int[] array ={10,2,10,3,1,2,5};for(int i =0; i < array.length; i++){System.out.println(array[i]);}
對於這段程式碼你有什麼想說的嗎?我們有一個循環,在該循環中我們將索引值 ( int i) 從 0 更改為數組中的最後一個元素。事實上,我們只是獲取數組中的每個元素並列印其內容。數組中的元素越多,執行程式碼所需的時間就越長。也就是說,如果 n 是元素的數量,則 n=10 時程式的執行時間將是 n=5 時的 2 倍。當我們的程式有一個循環時,執行時間會線性增加:元素越多,執行時間就越長。事實證明,上述程式碼的演算法在線性時間 (n) 內工作。在這種情況下,「演算法複雜度」被稱為 O(n)。這種表示法也稱為“大O”或“漸近行為”。但你可以簡單地記住「演算法的複雜性」。
最簡單的排序(冒泡排序)
所以,我們有一個陣列並且可以迭代它。偉大的。現在讓我們嘗試按升序對其進行排序。這對我們意味著什麼?這意味著給定兩個元素(例如,a=6,b=5),如果 a 大於 b(如果 a > b),我們必須交換 a 和 b。當我們按索引處理集合時(就像數組一樣),這對我們意味著什麼?這表示如果索引 a 的元素大於索引 b 的元素(array[a] > array[b]),則必須交換這些元素。改變位置通常稱為交換。有多種方法可以改變位置。但我們使用簡單、清晰、易記的程式碼:
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i-1);}}System.out.println(Arrays.toString(array));
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int left =0; left < array.length; left++){// Retrieve the value of the elementint value = array[left];// Move through the elements that are before the pulled elementint i = left -1;for(; i >=0; i--){// If a smaller value is pulled out, move the larger element furtherif(value < array[i]){
array[i +1]= array[i];}else{// If the pulled element is larger, stopbreak;}}// Insert the extracted value into the freed space
array[i +1]= value;}System.out.println(Arrays.toString(array));
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));for(int i =1; i < array.length; i++){if(array[i]< array[i -1]){swap(array, i, i -1);for(int z = i -1;(z -1)>=0; z--){if(array[z]< array[z -1]){swap(array, z, z -1);}else{break;}}}}System.out.println(Arrays.toString(array));
int[] array ={10,2,10,3,1,2,5};System.out.println(Arrays.toString(array));// Calculate the gap between the checked elementsint gap = array.length /2;// As long as there is a difference between the elementswhile(gap >=1){for(int right =0; right < array.length; right++){// Shift the right pointer until we can find one that// there won't be enough space between it and the element before itfor(int c = right - gap; c >=0; c -= gap){if(array[c]> array[c + gap]){swap(array, c, c + gap);}}}// Recalculate the gap
gap = gap /2;}System.out.println(Arrays.toString(array));
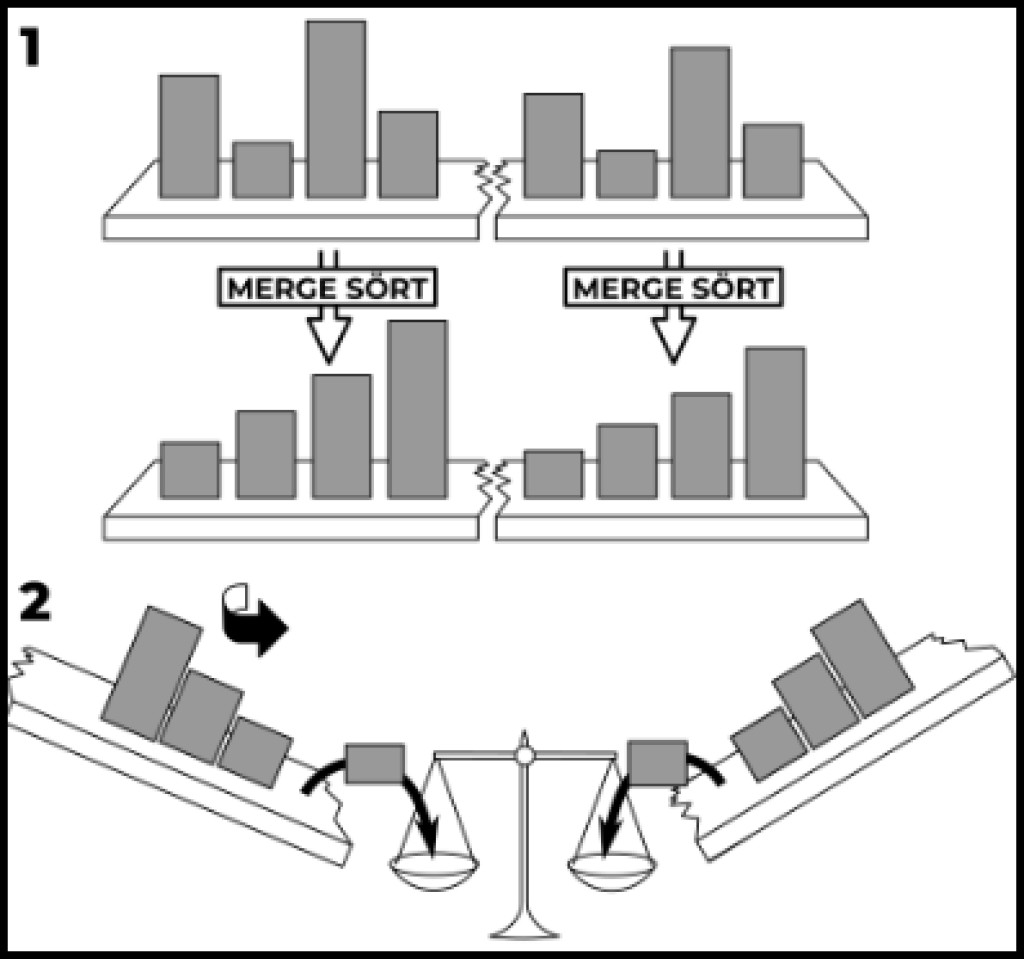
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}}
現在,讓我們為其添加一個主要操作。這是我們的超級方法及其實現的範例:
publicstaticvoidmergeSort(int[] source,int left,int right){// Choose a separator, i.e. split the input array in halfint delimiter = left +((right - left)/2)+1;// Execute this function recursively for the two halves (if we can split(if(delimiter >0&& right >(left +1)){mergeSort(source, left, delimiter -1);mergeSort(source, delimiter, right);}// Create a temporary array with the desired sizeint[] buffer =newint[right - left +1];// Starting from the specified left border, go through each elementint cursor = left;for(int i =0; i < buffer.length; i++){// We use the delimeter to point to the element from the right side// If delimeter > right, then there are no unadded elements left on the right sideif(delimiter > right || source[cursor]> source[delimiter]){
buffer[i]= source[cursor];
cursor++;}else{
buffer[i]= source[delimiter];
delimiter++;}}System.arraycopy(buffer,0, source, left, buffer.length);}
另一個有趣的排序演算法是計數排序。這種情況下的演算法複雜度將為 O(n+k),其中 n 是元素的數量,k 是元素的最大值。這個演算法有一個問題:我們需要知道數組中的最小值和最大值。以下是計數排序的範例實作:
publicstaticint[]countingSort(int[] theArray,int maxValue){// Array with "counters" ranging from 0 to the maximum valueint numCounts[]=newint[maxValue +1];// In the corresponding cell (index = value) we increase the counterfor(int num : theArray){
numCounts[num]++;}// Prepare array for sorted resultint[] sortedArray =newint[theArray.length];int currentSortedIndex =0;// go through the array with "counters"for(int n =0; n < numCounts.length; n++){int count = numCounts[n];// go by the number of valuesfor(int k =0; k < count; k++){
sortedArray[currentSortedIndex]= n;
currentSortedIndex++;}}return sortedArray;}
publicstaticvoidquickSort(int[] source,int leftBorder,int rightBorder){int leftMarker = leftBorder;int rightMarker = rightBorder;int pivot = source[(leftMarker + rightMarker)/2];do{// Move the left marker from left to right while element is less than pivotwhile(source[leftMarker]< pivot){
leftMarker++;}// Move the right marker until element is greater than pivotwhile(source[rightMarker]> pivot){
rightMarker--;}// Check if you don't need to swap elements pointed to by markersif(leftMarker <= rightMarker){// The left marker will only be less than the right marker if we have to swapif(leftMarker < rightMarker){int tmp = source[leftMarker];
source[leftMarker]= source[rightMarker];
source[rightMarker]= tmp;}// Move markers to get new borders
leftMarker++;
rightMarker--;}}while(leftMarker <= rightMarker);// Execute recursively for partsif(leftMarker < rightBorder){quickSort(source, leftMarker, rightBorder);}if(leftBorder < rightMarker){quickSort(source, leftBorder, rightMarker);}}
這裡的一切都很可怕,所以我們會弄清楚的。對於輸入數組int[]來源,我們設定兩個標記,左 (L) 和右 (R)。第一次呼叫時,它們會符合陣列的開頭和結尾。接下來,確定支撐元素,即pivot。之後,我們的任務是將小於 的值pivot向左移動pivot,將大於的值向右移動。為此,首先移動指針,L直到找到大於 的值pivot。如果沒有找到更小的值,則
L совпадёт с
pivot. Потом двигаем указатель
R пока не найдём меньшее, чем
pivot meaning. Если меньшее meaning не нашли, то
R совпадёт с
pivot. Далее, если указатель
L находится до указателя
R or совпадает с ним, то пытаемся выполнить обмен элементов, если элемент
L меньше, чем
R. Далее
L сдвигаем вправо на 1 позицию,
R сдвигаем влево на одну позицию. Когда левый маркер
L окажется за правым маркером
R это будет означать, что обмен закончен, слева от
pivot меньшие значения, справа от
pivot — большие значения. После этого рекурсивно вызываем такую же сортировку для участков массива от начала сортируемого участка до правого маркера и от левого маркера до конца сортируемого участка. Почему от начала до правого? Потому что в конце итерации так и получится, что правый маркер сдвинется настолько, что станет границей части слева. Этот алгоритм более сложный, чем простая sorting, поэтому его лучше зарисовать. Возьмём белый лист бумаги, запишем: 4 2 6 7 3 , а
Pivot по центру, т.е. число 6. Обведём его в круг. Под 4 напишем
L, под 3 напишем
R. 4 меньше чем 6, 2 меньше чем 6. Total,
L переместился на положение
pivot, т.к. по условию
L не может уйти дальше, чем
pivot. Напишем снова 4 2 6 7 3 , обведём 6 вкруг (
pivot) и поставим под ним
L. Теперь двигаем указатель
R. 3 меньше чем 6, поэтому ставим маркер
R на цифру 3. Так How 3 меньше, чем
pivot 6 выполняем
swap, т.е. обмен. Запишем результат: 4 2 3 7 6 , обводим 6 вкруг, т.к. он по прежнему
pivot. Указатель
L на цифре 3, указатель
R на цифре 6. Мы помним, что двигаем указатели до тех пор, пока
L не зайдём за
R.
L двигаем на следующую цифру. Тут хочется разобрать два варианта: если бы предпоследняя цифра была 7 и если бы она была не 7, а 1.
Предпоследня цифра 1: Сдвинули указатель
L на цифру 1, т.к. мы можем двигать
L до тех пор, пока указатель
L указывает на цифру, меньшую чем
pivot. А вот
R мы не можем сдвинуть с 6, т.к. R не мы можем двигать только если указатель
R указывает на цифру, которая больше чем
pivot.
swap не делаем, т.к. 1 меньше 6. Записываем положение: 4 2 3 1 6, обводим
pivot 6.
L сдвигается на
pivot и больше не двигается.
R тоже не двигается. Обмен не производим. Сдвигаем
L и
R на одну позицию и подписываем цифру 1 маркером
R, а
L получается вне числа. Т.к.
L вне числа — ничего не делаем, а вот часть 4 2 3 1 выписываем снова, т.к. это наша левая часть, меньшая, чем
pivot 6. Выделяем новый
pivot и начинаем всё снова )
Предпоследняя цифра 7: Сдвинули указать
L на цифру 7, правый указатель не можем двигать, т.к. он уже указывает на pivot. т.к. 7 больше, чем
pivot, то делаем
swap. Запишем результат: 4 2 3 6 7, обводим 6 кружком, т.к. он
pivot. Указатель
L теперь сдвигается на цифру 7, а указатель
R сдвигается на цифру 3. Часть от
L до конца нет смысла сортировать, т.к. там всего 1 элемент, а вот часть от 4 до указателя
R отправляем на сортировку. Выбираем
pivot и начинаем всё снова ) Может на первый взгляд показаться, что если расставить много одинаковых с
pivot значений, это сломает алгоритм, но это не так. Можно напридумывать каверзных вариантов и на бумажке убедиться, что всё правильно и подивиться, How такие простые действия предоставляют такой надёжный механизм. Единственный минус — такая sorting не является стабильной. Т.к. при выполнении обмена одинаковые элементы могут поменять свой порядок, если один из них встретился до
pivot до того, How другой элемент попал в часть до
pivot при помощи обмена. Материал:
Выше мы рассмотрели "джентельменский" набор алгоритмов сортировки, реализованных на Java. Алгоритмы вообще штука полезная, How с прикладной точки зрения, так и с точки зрения развития мышления. Некоторые из них попроще, некоторые посложнее. По Howим-то умные люди защищали различные работы на степени, а по другим писали толстые-толстые книги. Надеюсь, приложенный к статье материал позволит вам узнать ещё больше, так How это обзорная статья, которая и так получилась увесистой. И цель её — дать небольшое вступление. Про введение в алгоритмы можно так же прочитать ознакомиться с книгой "
Грокаем Алгоримы". Также мне нравится плэйлист от Jack Brown —
AQA Decision 1 1.01 Tracing an Algorithm. Ради интереса можно посмотреть на визуализацию алгоритмов на
sorting.at и
visualgo.net. Ну и весь Youtube к вашим услугам.









GO TO FULL VERSION