排序數組的每個元素進行比較,並且我們將在每次迭代時執行此操作。但我們不需要查看整個列表,而只需查看未排序的部分。這會改變演算法的速度嗎?第一步,對於 5 個元素的數組,我們進行 4 次比較,第二次比較 3 次,第三次比較 2 次。要獲得比較次數,我們需要將所有這些數字相加。我們得到總和
在最好和最壞的情況下,為了找到最小的未排序元素,我們必須將每個元素與未排序數組的每個元素進行比較,並且我們將在每次迭代時執行此操作。但我們不需要查看整個列表,而只需查看未排序的部分。這會改變演算法的速度嗎?第一步,對於 5 個元素的數組,我們進行 4 次比較,第二次比較 3 次,第三次比較 2 次。要獲得比較次數,我們需要將所有這些數字相加。我們得到總和 ![公式]() 因此,演算法在最好和最壞情況下的預期速度是 θ(n 2 )。不是最有效的演算法!然而,出於教育目的和小數據集,它非常適用。
因此,演算法在最好和最壞情況下的預期速度是 θ(n 2 )。不是最有效的演算法!然而,出於教育目的和小數據集,它非常適用。
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 36]() 第一步:遍歷數組。演算法從前兩個元素 8 和 6 開始,並檢查它們的順序是否正確。8 > 6,所以我們交換它們。接下來我們來看第二個和第三個元素,現在是8和4。出於同樣的原因,我們交換它們。我們第三次比較 8 和 2。總共,我們進行了三次交換 (8, 6)、(8, 4)、(8, 2)。值 8 “浮動”到清單末端的正確位置。
第一步:遍歷數組。演算法從前兩個元素 8 和 6 開始,並檢查它們的順序是否正確。8 > 6,所以我們交換它們。接下來我們來看第二個和第三個元素,現在是8和4。出於同樣的原因,我們交換它們。我們第三次比較 8 和 2。總共,我們進行了三次交換 (8, 6)、(8, 4)、(8, 2)。值 8 “浮動”到清單末端的正確位置。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 37]() 步驟2:交換(6,4)和(6,2)。6 現在位於倒數第二個位置,無需將其與已排序的清單「尾部」進行比較。
步驟2:交換(6,4)和(6,2)。6 現在位於倒數第二個位置,無需將其與已排序的清單「尾部」進行比較。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 38]() 第三步:交換4和2。四個「漂浮」到正確的位置。
第三步:交換4和2。四個「漂浮」到正確的位置。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 39]() 第四步:我們遍歷數組,但沒有什麼可以改變的。這表示數組已完全排序。
第四步:我們遍歷數組,但沒有什麼可以改變的。這表示數組已完全排序。 ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 40]() 這是演算法程式碼。試著用 C 實現它! 冒泡排序在最壞的情況下(所有數字都是錯誤的)需要
這是演算法程式碼。試著用 C 實現它! 冒泡排序在最壞的情況下(所有數字都是錯誤的)需要![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 43]() O(n 2 ) 時間,因為我們每次迭代需要執行 n 步,其中也有 n 步。事實上,與選擇排序演算法的情況一樣,時間會稍微少一些(n 2 /2 – n/2),但這可以忽略不計。在最好的情況下(如果所有元素都已經就位),我們可以分 n 步驟完成,即 Ω(n),因為我們只需要遍歷數組一次並確保所有元素都就位(即甚至 n-1 個元素)。
O(n 2 ) 時間,因為我們每次迭代需要執行 n 步,其中也有 n 步。事實上,與選擇排序演算法的情況一樣,時間會稍微少一些(n 2 /2 – n/2),但這可以忽略不計。在最好的情況下(如果所有元素都已經就位),我們可以分 n 步驟完成,即 Ω(n),因為我們只需要遍歷數組一次並確保所有元素都就位(即甚至 n-1 個元素)。
![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 41]() 讓我們使用下面的範例來了解插入排序的工作原理。在開始之前,所有元素都被視為未排序。
讓我們使用下面的範例來了解插入排序的工作原理。在開始之前,所有元素都被視為未排序。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 42]() 步驟 1:取出第一個未排序的值 (3) 並將其插入已排序的子數組中。在這一步,整個排序子數組,它的開始和結束將是這三個。
步驟 1:取出第一個未排序的值 (3) 並將其插入已排序的子數組中。在這一步,整個排序子數組,它的開始和結束將是這三個。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 43]() 步驟 2:由於 3 > 5,我們將把 5 插入到 3 右側的已排序子數組。
步驟 2:由於 3 > 5,我們將把 5 插入到 3 右側的已排序子數組。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 44]() 步驟 3:現在我們將數字 2 插入到已排序數組中。我們從右到左比較2的值來找到正確的位置。由於 2 < 5 和 2 < 3,我們已經到達排序子陣列的開頭。因此,我們必須將 2 插入到 3 的左側。為此,請將 3 和 5 向右移動,以便有空間容納 2,並將其插入到陣列的開頭。
步驟 3:現在我們將數字 2 插入到已排序數組中。我們從右到左比較2的值來找到正確的位置。由於 2 < 5 和 2 < 3,我們已經到達排序子陣列的開頭。因此,我們必須將 2 插入到 3 的左側。為此,請將 3 和 5 向右移動,以便有空間容納 2,並將其插入到陣列的開頭。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 45]() 步驟 4.我們很幸運:6 > 5,所以我們可以在數字 5 之後插入該數字。步驟
步驟 4.我們很幸運:6 > 5,所以我們可以在數字 5 之後插入該數字。步驟 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 46]() 5. 4 < 6 且 4 < 5,但 4 > 3。因此,我們知道必須插入 4 3 的右側。同樣,我們被迫將5 和6 向右移動,為4 創建間隙。
5. 4 < 6 且 4 < 5,但 4 > 3。因此,我們知道必須插入 4 3 的右側。同樣,我們被迫將5 和6 向右移動,為4 創建間隙。 ![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 47]() 完成!廣義演算法:取出n的每個未排序元素,並從右到左將其與已排序子數組中的值進行比較,直到找到n的合適位置(即找到第一個小於n的數的那一刻) 。然後,我們將這個數字右側的所有已排序元素向右移動,為 n 騰出空間,並將其插入那裡,從而擴展數組的已排序部分。對於每個未排序的元素 n,您需要:
完成!廣義演算法:取出n的每個未排序元素,並從右到左將其與已排序子數組中的值進行比較,直到找到n的合適位置(即找到第一個小於n的數的那一刻) 。然後,我們將這個數字右側的所有已排序元素向右移動,為 n 騰出空間,並將其插入那裡,從而擴展數組的已排序部分。對於每個未排序的元素 n,您需要:
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 48]()
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 49]() 假設我們有 n 個元素要排序。如果n < 2,我們完成排序,否則我們將數組的左右部分分別排序,然後將它們組合起來。讓我們對數組進行排序,
假設我們有 n 個元素要排序。如果n < 2,我們完成排序,否則我們將數組的左右部分分別排序,然後將它們組合起來。讓我們對數組進行排序, ![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 50]() 將其分為兩部分,繼續劃分,直到得到大小為 1 的子數組,這些子數組顯然已排序。
將其分為兩部分,繼續劃分,直到得到大小為 1 的子數組,這些子數組顯然已排序。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 51]() 使用簡單的演算法可以在 O(n) 時間內合併兩個已排序的子數組:刪除每個子數組開頭的較小數字並將其插入到合併的數組中。重複直到所有元素都消失。
使用簡單的演算法可以在 O(n) 時間內合併兩個已排序的子數組:刪除每個子數組開頭的較小數字並將其插入到合併的數組中。重複直到所有元素都消失。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 52]()
![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 56]() 對於所有情況,合併排序都需要 O(nlog n) 時間。當我們在每個遞歸層級將數組分成兩半時,我們得到 log n。然後,合併子數組只需要 n 次比較。因此 O(nlog n)。歸併排序的最佳和最差情況是相同的,演算法的預期運行時間 = θ(nlog n)。該演算法是所考慮的演算法中最有效的。
對於所有情況,合併排序都需要 O(nlog n) 時間。當我們在每個遞歸層級將數組分成兩半時,我們得到 log n。然後,合併子數組只需要 n 次比較。因此 O(nlog n)。歸併排序的最佳和最差情況是相同的,演算法的預期運行時間 = θ(nlog n)。該演算法是所考慮的演算法中最有效的。 ![CS50 附加資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 53]()
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 58]()
漸近符號
要即時測量演算法的速度(以秒和分鐘為單位)並不容易。一個程式可能比另一個程式運作得慢,並不是因為它本身效率低下,而是因為作業系統緩慢、與硬體不相容、電腦記憶體被其他行程佔用…為了衡量演算法的有效性,發明了通用概念,無論程式運行的環境如何。問題的漸近複雜性是使用 Big O 表示法來衡量的。設f(x) 和g(x) 是在x0 的某個鄰域中定義的函數,並且g 在那裡不消失。如果存在常數C>,則對於(x -> x0),f 比g 大“ O” 0 ,對於來自點 x0 的某個鄰域的所有 x,不等式成立。|f(x)| <= C |g(x)| 稍微不那麼嚴格:如果存在常數 C>0,則 f 大於 g,這對於所有 x > x0 f(x) <= C*g(x) 不要害怕正式定義!本質上,它決定了當輸入資料量成長到無限大時程式運行時間的漸近增加。例如,您正在比較 1000 個元素和 10 個元素的陣列進行排序,您需要了解程式的運行時間將如何增加。或者,您需要透過逐個字元計算字串的長度,並為每個字元加 1: c - 1 a - 2 t - 3 其漸近速度 = O(n),其中 n 是單字中的字母數。如果按照這個原則來統計,統計整行所需的時間與字元數成正比。計算 20 個字元的字串中的字元數所需的時間是計算 10 個字元的字串中的字元數的兩倍。想像一下,在長度變數中,您儲存的值等於字串中的字元數。例如,length = 1000。要取得字串的長度,只需存取該變數即可,甚至不需要查看字串本身。而且無論我們如何改變長度,我們總是可以存取這個變數。在這種情況下,漸近速度 = O(1)。更改輸入資料不會改變此類任務的速度;搜尋在恆定時間內完成。在這種情況下,程式是漸近常數。缺點:您會浪費電腦記憶體來儲存額外的變數並花費額外的時間來更新其值。如果您認為線性時間很糟糕,我們可以向您保證它可能會更糟。例如,O(n 2 )。這種表示法意味著隨著 n 的增長,迭代元素(或其他操作)所需的時間將越來越急劇地增長。但對於較小的 n,漸近速度為 O(n 2 ) 的演算法可以比漸近速度為 O(n) 的演算法運行得更快。  但在某些時候,二次函數將取代線性函數,這是沒有辦法解決的。另一個漸近複雜度是對數時間或 O(log n)。隨著 n 的增加,這個函數增加得非常緩慢。O(log n) 是經典二分搜尋演算法在排序數組中的運行時間(還記得講座中撕破的電話簿嗎?)。將陣列一分為二,然後選擇元素所在的一半,這樣,每次將搜尋區域縮小一半,我們就會搜尋該元素。
但在某些時候,二次函數將取代線性函數,這是沒有辦法解決的。另一個漸近複雜度是對數時間或 O(log n)。隨著 n 的增加,這個函數增加得非常緩慢。O(log n) 是經典二分搜尋演算法在排序數組中的運行時間(還記得講座中撕破的電話簿嗎?)。將陣列一分為二,然後選擇元素所在的一半,這樣,每次將搜尋區域縮小一半,我們就會搜尋該元素。  如果我們立即偶然發現我們正在尋找的東西,第一次將我們的資料數組分成兩半,會發生什麼?有一個術語表示最佳時間 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情況下(無論數組大小如何,都在恆定時間內查找)。如果要搜尋的元素是第一個元素,則線性搜尋的運作時間為 O(n) 和 Ω(1)。另一個符號是 theta (θ(n))。當最好和最差的選項相同時使用它。這適用於我們將字串長度儲存在單獨變數中的範例,因此對於任何長度,引用該變數就足夠了。對於該演算法,最好和最差情況分別為 Ω(1) 和 O(1)。這意味著演算法在時間 θ(1) 內運行。
如果我們立即偶然發現我們正在尋找的東西,第一次將我們的資料數組分成兩半,會發生什麼?有一個術語表示最佳時間 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情況下(無論數組大小如何,都在恆定時間內查找)。如果要搜尋的元素是第一個元素,則線性搜尋的運作時間為 O(n) 和 Ω(1)。另一個符號是 theta (θ(n))。當最好和最差的選項相同時使用它。這適用於我們將字串長度儲存在單獨變數中的範例,因此對於任何長度,引用該變數就足夠了。對於該演算法,最好和最差情況分別為 Ω(1) 和 O(1)。這意味著演算法在時間 θ(1) 內運行。
線性搜尋
當您打開網絡瀏覽器,在社交網絡上查找頁面、資訊、朋友時,您就是在進行搜索,就像在商店中試圖找到一雙合適的鞋子一樣。您可能已經注意到,秩序對您的搜尋方式有很大影響。如果您的衣櫃裡有所有襯衫,那麼在其中找到您需要的一件通常比在房間各處沒有系統的那些分散的襯衫中更容易找到您需要的一件。線性搜尋是一種逐一順序搜尋的方法。當您從上到下查看 Google 搜尋結果時,您正在使用線性搜尋。 例子。假設我們有一個數字列表:2 4 0 5 3 7 8 1 我們需要找到 0。我們馬上就能看到它,但電腦程式不能那樣工作。她從清單的開頭開始,看到數字 2。然後她檢查,2=0?事實並非如此,所以她繼續並轉向第二個角色。那裡也有失敗等著她,只有在第三個位置,演算法才能找到所需的數字。線性搜尋的偽代碼:  LinearSearch 函數接收兩個參數作為輸入 - 鍵 key 和陣列 array[]。鍵是所需的值,在前面的範例中 key = 0。陣列是我們要尋找的數字列表。會看透。如果我們沒有找到任何東西,函數將傳回-1(數組中不存在的位置)。如果線性搜尋找到所需的元素,則函數將傳回所需元素在陣列中的位置。線性搜尋的好處是它適用於任何數組,無論元素的順序如何:我們仍然會遍歷整個數組。這也是他的弱點。如果需要在依序排序的 200 個數字的陣列中尋找數字 198,則 for 迴圈將執行 198 步驟。
LinearSearch 函數接收兩個參數作為輸入 - 鍵 key 和陣列 array[]。鍵是所需的值,在前面的範例中 key = 0。陣列是我們要尋找的數字列表。會看透。如果我們沒有找到任何東西,函數將傳回-1(數組中不存在的位置)。如果線性搜尋找到所需的元素,則函數將傳回所需元素在陣列中的位置。線性搜尋的好處是它適用於任何數組,無論元素的順序如何:我們仍然會遍歷整個數組。這也是他的弱點。如果需要在依序排序的 200 個數字的陣列中尋找數字 198,則 for 迴圈將執行 198 步驟。  您可能已經猜到哪種方法更適合排序數組?
您可能已經猜到哪種方法更適合排序數組?

二分查找和樹
想像一下,您有一個按字母順序排列的迪士尼角色列表,並且您需要找到米老鼠。 線性地需要很長時間。如果我們使用“將目錄撕成兩半的方法”,我們可以直接找到 Jasmine,並且可以安全地丟棄清單的前半部分,並意識到 Mickey 不可能在那裡。
線性地需要很長時間。如果我們使用“將目錄撕成兩半的方法”,我們可以直接找到 Jasmine,並且可以安全地丟棄清單的前半部分,並意識到 Mickey 不可能在那裡。  使用相同的原理,我們丟棄第二列。繼續這個策略,我們只需幾個步驟就可以找到米奇。
使用相同的原理,我們丟棄第二列。繼續這個策略,我們只需幾個步驟就可以找到米奇。  讓我們找出數字 144。我們將清單分成兩半,得到數字 13。我們評估我們要找的數字是大於還是小於 13。13
讓我們找出數字 144。我們將清單分成兩半,得到數字 13。我們評估我們要找的數字是大於還是小於 13。13  < 144,因此我們可以忽略 左邊的所有內容13 和這個數字本身。現在我們的搜尋清單看起來像這樣:
< 144,因此我們可以忽略 左邊的所有內容13 和這個數字本身。現在我們的搜尋清單看起來像這樣: 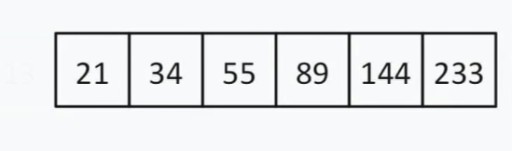 有偶數個元素,所以我們選擇選擇「中間」(靠近開頭或結尾)的原則。假設我們選擇了接近開始的策略。在這種情況下,我們的「中間」= 55。55
有偶數個元素,所以我們選擇選擇「中間」(靠近開頭或結尾)的原則。假設我們選擇了接近開始的策略。在這種情況下,我們的「中間」= 55。55  < 144。我們再次丟棄清單的左半部。對我們來說幸運的是,下一個平均數字是 144。
< 144。我們再次丟棄清單的左半部。對我們來說幸運的是,下一個平均數字是 144。  我們僅用三步驟就使用二分搜尋在 13 元素數組中找到了 144。線性搜尋最多需要 12 個步驟即可處理相同的情況。由於演算法每一步都會將陣列中的元素數量減少一半,因此它將在漸近時間 O(log n) 內找到所需的元素,其中 n 是清單中的元素數量。也就是說,在我們的例子中,漸近時間 = O(log 13)(略多於三)。二分查找函數的偽代碼:
我們僅用三步驟就使用二分搜尋在 13 元素數組中找到了 144。線性搜尋最多需要 12 個步驟即可處理相同的情況。由於演算法每一步都會將陣列中的元素數量減少一半,因此它將在漸近時間 O(log n) 內找到所需的元素,其中 n 是清單中的元素數量。也就是說,在我們的例子中,漸近時間 = O(log 13)(略多於三)。二分查找函數的偽代碼: 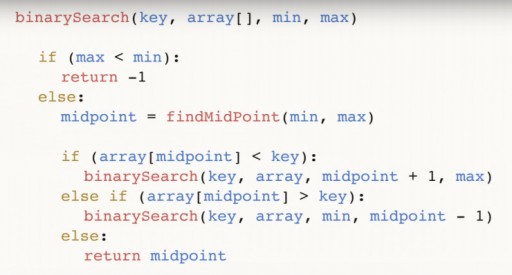 函數接受 4 個參數作為輸入:所需的鍵、資料數組 array[],所需的鍵位於其中,min 和 max 是指向數組中最大和最小數的指針,其中我們正在研究演算法的這一步。對於我們的例子,最初給了下圖:
函數接受 4 個參數作為輸入:所需的鍵、資料數組 array[],所需的鍵位於其中,min 和 max 是指向數組中最大和最小數的指針,其中我們正在研究演算法的這一步。對於我們的例子,最初給了下圖:  讓我們進一步分析程式碼。中點是我們陣列的中間。它取決於極值點並在極值點之間居中。找到中間值後,我們檢查它是否小於我們的關鍵數字。
讓我們進一步分析程式碼。中點是我們陣列的中間。它取決於極值點並在極值點之間居中。找到中間值後,我們檢查它是否小於我們的關鍵數字。  如果是這樣,那麼 key 也大於中間左邊的任何數字,我們可以再次調用二元函數,只是現在我們的 min = midpoint + 1。如果結果是 key < midpoint,我們可以丟棄那個數字本身和所有的數字,就在他的右邊。我們對數組進行二分搜索,從數字 min 到值 (中點 – 1)。
如果是這樣,那麼 key 也大於中間左邊的任何數字,我們可以再次調用二元函數,只是現在我們的 min = midpoint + 1。如果結果是 key < midpoint,我們可以丟棄那個數字本身和所有的數字,就在他的右邊。我們對數組進行二分搜索,從數字 min 到值 (中點 – 1)。  最後,第三個分支:如果中點的值既不大於也不小於key,則只能是所需的數字。在這種情況下,我們返回它並完成程序。
最後,第三個分支:如果中點的值既不大於也不小於key,則只能是所需的數字。在這種情況下,我們返回它並完成程序。  最後,可能會出現你要找的數字根本不在陣列中的情況。考慮到這種情況,我們執行以下檢查:
最後,可能會出現你要找的數字根本不在陣列中的情況。考慮到這種情況,我們執行以下檢查:  我們回 (-1) 表示我們沒有找到任何東西。您已經知道二分查找需要對陣列進行排序。因此,如果我們有一個未排序的數組,我們需要在其中找到某個元素,我們有兩個選擇:
我們回 (-1) 表示我們沒有找到任何東西。您已經知道二分查找需要對陣列進行排序。因此,如果我們有一個未排序的數組,我們需要在其中找到某個元素,我們有兩個選擇:
- 對清單進行排序並應用二分搜索
- 保持清單始終排序,同時新增和刪除元素。
- 它是一棵樹(模擬樹結構的資料結構 - 它具有根和其他節點(葉子),透過「分支」或沒有循環的邊連接)
- 每個節點有 0、1 或 2 個子節點
- 左子樹和右子樹都是二元搜尋樹。
- 任意節點X的左子樹的所有節點的資料鍵值都小於節點X本身的資料鍵值。
- 任意節點X的右子樹中的所有節點的資料鍵值都大於或等於節點X本身的資料鍵值。
 注意:「程式設計師」樹的根與真正的根不同,它位於頂部。每個單元稱為頂點,頂點之間透過邊連接。樹的根是單元號 13。頂點 3 的左子樹在下圖中以顏色突出顯示:
注意:「程式設計師」樹的根與真正的根不同,它位於頂部。每個單元稱為頂點,頂點之間透過邊連接。樹的根是單元號 13。頂點 3 的左子樹在下圖中以顏色突出顯示: 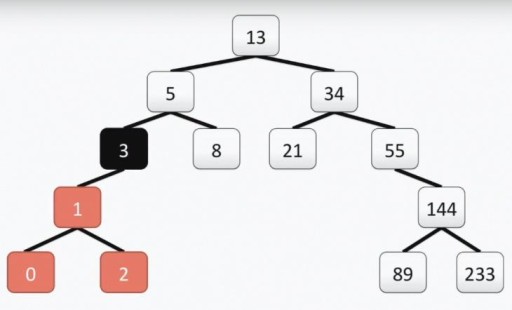 我們的樹滿足二元樹的所有要求。這意味著它的每個左子樹只包含小於或等於頂點值的值,而右子樹只包含大於或等於頂點值的值。左子樹和右子樹本身都是二叉樹。構造二元樹的方法並不是唯一的方法:在下圖中,您可以看到同一組數字的另一種選擇,並且在實踐中可能有很多。
我們的樹滿足二元樹的所有要求。這意味著它的每個左子樹只包含小於或等於頂點值的值,而右子樹只包含大於或等於頂點值的值。左子樹和右子樹本身都是二叉樹。構造二元樹的方法並不是唯一的方法:在下圖中,您可以看到同一組數字的另一種選擇,並且在實踐中可能有很多。  這個結構有助於進行搜尋:我們每次從上到左、下移動來找到最小值。
這個結構有助於進行搜尋:我們每次從上到左、下移動來找到最小值。 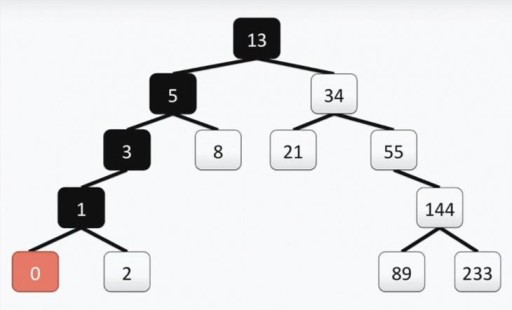 如果你需要找到最大的數字,我們從上到下,再到右邊。找到一個不是最小值或最大值的數字也很簡單。我們從根部向左或向右下降,這取決於我們的頂點是比我們要尋找的頂點更大還是更小。因此,如果我們需要找到數字 89,我們會經過以下路徑:
如果你需要找到最大的數字,我們從上到下,再到右邊。找到一個不是最小值或最大值的數字也很簡單。我們從根部向左或向右下降,這取決於我們的頂點是比我們要尋找的頂點更大還是更小。因此,如果我們需要找到數字 89,我們會經過以下路徑:  您也可以按排序順序顯示數字。例如,如果我們需要按升序顯示所有數字,我們就會取出左子樹,並從最左邊的頂點開始往上。在樹上添加一些東西也很容易。最重要的是要記住結構。假設我們需要將值 7 加到樹中。讓我們轉到根並檢查。數字 7 < 13,所以我們向左走。我們在那裡看到 5,然後向右移動,因為 7 > 5。此外,由於 7 > 8 和 8 沒有後代,因此我們從 8 向左建造一個分支,並將 7 附加到它。您也可以從
您也可以按排序順序顯示數字。例如,如果我們需要按升序顯示所有數字,我們就會取出左子樹,並從最左邊的頂點開始往上。在樹上添加一些東西也很容易。最重要的是要記住結構。假設我們需要將值 7 加到樹中。讓我們轉到根並檢查。數字 7 < 13,所以我們向左走。我們在那裡看到 5,然後向右移動,因為 7 > 5。此外,由於 7 > 8 和 8 沒有後代,因此我們從 8 向左建造一個分支,並將 7 附加到它。您也可以從 
 樹,但這有點複雜。我們需要考慮三種不同的刪除場景。
樹,但這有點複雜。我們需要考慮三種不同的刪除場景。
- 最簡單的選擇:我們需要刪除沒有子節點的頂點。例如,我們剛剛新增的數字 7。在這種情況下,我們只需沿著具有該數字的頂點的路徑並將其刪除即可。
- 一個頂點有一個子頂點。在這種情況下,您可以刪除所需的頂點,但其後代必須連接到“祖父”,即其直接祖先生長的頂點。例如,我們需要從同一棵樹中刪除數字 3。在這種情況下,我們將其後代 1 與整個子樹一起連接到 5。這很簡單,因為 5 左側的所有頂點都將小於這個數字(且小於遠程三倍)。
![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 24]()
- 最困難的情況是被刪除的頂點有兩個子節點。現在我們需要做的第一件事是找到隱藏下一個較大值的頂點,我們需要交換它們,然後刪除所需的頂點。請注意,下一個最高值頂點不能有兩個子節點,那麼它的左子節點將是下一個值的最佳候選。讓我們從樹中刪除根節點 13。首先,我們尋找最接近 13 且大於 13 的數字。這是 21。交換 21 和 13 並刪除 13。
![附加資料 CS50(第 3 週,第 7 課和第 8 課):漸近表示法、排序和搜尋演算法 - 25]()
![CS50 補充資料(第 3 週,第 7 課和第 8 課):漸近符號、排序和搜尋演算法 - 27]()



 所有數字都將簡單地添加到前一個數字的右側分支中。如果我們想找到一個數字,我們別無選擇,只能順著鏈條往下走。
所有數字都將簡單地添加到前一個數字的右側分支中。如果我們想找到一個數字,我們別無選擇,只能順著鏈條往下走。  它並不比線性搜尋更好。還有其他更複雜的資料結構。但我們暫時不考慮它們。這麼說吧,要解決從排序清單建構樹的問題,可以隨機混合輸入資料。
它並不比線性搜尋更好。還有其他更複雜的資料結構。但我們暫時不考慮它們。這麼說吧,要解決從排序清單建構樹的問題,可以隨機混合輸入資料。
排序演算法
有一個數字數組。我們需要對其進行排序。為了簡單起見,我們假設我們按升序(從最小到最大)對整數進行排序。有幾種已知的方法可以完成這個過程。另外,您始終可以構思主題並提出對演算法的修改。按選擇排序
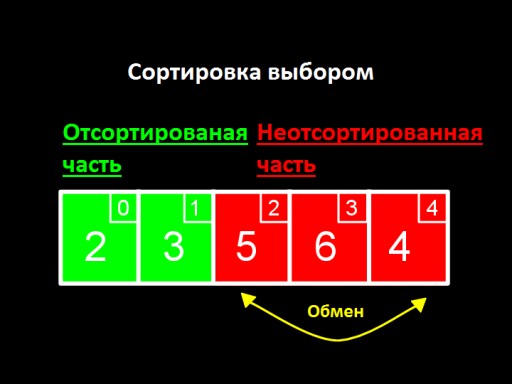 主要想法是將我們的清單分為兩部分:已排序和未排序。在演算法的每個步驟中,都會將一個新數字從未排序部分移動到已排序部分,依此類推,直到所有數字都位於已排序部分中。
主要想法是將我們的清單分為兩部分:已排序和未排序。在演算法的每個步驟中,都會將一個新數字從未排序部分移動到已排序部分,依此類推,直到所有數字都位於已排序部分中。
- 找出最小的未排序值。
- 我們將此值與第一個未排序的值交換,從而將其放置在已排序數組的末尾。
- 如果還有未排序的值,則傳回步驟1。
 我們在數組的未排序部分(即在這一步 - 在整個數組中)找到最小數。這個數字是2。現在我們用未排序的第一個來改變它,並將它放在排序數組的末尾(在這一步中放在第一位)。在此步驟中,這是數組中的第一個數字,即 3。
我們在數組的未排序部分(即在這一步 - 在整個數組中)找到最小數。這個數字是2。現在我們用未排序的第一個來改變它,並將它放在排序數組的末尾(在這一步中放在第一位)。在此步驟中,這是數組中的第一個數字,即 3。  第二步。我們不看數字 2;它已經在已排序的子數組中了。我們開始尋找最小值,從第二個元素開始,這是5。我們確保3是未排序中的最小值,5是未排序中的第一個。我們交換它們並將 3 添加到已排序的子數組中。
第二步。我們不看數字 2;它已經在已排序的子數組中了。我們開始尋找最小值,從第二個元素開始,這是5。我們確保3是未排序中的最小值,5是未排序中的第一個。我們交換它們並將 3 添加到已排序的子數組中。  在第三步驟中,我們看到未排序子數組中的最小數字是4。我們將其更改為未排序子數組中的第一個數字 - 5。在第四步中,我們發現在未
在第三步驟中,我們看到未排序子數組中的最小數字是4。我們將其更改為未排序子數組中的第一個數字 - 5。在第四步中,我們發現在未  排序數組中最小數字是5。我們將其從 6 更改並將其添加到已排序的子數組中。
排序數組中最小數字是5。我們將其從 6 更改並將其添加到已排序的子數組中。 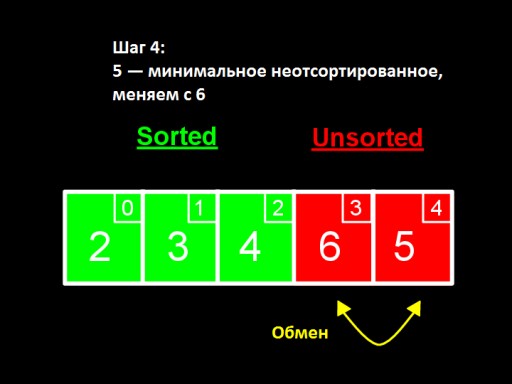 當未排序的數中只剩下一個數(最大的)時,這表示整個陣列已排序!
當未排序的數中只剩下一個數(最大的)時,這表示整個陣列已排序! 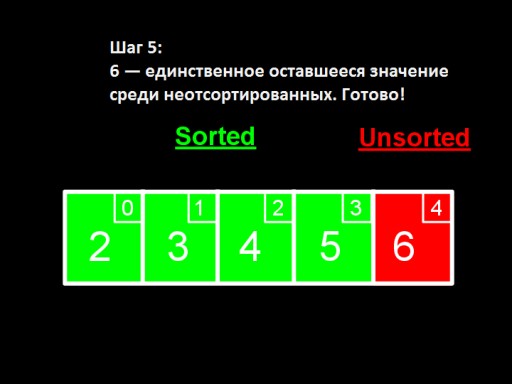 這就是數組實現在程式碼中的樣子。嘗試自己做一下。
這就是數組實現在程式碼中的樣子。嘗試自己做一下。  在最好和最壞的情況下,為了找到最小的未排序元素,我們必須將每個元素與未排序數組的每個元素進行比較,並且我們將在每次迭代時執行此操作。但我們不需要查看整個列表,而只需查看未排序的部分。這會改變演算法的速度嗎?第一步,對於 5 個元素的數組,我們進行 4 次比較,第二次比較 3 次,第三次比較 2 次。要獲得比較次數,我們需要將所有這些數字相加。我們得到總和
在最好和最壞的情況下,為了找到最小的未排序元素,我們必須將每個元素與未排序數組的每個元素進行比較,並且我們將在每次迭代時執行此操作。但我們不需要查看整個列表,而只需查看未排序的部分。這會改變演算法的速度嗎?第一步,對於 5 個元素的數組,我們進行 4 次比較,第二次比較 3 次,第三次比較 2 次。要獲得比較次數,我們需要將所有這些數字相加。我們得到總和  因此,演算法在最好和最壞情況下的預期速度是 θ(n 2 )。不是最有效的演算法!然而,出於教育目的和小數據集,它非常適用。
因此,演算法在最好和最壞情況下的預期速度是 θ(n 2 )。不是最有效的演算法!然而,出於教育目的和小數據集,它非常適用。
冒泡排序
冒泡排序演算法是最簡單的演算法之一。我們遍歷整個陣列並比較 2 個相鄰元素。如果它們的順序錯誤,我們就交換它們。在第一遍中,最小的元素將出現(“浮動”)在末尾(如果我們按降序排序)。如果上一個步驟中至少完成了一次交換,請重複第一步。讓我們對數組進行排序。 第一步:遍歷數組。演算法從前兩個元素 8 和 6 開始,並檢查它們的順序是否正確。8 > 6,所以我們交換它們。接下來我們來看第二個和第三個元素,現在是8和4。出於同樣的原因,我們交換它們。我們第三次比較 8 和 2。總共,我們進行了三次交換 (8, 6)、(8, 4)、(8, 2)。值 8 “浮動”到清單末端的正確位置。
第一步:遍歷數組。演算法從前兩個元素 8 和 6 開始,並檢查它們的順序是否正確。8 > 6,所以我們交換它們。接下來我們來看第二個和第三個元素,現在是8和4。出於同樣的原因,我們交換它們。我們第三次比較 8 和 2。總共,我們進行了三次交換 (8, 6)、(8, 4)、(8, 2)。值 8 “浮動”到清單末端的正確位置。  步驟2:交換(6,4)和(6,2)。6 現在位於倒數第二個位置,無需將其與已排序的清單「尾部」進行比較。
步驟2:交換(6,4)和(6,2)。6 現在位於倒數第二個位置,無需將其與已排序的清單「尾部」進行比較。  第三步:交換4和2。四個「漂浮」到正確的位置。
第三步:交換4和2。四個「漂浮」到正確的位置。  第四步:我們遍歷數組,但沒有什麼可以改變的。這表示數組已完全排序。
第四步:我們遍歷數組,但沒有什麼可以改變的。這表示數組已完全排序。 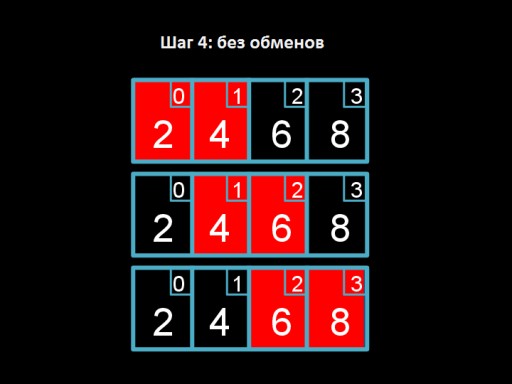 這是演算法程式碼。試著用 C 實現它! 冒泡排序在最壞的情況下(所有數字都是錯誤的)需要
這是演算法程式碼。試著用 C 實現它! 冒泡排序在最壞的情況下(所有數字都是錯誤的)需要 O(n 2 ) 時間,因為我們每次迭代需要執行 n 步,其中也有 n 步。事實上,與選擇排序演算法的情況一樣,時間會稍微少一些(n 2 /2 – n/2),但這可以忽略不計。在最好的情況下(如果所有元素都已經就位),我們可以分 n 步驟完成,即 Ω(n),因為我們只需要遍歷數組一次並確保所有元素都就位(即甚至 n-1 個元素)。
O(n 2 ) 時間,因為我們每次迭代需要執行 n 步,其中也有 n 步。事實上,與選擇排序演算法的情況一樣,時間會稍微少一些(n 2 /2 – n/2),但這可以忽略不計。在最好的情況下(如果所有元素都已經就位),我們可以分 n 步驟完成,即 Ω(n),因為我們只需要遍歷數組一次並確保所有元素都就位(即甚至 n-1 個元素)。
插入排序
這個演算法的主要想法是將我們的陣列分為兩部分,已排序和未排序。在演算法的每一步,數字都會從未排序的部分移動到已排序的部分。 讓我們使用下面的範例來了解插入排序的工作原理。在開始之前,所有元素都被視為未排序。
讓我們使用下面的範例來了解插入排序的工作原理。在開始之前,所有元素都被視為未排序。  步驟 1:取出第一個未排序的值 (3) 並將其插入已排序的子數組中。在這一步,整個排序子數組,它的開始和結束將是這三個。
步驟 1:取出第一個未排序的值 (3) 並將其插入已排序的子數組中。在這一步,整個排序子數組,它的開始和結束將是這三個。  步驟 2:由於 3 > 5,我們將把 5 插入到 3 右側的已排序子數組。
步驟 2:由於 3 > 5,我們將把 5 插入到 3 右側的已排序子數組。  步驟 3:現在我們將數字 2 插入到已排序數組中。我們從右到左比較2的值來找到正確的位置。由於 2 < 5 和 2 < 3,我們已經到達排序子陣列的開頭。因此,我們必須將 2 插入到 3 的左側。為此,請將 3 和 5 向右移動,以便有空間容納 2,並將其插入到陣列的開頭。
步驟 3:現在我們將數字 2 插入到已排序數組中。我們從右到左比較2的值來找到正確的位置。由於 2 < 5 和 2 < 3,我們已經到達排序子陣列的開頭。因此,我們必須將 2 插入到 3 的左側。為此,請將 3 和 5 向右移動,以便有空間容納 2,並將其插入到陣列的開頭。  步驟 4.我們很幸運:6 > 5,所以我們可以在數字 5 之後插入該數字。步驟
步驟 4.我們很幸運:6 > 5,所以我們可以在數字 5 之後插入該數字。步驟  5. 4 < 6 且 4 < 5,但 4 > 3。因此,我們知道必須插入 4 3 的右側。同樣,我們被迫將5 和6 向右移動,為4 創建間隙。
5. 4 < 6 且 4 < 5,但 4 > 3。因此,我們知道必須插入 4 3 的右側。同樣,我們被迫將5 和6 向右移動,為4 創建間隙。  完成!廣義演算法:取出n的每個未排序元素,並從右到左將其與已排序子數組中的值進行比較,直到找到n的合適位置(即找到第一個小於n的數的那一刻) 。然後,我們將這個數字右側的所有已排序元素向右移動,為 n 騰出空間,並將其插入那裡,從而擴展數組的已排序部分。對於每個未排序的元素 n,您需要:
完成!廣義演算法:取出n的每個未排序元素,並從右到左將其與已排序子數組中的值進行比較,直到找到n的合適位置(即找到第一個小於n的數的那一刻) 。然後,我們將這個數字右側的所有已排序元素向右移動,為 n 騰出空間,並將其插入那裡,從而擴展數組的已排序部分。對於每個未排序的元素 n,您需要:
- 確定數組已排序部分中應插入 n 的位置
- 將已排序的元素向右移動以建立 n 的間隙
- 將 n 插入到陣列已排序部分的結果間隙。

演算法的漸近速度
在最壞的情況下,我們將與第二個元素進行一次比較,與第三個元素進行兩次比較,依此類推。因此我們的速度是 O(n 2 )。充其量,我們將使用已經排序的陣列。我們從左到右建構的排序部分無需插入和移動元素,將花費 Ω(n) 時間。歸併排序
這個演算法是遞歸的;它將一個大型排序問題分解為子任務,子任務的執行使其更接近解決原始大問題。主要想法是將未排序的陣列分成兩部分,並對各個半部進行遞歸排序。 假設我們有 n 個元素要排序。如果n < 2,我們完成排序,否則我們將數組的左右部分分別排序,然後將它們組合起來。讓我們對數組進行排序,
假設我們有 n 個元素要排序。如果n < 2,我們完成排序,否則我們將數組的左右部分分別排序,然後將它們組合起來。讓我們對數組進行排序,  將其分為兩部分,繼續劃分,直到得到大小為 1 的子數組,這些子數組顯然已排序。
將其分為兩部分,繼續劃分,直到得到大小為 1 的子數組,這些子數組顯然已排序。  使用簡單的演算法可以在 O(n) 時間內合併兩個已排序的子數組:刪除每個子數組開頭的較小數字並將其插入到合併的數組中。重複直到所有元素都消失。
使用簡單的演算法可以在 O(n) 時間內合併兩個已排序的子數組:刪除每個子數組開頭的較小數字並將其插入到合併的數組中。重複直到所有元素都消失。 
 對於所有情況,合併排序都需要 O(nlog n) 時間。當我們在每個遞歸層級將數組分成兩半時,我們得到 log n。然後,合併子數組只需要 n 次比較。因此 O(nlog n)。歸併排序的最佳和最差情況是相同的,演算法的預期運行時間 = θ(nlog n)。該演算法是所考慮的演算法中最有效的。
對於所有情況,合併排序都需要 O(nlog n) 時間。當我們在每個遞歸層級將數組分成兩半時,我們得到 log n。然後,合併子數組只需要 n 次比較。因此 O(nlog n)。歸併排序的最佳和最差情況是相同的,演算法的預期運行時間 = θ(nlog n)。該演算法是所考慮的演算法中最有效的。 

GO TO FULL VERSION