1. Знайомство із трирівневою архітектурою
Трирівнева архітектура – це найпоширеніша архітектура взаємодії в інтернеті. Вона з'явилася, коли серверну частину дворівневої архітектури розділили на дві частини: шар логіки та шар даних.
Виглядати це стало приблизно так:

Шар клієнта – це частина «розподіленої програми», яка відповідає за взаємодію з користувачем. Цей шар не повинен містити бізнес-логіку та зберігати критично важливі дані. Також він не повинен взаємодіяти з шаром бази даних безпосередньо, а лише через бізнес-логіку.
Однак якась логіка тут все ж є. По-перше, це взаємодія з користувачем через інтерфейс, валідація даних, що вводяться ним, робота з локальними файлами. Ще сюди можна віднести все, що стосується авторизації користувача та шифрування даних під час роботи з сервером.
По-друге, це нескладна логіка бізнесу. Наприклад, інтернет-магазин надіслав список товарів. На стороні клієнта ми можемо їх відсортувати, відфільтрувати. І примітивне зберігання даних тут теж є: кешування, кукі залогіненого користувача тощо.
Шар бізнес-логіки розташовується на другому рівні: на ньому зосереджена більша частина бізнес-логіки. За його межами залишаються лише фрагменти, що експортуються на клієнта, а також елементи логіки, занурені в базу даних (збережені процедури та тригери).

Дуже часто сервери бізнес-логіки містять не лише цю саму логіку, але й вирішують завдання масштабування: код розбивається на частини та розноситься на різны сервери. Деякі особливо популярны сервіси можуть запускатися на десятках серверів. Навантаженням між ними керує load balancer.
Серверні програми зазвичай проєктуються таким чином, щоб можна було легко запустити ще одну копію сервера, і вона почала працювати в кооперації з іншими його копіями. Тобто навіть у процесі написання серверного коду в тебе ніколи не буде гарантій, що твій статичний клас запущено в єдиному екземплярі.
Шар даних забезпечує зберігання даних і виноситься на окремий рівень, реалізується, зазвичай, засобами систем управління базами даних (СУБД), підключення до цього компоненту забезпечується лише з рівня сервера застосунків.
2. Причини відокремлення шару даних
Відділення шару даних у повноцінний третій шар відбулося з багатьох причин, але найголовніша з них — це зростання навантаження на сервер.
По-перше, бази даних почали вимагати багато пам'яті та процесорного часу на обробку даних. Тому їх почали виносити на окремі сервери.
Бекенд при збільшеному навантаженні можна було легко дублювати і підняти десять копій одного сервера, а дублювати базу даних не було змоги - база все ще залишалася єдиним і неподільним компонентом системи.
По-друге, бази даних стали розумними — у них виникла власна бізнес-логіка. Вони стали підтримувати процедури, що зберігаються, тригери, власні мови типу PLSQL. І навіть з'явилися програмісти, які почали писати код, який виконується всередині СУБД.
Усю логіку, яка не була зав'язана на даних, виносили в бекенд і паралельно запускали на десятках серверів. Все, що було критично зав'язано на даних, залишалося всередині СУБД. Там проблеми навантаження, яке зросло, доводилося вирішувати своїми методами:
- Кластер бази даних — група серверів БД, які зберігають одні й самі дані і синхронізують їх у певному протоколі.
- Шардування — дані дробляться на логічні блоки і розносяться на різні сервери БД. Дуже складно підтримувати зміни БД за такого підходу.
- Підхід NoSQL — зберігання даних у БД, які побудовані для зберігання величезної кількості даних. Часто це навіть не бази, а специфічні файлові сховища. Дуже бідний функціонал у порівнянні з реляційними базами даних.
- Кешування даних. Замість простого кешу на рівні бази даних з'явилися цілі СУБД для кешування, які зберігали результат лише в пам'яті.
Зрозуміло, що для управління цим зоопарком серверних технологій потрібні були окремі люди та/або цілі команди, що призвело до винесення шару даних в окремий шар.
Важливо! Усі передові технології народжуються у надрах великих ІТ-корпорацій, коли старі підходи вже не можуть впоратися з новими викликами. Винесення баз даних в окремий шар вигадав не якийсь програміст, а група інженерів десь у надрах Oracle або IBM.
Цікаво! Коли Цукерберг починав писати Facebook, він працював просто на PHP+MySQL. Коли кількість користувачів досягла мільйонів, написали спеціальний транслятор, який переклав весь PHP код на C++ і скомпілювали його в нативний машинний код.
Також MySQL не здатний зберігати дані мільярдів користувачів, тому Facebook розробив концепцію NoSQL баз даних і написав потужну серверну NoSQL-СУБД — Cassandra. До речі, вона повністю написана Java.
3. Неоднозначність розташування логіки програми
І хоча трирівнева архітектура практично однозначно розподіляє ролі між її частинами, не завжди можна правильно визначити, в яке саме місце системи потрібно додати нову частину бізнес-логіки (новий код).
Приклад такої неоднозначності бачимо на малюнку нижче:
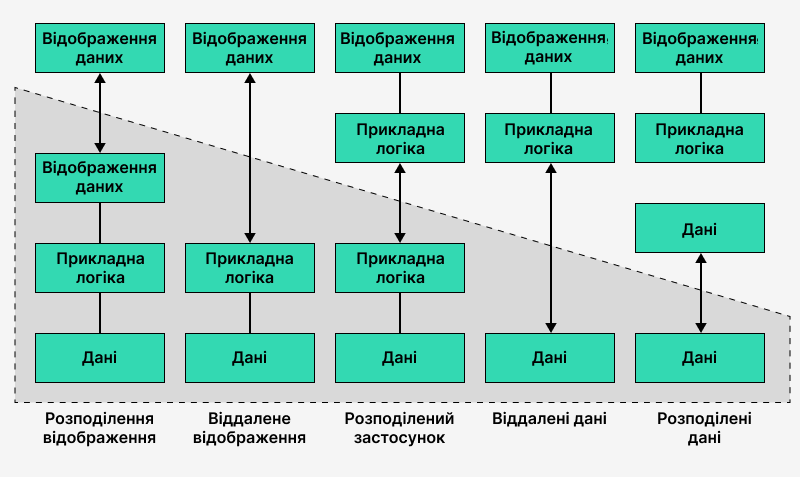
Сірим фоном залита серверна частина, білим — клієнтська. Хороший приклад останнього підходу (крайній правий варіант) — це сучасні мобільні програми. На стороні клієнта (на телефоні) міститься представлення (відображення), логіка та дані. І лише інколи ці дані синхронізуються із сервером.
Приклад крайнього лівого варіанту — це типовий PHP-сервер, у якого вся логіка знаходиться на сервері, і він віддає клієнту вже статичний HTML. Десь між цими двома крайніми варіантами і буде ваш проєкт.
На початку роботи, після знайомства з проєктом, тобі потрібно буде радитися з програмістами, які працюють над ним, щодо місць, де тобі краще реалізувати логіку чергового завдання.
Не соромся так робити. По-перше, до чужого монастиря зі своїм статутом не лізуть. По-друге, всім буде простіше (і тобі теж) знаходити потрібний код там, де ти очікуєш його знайти.
ПЕРЕЙДІТЬ В ПОВНУ ВЕРСІЮ