哈佛编程基础课程讲座 CS50 CS50 作业,第 3 周,第 1 部分 CS50 作业,第 3 周,第 2 部分
![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 1]() 但在某些时候,二次函数将取代线性函数,这是没有办法解决的。另一个渐近复杂度是对数时间或 O(log n)。随着 n 的增加,这个函数增加得非常缓慢。O(log n) 是经典二分搜索算法在排序数组中的运行时间(还记得讲座中撕破的电话簿吗?)。将数组一分为二,然后选择元素所在的一半,这样,每次将搜索区域缩小一半,我们就搜索该元素。
但在某些时候,二次函数将取代线性函数,这是没有办法解决的。另一个渐近复杂度是对数时间或 O(log n)。随着 n 的增加,这个函数增加得非常缓慢。O(log n) 是经典二分搜索算法在排序数组中的运行时间(还记得讲座中撕破的电话簿吗?)。将数组一分为二,然后选择元素所在的一半,这样,每次将搜索区域缩小一半,我们就搜索该元素。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 2]() 如果我们立即偶然发现我们正在寻找的东西,第一次将我们的数据数组分成两半,会发生什么?有一个术语表示最佳时间 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情况下(无论数组大小如何,都在恒定时间内查找)。如果要搜索的元素是第一个元素,则线性搜索的运行时间为 O(n) 和 Ω(1)。另一个符号是 theta (θ(n))。当最好和最差的选项相同时使用它。这适用于我们将字符串长度存储在单独变量中的示例,因此对于任何长度,引用该变量就足够了。对于该算法,最好和最差情况分别为 Ω(1) 和 O(1)。这意味着算法在时间 θ(1) 内运行。
如果我们立即偶然发现我们正在寻找的东西,第一次将我们的数据数组分成两半,会发生什么?有一个术语表示最佳时间 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情况下(无论数组大小如何,都在恒定时间内查找)。如果要搜索的元素是第一个元素,则线性搜索的运行时间为 O(n) 和 Ω(1)。另一个符号是 theta (θ(n))。当最好和最差的选项相同时使用它。这适用于我们将字符串长度存储在单独变量中的示例,因此对于任何长度,引用该变量就足够了。对于该算法,最好和最差情况分别为 Ω(1) 和 O(1)。这意味着算法在时间 θ(1) 内运行。
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 3]() LinearSearch 函数接收两个参数作为输入 - 键 key 和数组 array[]。键是所需的值,在前面的示例中 key = 0。数组是我们要查找的数字列表。会看透。如果我们没有找到任何东西,该函数将返回-1(数组中不存在的位置)。如果线性搜索找到所需的元素,该函数将返回所需元素在数组中的位置。线性搜索的好处是它适用于任何数组,无论元素的顺序如何:我们仍然会遍历整个数组。这也是他的弱点。如果需要在按顺序排序的 200 个数字的数组中查找数字 198,则 for 循环将执行 198 步。
LinearSearch 函数接收两个参数作为输入 - 键 key 和数组 array[]。键是所需的值,在前面的示例中 key = 0。数组是我们要查找的数字列表。会看透。如果我们没有找到任何东西,该函数将返回-1(数组中不存在的位置)。如果线性搜索找到所需的元素,该函数将返回所需元素在数组中的位置。线性搜索的好处是它适用于任何数组,无论元素的顺序如何:我们仍然会遍历整个数组。这也是他的弱点。如果需要在按顺序排序的 200 个数字的数组中查找数字 198,则 for 循环将执行 198 步。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 4]() 您可能已经猜到哪种方法更适合排序数组?
您可能已经猜到哪种方法更适合排序数组?
![Java-университет]()
![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 5]() 线性地需要很长时间。如果我们使用“将目录撕成两半的方法”,我们就可以直接找到 Jasmine,并且可以安全地丢弃列表的前半部分,并意识到 Mickey 不可能在那里。
线性地需要很长时间。如果我们使用“将目录撕成两半的方法”,我们就可以直接找到 Jasmine,并且可以安全地丢弃列表的前半部分,并意识到 Mickey 不可能在那里。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 6]() 使用相同的原理,我们丢弃第二列。继续这个策略,我们只需几步就可以找到米奇。
使用相同的原理,我们丢弃第二列。继续这个策略,我们只需几步就可以找到米奇。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 7]() 让我们找到数字 144。我们将列表分成两半,得到数字 13。我们评估我们要查找的数字是大于还是小于 13。13
让我们找到数字 144。我们将列表分成两半,得到数字 13。我们评估我们要查找的数字是大于还是小于 13。13 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 8]() < 144,因此我们可以忽略 左边的所有内容13 和这个数字本身。现在我们的搜索列表看起来像这样:
< 144,因此我们可以忽略 左边的所有内容13 和这个数字本身。现在我们的搜索列表看起来像这样: ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 9]() 有偶数个元素,所以我们选择选择“中间”(靠近开头或结尾)的原则。假设我们选择了接近开始的策略。在这种情况下,我们的“中间”= 55。55
有偶数个元素,所以我们选择选择“中间”(靠近开头或结尾)的原则。假设我们选择了接近开始的策略。在这种情况下,我们的“中间”= 55。55 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 10]() < 144。我们再次丢弃列表的左半部分。对我们来说幸运的是,下一个平均数字是 144。
< 144。我们再次丢弃列表的左半部分。对我们来说幸运的是,下一个平均数字是 144。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 11]() 我们仅用三步就使用二分搜索在 13 元素数组中找到了 144。线性搜索最多需要 12 个步骤即可处理相同的情况。由于该算法每一步都会将数组中的元素数量减少一半,因此它将在渐近时间 O(log n) 内找到所需的元素,其中 n 是列表中的元素数量。也就是说,在我们的例子中,渐近时间 = O(log 13)(略多于三)。二分查找函数的伪代码:
我们仅用三步就使用二分搜索在 13 元素数组中找到了 144。线性搜索最多需要 12 个步骤即可处理相同的情况。由于该算法每一步都会将数组中的元素数量减少一半,因此它将在渐近时间 O(log n) 内找到所需的元素,其中 n 是列表中的元素数量。也就是说,在我们的例子中,渐近时间 = O(log 13)(略多于三)。二分查找函数的伪代码: ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 12]() 该函数接受 4 个参数作为输入:所需的键、数据数组 array[],所需的键位于其中,min 和 max 是指向数组中最大和最小数的指针,其中我们正在研究算法的这一步。对于我们的例子,最初给出了下图:
该函数接受 4 个参数作为输入:所需的键、数据数组 array[],所需的键位于其中,min 和 max 是指向数组中最大和最小数的指针,其中我们正在研究算法的这一步。对于我们的例子,最初给出了下图: ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 13]() 让我们进一步分析代码。中点是我们数组的中间。它取决于极值点并在极值点之间居中。找到中间值后,我们检查它是否小于我们的关键数字。
让我们进一步分析代码。中点是我们数组的中间。它取决于极值点并在极值点之间居中。找到中间值后,我们检查它是否小于我们的关键数字。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 14]() 如果是这样,那么 key 也大于中间左边的任何数字,我们可以再次调用二元函数,只是现在我们的 min = midpoint + 1。如果结果是 key < midpoint,我们可以丢弃那个数字本身和所有的数字,就在他的右边。我们对数组进行二分搜索,从数字 min 到值 (中点 – 1)。
如果是这样,那么 key 也大于中间左边的任何数字,我们可以再次调用二元函数,只是现在我们的 min = midpoint + 1。如果结果是 key < midpoint,我们可以丢弃那个数字本身和所有的数字,就在他的右边。我们对数组进行二分搜索,从数字 min 到值 (中点 – 1)。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 15]() 最后,第三个分支:如果中点的值既不大于也不小于key,则只能是所需的数字。在这种情况下,我们返回它并完成程序。
最后,第三个分支:如果中点的值既不大于也不小于key,则只能是所需的数字。在这种情况下,我们返回它并完成程序。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 16]() 最后,可能会出现你要查找的数字根本不在数组中的情况。考虑到这种情况,我们执行以下检查:
最后,可能会出现你要查找的数字根本不在数组中的情况。考虑到这种情况,我们执行以下检查: ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 17]() 我们返回 (-1) 表示我们没有找到任何东西。您已经知道二分查找需要对数组进行排序。因此,如果我们有一个未排序的数组,需要在其中查找某个元素,我们有两个选择:
我们返回 (-1) 表示我们没有找到任何东西。您已经知道二分查找需要对数组进行排序。因此,如果我们有一个未排序的数组,需要在其中查找某个元素,我们有两个选择:
![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 18]() 注意:“程序员”树的根与真正的根不同,它位于顶部。每个单元称为顶点,顶点之间通过边连接。树的根是单元号 13。顶点 3 的左子树在下图中以颜色突出显示:
注意:“程序员”树的根与真正的根不同,它位于顶部。每个单元称为顶点,顶点之间通过边连接。树的根是单元号 13。顶点 3 的左子树在下图中以颜色突出显示: ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 19]() 我们的树满足二叉树的所有要求。这意味着它的每个左子树只包含小于或等于顶点值的值,而右子树只包含大于或等于顶点值的值。左子树和右子树本身都是二叉子树。构造二叉树的方法并不是唯一的方法:在下图中,您可以看到同一组数字的另一种选择,并且在实践中可能有很多。
我们的树满足二叉树的所有要求。这意味着它的每个左子树只包含小于或等于顶点值的值,而右子树只包含大于或等于顶点值的值。左子树和右子树本身都是二叉子树。构造二叉树的方法并不是唯一的方法:在下图中,您可以看到同一组数字的另一种选择,并且在实践中可能有很多。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 20]() 这种结构有助于进行搜索:我们每次从上到左、下移动来找到最小值。
这种结构有助于进行搜索:我们每次从上到左、下移动来找到最小值。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 21]() 如果你需要找到最大的数字,我们从上到下,再到右边。找到一个不是最小值或最大值的数字也很简单。我们从根部向左或向右下降,具体取决于我们的顶点是比我们要寻找的顶点更大还是更小。因此,如果我们需要找到数字 89,我们会经过以下路径:
如果你需要找到最大的数字,我们从上到下,再到右边。找到一个不是最小值或最大值的数字也很简单。我们从根部向左或向右下降,具体取决于我们的顶点是比我们要寻找的顶点更大还是更小。因此,如果我们需要找到数字 89,我们会经过以下路径: ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 22]() 您也可以按排序顺序显示数字。例如,如果我们需要按升序显示所有数字,我们就取出左子树,并从最左边的顶点开始向上。在树上添加一些东西也很容易。最重要的是要记住结构。假设我们需要将值 7 添加到树中。让我们转到根并检查。数字 7 < 13,所以我们向左走。我们在那里看到 5,然后向右移动,因为 7 > 5。此外,由于 7 > 8 和 8 没有后代,因此我们从 8 向左构建一个分支,并将 7 附加到它。您还可以
您也可以按排序顺序显示数字。例如,如果我们需要按升序显示所有数字,我们就取出左子树,并从最左边的顶点开始向上。在树上添加一些东西也很容易。最重要的是要记住结构。假设我们需要将值 7 添加到树中。让我们转到根并检查。数字 7 < 13,所以我们向左走。我们在那里看到 5,然后向右移动,因为 7 > 5。此外,由于 7 > 8 和 8 没有后代,因此我们从 8 向左构建一个分支,并将 7 附加到它。您还可以 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 23]()
![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 24]() 从树,但这有点复杂。我们需要考虑三种不同的删除场景。
从树,但这有点复杂。我们需要考虑三种不同的删除场景。
![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 26]() 所有数字都将简单地添加到前一个数字的右侧分支中。如果我们想找到一个数字,我们别无选择,只能顺着链条往下走。
所有数字都将简单地添加到前一个数字的右侧分支中。如果我们想找到一个数字,我们别无选择,只能顺着链条往下走。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 27]() 它并不比线性搜索更好。还有其他更复杂的数据结构。但我们暂时不考虑它们。这么说吧,要解决从排序列表构造树的问题,您可以随机混合输入数据。
它并不比线性搜索更好。还有其他更复杂的数据结构。但我们暂时不考虑它们。这么说吧,要解决从排序列表构造树的问题,您可以随机混合输入数据。
![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 28]() 主要思想是将我们的列表分为两部分:已排序和未排序。在算法的每个步骤中,都会将一个新数字从未排序部分移动到已排序部分,依此类推,直到所有数字都位于已排序部分中。
主要思想是将我们的列表分为两部分:已排序和未排序。在算法的每个步骤中,都会将一个新数字从未排序部分移动到已排序部分,依此类推,直到所有数字都位于已排序部分中。
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 29]() 我们在数组的未排序部分(即在这一步 - 在整个数组中)找到最小数。这个数字是2。现在我们用未排序的第一个来改变它,并将它放在排序数组的末尾(在这一步中放在第一位)。在此步骤中,这是数组中的第一个数字,即 3。
我们在数组的未排序部分(即在这一步 - 在整个数组中)找到最小数。这个数字是2。现在我们用未排序的第一个来改变它,并将它放在排序数组的末尾(在这一步中放在第一位)。在此步骤中,这是数组中的第一个数字,即 3。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 30]() 第二步。我们不看数字 2;它已经在已排序的子数组中了。我们开始寻找最小值,从第二个元素开始,这是5。我们确保3是未排序中的最小值,5是未排序中的第一个。我们交换它们并将 3 添加到已排序的子数组中。
第二步。我们不看数字 2;它已经在已排序的子数组中了。我们开始寻找最小值,从第二个元素开始,这是5。我们确保3是未排序中的最小值,5是未排序中的第一个。我们交换它们并将 3 添加到已排序的子数组中。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 31]() 在第三步中,我们看到未排序子数组中的最小数字是4。我们将其更改为未排序子数组中的第一个数字 - 5。在第四步中,我们发现在
在第三步中,我们看到未排序子数组中的最小数字是4。我们将其更改为未排序子数组中的第一个数字 - 5。在第四步中,我们发现在 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 32]() 未排序数组中最小数字是5。我们将其从 6 更改并将其添加到已排序的子数组中。
未排序数组中最小数字是5。我们将其从 6 更改并将其添加到已排序的子数组中。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 33]() 当未排序的数中只剩下一个数(最大的)时,这意味着整个数组已排序!
当未排序的数中只剩下一个数(最大的)时,这意味着整个数组已排序! ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 34]() 这就是数组实现在代码中的样子。尝试自己做一下。
这就是数组实现在代码中的样子。尝试自己做一下。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 35]() 在最好和最坏的情况下,为了找到最小的未排序元素,我们必须将每个元素与未排序数组的每个元素进行比较,并且我们将在每次迭代时执行此操作。但我们不需要查看整个列表,而只需查看未排序的部分。这会改变算法的速度吗?第一步,对于 5 个元素的数组,我们进行 4 次比较,第二次比较 3 次,第三次比较 2 次。要获得比较次数,我们需要将所有这些数字相加。我们得到总和
在最好和最坏的情况下,为了找到最小的未排序元素,我们必须将每个元素与未排序数组的每个元素进行比较,并且我们将在每次迭代时执行此操作。但我们不需要查看整个列表,而只需查看未排序的部分。这会改变算法的速度吗?第一步,对于 5 个元素的数组,我们进行 4 次比较,第二次比较 3 次,第三次比较 2 次。要获得比较次数,我们需要将所有这些数字相加。我们得到总和 ![公式]() 因此,算法在最好和最坏情况下的预期速度是 θ(n 2 )。不是最有效的算法!然而,出于教育目的和小数据集,它非常适用。
因此,算法在最好和最坏情况下的预期速度是 θ(n 2 )。不是最有效的算法!然而,出于教育目的和小数据集,它非常适用。
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 36]() 第一步:遍历数组。该算法从前两个元素 8 和 6 开始,并检查它们的顺序是否正确。8 > 6,所以我们交换它们。接下来我们看第二个和第三个元素,现在是8和4。出于同样的原因,我们交换它们。我们第三次比较 8 和 2。总共,我们进行了三次交换 (8, 6)、(8, 4)、(8, 2)。值 8 “浮动”到列表末尾的正确位置。
第一步:遍历数组。该算法从前两个元素 8 和 6 开始,并检查它们的顺序是否正确。8 > 6,所以我们交换它们。接下来我们看第二个和第三个元素,现在是8和4。出于同样的原因,我们交换它们。我们第三次比较 8 和 2。总共,我们进行了三次交换 (8, 6)、(8, 4)、(8, 2)。值 8 “浮动”到列表末尾的正确位置。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 37]() 步骤2:交换(6,4)和(6,2)。6 现在位于倒数第二个位置,无需将其与已排序的列表“尾部”进行比较。
步骤2:交换(6,4)和(6,2)。6 现在位于倒数第二个位置,无需将其与已排序的列表“尾部”进行比较。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 38]() 第三步:交换4和2。四个“漂浮”到正确的位置。
第三步:交换4和2。四个“漂浮”到正确的位置。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 39]() 第四步:我们遍历数组,但没有什么可以改变的。这表明数组已完全排序。
第四步:我们遍历数组,但没有什么可以改变的。这表明数组已完全排序。 ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 40]() 这是算法代码。尝试用 C 实现它! 冒泡排序在最坏的情况下(所有数字都是错误的)需要
这是算法代码。尝试用 C 实现它! 冒泡排序在最坏的情况下(所有数字都是错误的)需要![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 43]() O(n 2 ) 时间,因为我们每次迭代需要执行 n 步,其中也有 n 步。事实上,与选择排序算法的情况一样,时间会稍微少一些(n 2 /2 – n/2),但这可以忽略不计。在最好的情况下(如果所有元素都已经就位),我们可以分 n 步完成,即 Ω(n),因为我们只需要遍历数组一次并确保所有元素都就位(即甚至 n-1 个元素)。
O(n 2 ) 时间,因为我们每次迭代需要执行 n 步,其中也有 n 步。事实上,与选择排序算法的情况一样,时间会稍微少一些(n 2 /2 – n/2),但这可以忽略不计。在最好的情况下(如果所有元素都已经就位),我们可以分 n 步完成,即 Ω(n),因为我们只需要遍历数组一次并确保所有元素都就位(即甚至 n-1 个元素)。
![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 41]() 让我们使用下面的示例来了解插入排序的工作原理。在开始之前,所有元素都被视为未排序。
让我们使用下面的示例来了解插入排序的工作原理。在开始之前,所有元素都被视为未排序。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 42]() 步骤 1:取出第一个未排序的值 (3) 并将其插入已排序的子数组中。在这一步,整个排序子数组,它的开始和结束将是这三个。
步骤 1:取出第一个未排序的值 (3) 并将其插入已排序的子数组中。在这一步,整个排序子数组,它的开始和结束将是这三个。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 43]() 步骤 2:由于 3 > 5,我们将把 5 插入到 3 右侧的已排序子数组中。
步骤 2:由于 3 > 5,我们将把 5 插入到 3 右侧的已排序子数组中。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 44]() 步骤 3:现在我们将数字 2 插入到已排序数组中。我们从右到左比较2的值来找到正确的位置。由于 2 < 5 和 2 < 3,我们已经到达排序子数组的开头。因此,我们必须将 2 插入到 3 的左侧。为此,请将 3 和 5 向右移动,以便有空间容纳 2,并将其插入到数组的开头。
步骤 3:现在我们将数字 2 插入到已排序数组中。我们从右到左比较2的值来找到正确的位置。由于 2 < 5 和 2 < 3,我们已经到达排序子数组的开头。因此,我们必须将 2 插入到 3 的左侧。为此,请将 3 和 5 向右移动,以便有空间容纳 2,并将其插入到数组的开头。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 45]() 步骤 4.我们很幸运:6 > 5,所以我们可以在数字 5 之后插入该数字。 步骤
步骤 4.我们很幸运:6 > 5,所以我们可以在数字 5 之后插入该数字。 步骤 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 46]() 5. 4 < 6 且 4 < 5,但 4 > 3。因此,我们知道必须插入 4 3 的右侧。同样,我们被迫将 5 和 6 向右移动,为 4 创建间隙。
5. 4 < 6 且 4 < 5,但 4 > 3。因此,我们知道必须插入 4 3 的右侧。同样,我们被迫将 5 和 6 向右移动,为 4 创建间隙。 ![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 47]() 完成!广义算法:取出n的每个未排序元素,并从右到左将其与已排序子数组中的值进行比较,直到找到n的合适位置(即找到第一个小于n的数的那一刻) 。然后,我们将这个数字右侧的所有已排序元素向右移动,为 n 腾出空间,并将其插入那里,从而扩展数组的已排序部分。对于每个未排序的元素 n,您需要:
完成!广义算法:取出n的每个未排序元素,并从右到左将其与已排序子数组中的值进行比较,直到找到n的合适位置(即找到第一个小于n的数的那一刻) 。然后,我们将这个数字右侧的所有已排序元素向右移动,为 n 腾出空间,并将其插入那里,从而扩展数组的已排序部分。对于每个未排序的元素 n,您需要:
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 48]()
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 49]() 假设我们有 n 个元素要排序。如果n < 2,我们完成排序,否则我们将数组的左右部分分别排序,然后将它们组合起来。让我们对数组进行排序,
假设我们有 n 个元素要排序。如果n < 2,我们完成排序,否则我们将数组的左右部分分别排序,然后将它们组合起来。让我们对数组进行排序, ![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 50]() 将其分为两部分,继续划分,直到得到大小为 1 的子数组,这些子数组显然已排序。
将其分为两部分,继续划分,直到得到大小为 1 的子数组,这些子数组显然已排序。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 51]() 使用简单的算法可以在 O(n) 时间内合并两个已排序的子数组:删除每个子数组开头的较小数字并将其插入到合并的数组中。重复直到所有元素都消失。
使用简单的算法可以在 O(n) 时间内合并两个已排序的子数组:删除每个子数组开头的较小数字并将其插入到合并的数组中。重复直到所有元素都消失。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 52]()
![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 56]() 对于所有情况,合并排序都需要 O(nlog n) 时间。当我们在每个递归级别将数组分成两半时,我们得到 log n。然后,合并子数组只需要 n 次比较。因此 O(nlog n)。归并排序的最佳和最差情况是相同的,算法的预期运行时间 = θ(nlog n)。该算法是所考虑的算法中最有效的。
对于所有情况,合并排序都需要 O(nlog n) 时间。当我们在每个递归级别将数组分成两半时,我们得到 log n。然后,合并子数组只需要 n 次比较。因此 O(nlog n)。归并排序的最佳和最差情况是相同的,算法的预期运行时间 = θ(nlog n)。该算法是所考虑的算法中最有效的。 ![CS50 附加材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 53]()
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 58]()
渐近符号
实时测量算法的速度(以秒和分钟为单位)并不容易。一个程序可能比另一个程序运行得慢,并不是因为它本身效率低下,而是因为操作系统缓慢、与硬件不兼容、计算机内存被其他进程占用……为了衡量算法的有效性,发明了通用概念,无论程序运行的环境如何。问题的渐近复杂性是使用 Big O 表示法来衡量的。设 f(x) 和 g(x) 是在 x0 的某个邻域中定义的函数,并且 g 在那里不消失。如果存在常数 C>,则对于 (x -> x0),f 比 g 大“O” 0 ,对于来自点 x0 的某个邻域的所有 x,不等式成立。|f(x)| <= C |g(x)| 稍微不那么严格:如果存在常数 C>0,则 f 大于 g,这对于所有 x > x0 f(x) <= C*g(x) 不要害怕正式定义!本质上,它决定了当输入数据量增长到无穷大时程序运行时间的渐近增加。例如,您正在比较对 1000 个元素和 10 个元素的数组进行排序,您需要了解程序的运行时间将如何增加。或者,您需要通过逐个字符计算字符串的长度,并为每个字符加 1: c - 1 a - 2 t - 3 其渐近速度 = O(n),其中 n 是单词中的字母数。如果按照这个原则来统计,统计整行所需的时间与字符数成正比。计算 20 个字符的字符串中的字符数所需的时间是计算 10 个字符的字符串中的字符数的两倍。想象一下,在长度变量中,您存储的值等于字符串中的字符数。例如,length = 1000。要获取字符串的长度,只需访问该变量即可,甚至不需要查看字符串本身。而且无论我们如何改变长度,我们总是可以访问这个变量。在这种情况下,渐近速度 = O(1)。更改输入数据不会改变此类任务的速度;搜索在恒定时间内完成。在这种情况下,程序是渐近常数。缺点:您会浪费计算机内存来存储额外的变量并花费额外的时间来更新其值。如果您认为线性时间很糟糕,我们可以向您保证它可能会更糟。例如,O(n 2 )。这种表示法意味着随着 n 的增长,迭代元素(或其他操作)所需的时间将越来越急剧地增长。但对于较小的 n,渐近速度为 O(n 2 ) 的算法可以比渐近速度为 O(n) 的算法运行得更快。  但在某些时候,二次函数将取代线性函数,这是没有办法解决的。另一个渐近复杂度是对数时间或 O(log n)。随着 n 的增加,这个函数增加得非常缓慢。O(log n) 是经典二分搜索算法在排序数组中的运行时间(还记得讲座中撕破的电话簿吗?)。将数组一分为二,然后选择元素所在的一半,这样,每次将搜索区域缩小一半,我们就搜索该元素。
但在某些时候,二次函数将取代线性函数,这是没有办法解决的。另一个渐近复杂度是对数时间或 O(log n)。随着 n 的增加,这个函数增加得非常缓慢。O(log n) 是经典二分搜索算法在排序数组中的运行时间(还记得讲座中撕破的电话簿吗?)。将数组一分为二,然后选择元素所在的一半,这样,每次将搜索区域缩小一半,我们就搜索该元素。  如果我们立即偶然发现我们正在寻找的东西,第一次将我们的数据数组分成两半,会发生什么?有一个术语表示最佳时间 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情况下(无论数组大小如何,都在恒定时间内查找)。如果要搜索的元素是第一个元素,则线性搜索的运行时间为 O(n) 和 Ω(1)。另一个符号是 theta (θ(n))。当最好和最差的选项相同时使用它。这适用于我们将字符串长度存储在单独变量中的示例,因此对于任何长度,引用该变量就足够了。对于该算法,最好和最差情况分别为 Ω(1) 和 O(1)。这意味着算法在时间 θ(1) 内运行。
如果我们立即偶然发现我们正在寻找的东西,第一次将我们的数据数组分成两半,会发生什么?有一个术语表示最佳时间 - Omega-large 或 Ω(n)。在二分查找 = Ω(1) 的情况下(无论数组大小如何,都在恒定时间内查找)。如果要搜索的元素是第一个元素,则线性搜索的运行时间为 O(n) 和 Ω(1)。另一个符号是 theta (θ(n))。当最好和最差的选项相同时使用它。这适用于我们将字符串长度存储在单独变量中的示例,因此对于任何长度,引用该变量就足够了。对于该算法,最好和最差情况分别为 Ω(1) 和 O(1)。这意味着算法在时间 θ(1) 内运行。
线性搜索
当您打开网络浏览器,在社交网络上查找页面、信息、朋友时,您就是在进行搜索,就像在商店中试图找到一双合适的鞋子一样。您可能已经注意到,秩序对您的搜索方式有很大影响。如果您的衣柜里有所有衬衫,那么在其中找到您需要的一件通常比在房间各处没有系统的那些分散的衬衫中更容易找到您需要的一件。线性搜索是一种逐一顺序搜索的方法。当您从上到下查看 Google 搜索结果时,您正在使用线性搜索。 例子。假设我们有一个数字列表:2 4 0 5 3 7 8 1 我们需要找到 0。我们马上就能看到它,但计算机程序不能那样工作。她从列表的开头开始,看到数字 2。然后她检查,2=0?事实并非如此,所以她继续并转向第二个角色。那里也有失败等待着她,只有在第三个位置,算法才能找到所需的数字。线性搜索的伪代码:  LinearSearch 函数接收两个参数作为输入 - 键 key 和数组 array[]。键是所需的值,在前面的示例中 key = 0。数组是我们要查找的数字列表。会看透。如果我们没有找到任何东西,该函数将返回-1(数组中不存在的位置)。如果线性搜索找到所需的元素,该函数将返回所需元素在数组中的位置。线性搜索的好处是它适用于任何数组,无论元素的顺序如何:我们仍然会遍历整个数组。这也是他的弱点。如果需要在按顺序排序的 200 个数字的数组中查找数字 198,则 for 循环将执行 198 步。
LinearSearch 函数接收两个参数作为输入 - 键 key 和数组 array[]。键是所需的值,在前面的示例中 key = 0。数组是我们要查找的数字列表。会看透。如果我们没有找到任何东西,该函数将返回-1(数组中不存在的位置)。如果线性搜索找到所需的元素,该函数将返回所需元素在数组中的位置。线性搜索的好处是它适用于任何数组,无论元素的顺序如何:我们仍然会遍历整个数组。这也是他的弱点。如果需要在按顺序排序的 200 个数字的数组中查找数字 198,则 for 循环将执行 198 步。  您可能已经猜到哪种方法更适合排序数组?
您可能已经猜到哪种方法更适合排序数组?

二分查找和树
想象一下,您有一个按字母顺序排列的迪士尼角色列表,并且您需要找到米老鼠。 线性地需要很长时间。如果我们使用“将目录撕成两半的方法”,我们就可以直接找到 Jasmine,并且可以安全地丢弃列表的前半部分,并意识到 Mickey 不可能在那里。
线性地需要很长时间。如果我们使用“将目录撕成两半的方法”,我们就可以直接找到 Jasmine,并且可以安全地丢弃列表的前半部分,并意识到 Mickey 不可能在那里。  使用相同的原理,我们丢弃第二列。继续这个策略,我们只需几步就可以找到米奇。
使用相同的原理,我们丢弃第二列。继续这个策略,我们只需几步就可以找到米奇。  让我们找到数字 144。我们将列表分成两半,得到数字 13。我们评估我们要查找的数字是大于还是小于 13。13
让我们找到数字 144。我们将列表分成两半,得到数字 13。我们评估我们要查找的数字是大于还是小于 13。13  < 144,因此我们可以忽略 左边的所有内容13 和这个数字本身。现在我们的搜索列表看起来像这样:
< 144,因此我们可以忽略 左边的所有内容13 和这个数字本身。现在我们的搜索列表看起来像这样: 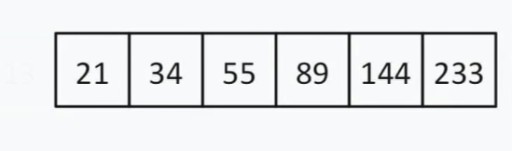 有偶数个元素,所以我们选择选择“中间”(靠近开头或结尾)的原则。假设我们选择了接近开始的策略。在这种情况下,我们的“中间”= 55。55
有偶数个元素,所以我们选择选择“中间”(靠近开头或结尾)的原则。假设我们选择了接近开始的策略。在这种情况下,我们的“中间”= 55。55  < 144。我们再次丢弃列表的左半部分。对我们来说幸运的是,下一个平均数字是 144。
< 144。我们再次丢弃列表的左半部分。对我们来说幸运的是,下一个平均数字是 144。  我们仅用三步就使用二分搜索在 13 元素数组中找到了 144。线性搜索最多需要 12 个步骤即可处理相同的情况。由于该算法每一步都会将数组中的元素数量减少一半,因此它将在渐近时间 O(log n) 内找到所需的元素,其中 n 是列表中的元素数量。也就是说,在我们的例子中,渐近时间 = O(log 13)(略多于三)。二分查找函数的伪代码:
我们仅用三步就使用二分搜索在 13 元素数组中找到了 144。线性搜索最多需要 12 个步骤即可处理相同的情况。由于该算法每一步都会将数组中的元素数量减少一半,因此它将在渐近时间 O(log n) 内找到所需的元素,其中 n 是列表中的元素数量。也就是说,在我们的例子中,渐近时间 = O(log 13)(略多于三)。二分查找函数的伪代码: 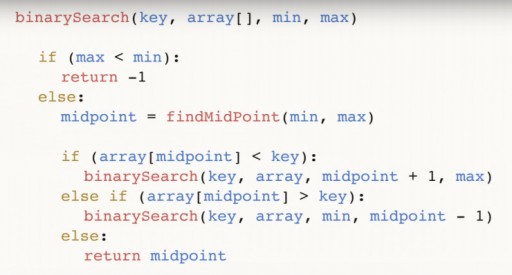 该函数接受 4 个参数作为输入:所需的键、数据数组 array[],所需的键位于其中,min 和 max 是指向数组中最大和最小数的指针,其中我们正在研究算法的这一步。对于我们的例子,最初给出了下图:
该函数接受 4 个参数作为输入:所需的键、数据数组 array[],所需的键位于其中,min 和 max 是指向数组中最大和最小数的指针,其中我们正在研究算法的这一步。对于我们的例子,最初给出了下图:  让我们进一步分析代码。中点是我们数组的中间。它取决于极值点并在极值点之间居中。找到中间值后,我们检查它是否小于我们的关键数字。
让我们进一步分析代码。中点是我们数组的中间。它取决于极值点并在极值点之间居中。找到中间值后,我们检查它是否小于我们的关键数字。  如果是这样,那么 key 也大于中间左边的任何数字,我们可以再次调用二元函数,只是现在我们的 min = midpoint + 1。如果结果是 key < midpoint,我们可以丢弃那个数字本身和所有的数字,就在他的右边。我们对数组进行二分搜索,从数字 min 到值 (中点 – 1)。
如果是这样,那么 key 也大于中间左边的任何数字,我们可以再次调用二元函数,只是现在我们的 min = midpoint + 1。如果结果是 key < midpoint,我们可以丢弃那个数字本身和所有的数字,就在他的右边。我们对数组进行二分搜索,从数字 min 到值 (中点 – 1)。  最后,第三个分支:如果中点的值既不大于也不小于key,则只能是所需的数字。在这种情况下,我们返回它并完成程序。
最后,第三个分支:如果中点的值既不大于也不小于key,则只能是所需的数字。在这种情况下,我们返回它并完成程序。  最后,可能会出现你要查找的数字根本不在数组中的情况。考虑到这种情况,我们执行以下检查:
最后,可能会出现你要查找的数字根本不在数组中的情况。考虑到这种情况,我们执行以下检查:  我们返回 (-1) 表示我们没有找到任何东西。您已经知道二分查找需要对数组进行排序。因此,如果我们有一个未排序的数组,需要在其中查找某个元素,我们有两个选择:
我们返回 (-1) 表示我们没有找到任何东西。您已经知道二分查找需要对数组进行排序。因此,如果我们有一个未排序的数组,需要在其中查找某个元素,我们有两个选择:
- 对列表进行排序并应用二分搜索
- 保持列表始终排序,同时添加和删除元素。
- 它是一棵树(模拟树结构的数据结构 - 它具有根和其他节点(叶子),通过“分支”或没有循环的边连接)
- 每个节点有 0、1 或 2 个子节点
- 左子树和右子树都是二叉搜索树。
- 任意节点X的左子树的所有节点的数据键值都小于节点X本身的数据键值。
- 任意节点X的右子树中的所有节点的数据键值都大于或等于节点X本身的数据键值。
 注意:“程序员”树的根与真正的根不同,它位于顶部。每个单元称为顶点,顶点之间通过边连接。树的根是单元号 13。顶点 3 的左子树在下图中以颜色突出显示:
注意:“程序员”树的根与真正的根不同,它位于顶部。每个单元称为顶点,顶点之间通过边连接。树的根是单元号 13。顶点 3 的左子树在下图中以颜色突出显示: 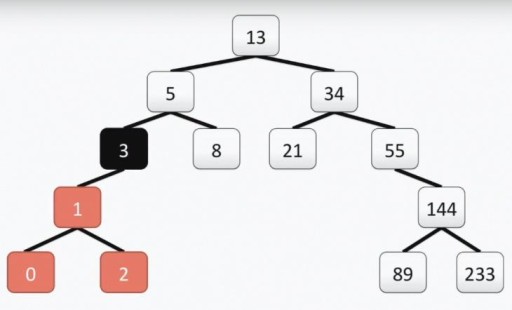 我们的树满足二叉树的所有要求。这意味着它的每个左子树只包含小于或等于顶点值的值,而右子树只包含大于或等于顶点值的值。左子树和右子树本身都是二叉子树。构造二叉树的方法并不是唯一的方法:在下图中,您可以看到同一组数字的另一种选择,并且在实践中可能有很多。
我们的树满足二叉树的所有要求。这意味着它的每个左子树只包含小于或等于顶点值的值,而右子树只包含大于或等于顶点值的值。左子树和右子树本身都是二叉子树。构造二叉树的方法并不是唯一的方法:在下图中,您可以看到同一组数字的另一种选择,并且在实践中可能有很多。  这种结构有助于进行搜索:我们每次从上到左、下移动来找到最小值。
这种结构有助于进行搜索:我们每次从上到左、下移动来找到最小值。 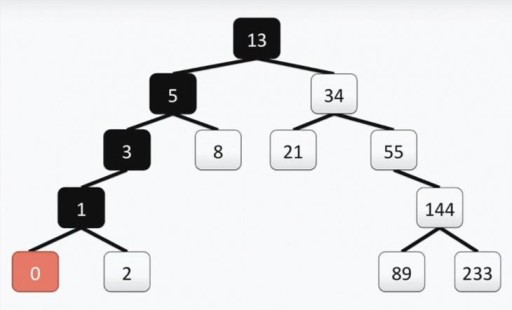 如果你需要找到最大的数字,我们从上到下,再到右边。找到一个不是最小值或最大值的数字也很简单。我们从根部向左或向右下降,具体取决于我们的顶点是比我们要寻找的顶点更大还是更小。因此,如果我们需要找到数字 89,我们会经过以下路径:
如果你需要找到最大的数字,我们从上到下,再到右边。找到一个不是最小值或最大值的数字也很简单。我们从根部向左或向右下降,具体取决于我们的顶点是比我们要寻找的顶点更大还是更小。因此,如果我们需要找到数字 89,我们会经过以下路径:  您也可以按排序顺序显示数字。例如,如果我们需要按升序显示所有数字,我们就取出左子树,并从最左边的顶点开始向上。在树上添加一些东西也很容易。最重要的是要记住结构。假设我们需要将值 7 添加到树中。让我们转到根并检查。数字 7 < 13,所以我们向左走。我们在那里看到 5,然后向右移动,因为 7 > 5。此外,由于 7 > 8 和 8 没有后代,因此我们从 8 向左构建一个分支,并将 7 附加到它。您还可以
您也可以按排序顺序显示数字。例如,如果我们需要按升序显示所有数字,我们就取出左子树,并从最左边的顶点开始向上。在树上添加一些东西也很容易。最重要的是要记住结构。假设我们需要将值 7 添加到树中。让我们转到根并检查。数字 7 < 13,所以我们向左走。我们在那里看到 5,然后向右移动,因为 7 > 5。此外,由于 7 > 8 和 8 没有后代,因此我们从 8 向左构建一个分支,并将 7 附加到它。您还可以 
 从树,但这有点复杂。我们需要考虑三种不同的删除场景。
从树,但这有点复杂。我们需要考虑三种不同的删除场景。
- 最简单的选择:我们需要删除没有子节点的顶点。例如,我们刚刚添加的数字 7。在这种情况下,我们只需沿着具有该数字的顶点的路径并将其删除即可。
- 一个顶点有一个子顶点。在这种情况下,您可以删除所需的顶点,但其后代必须连接到“祖父”,即其直接祖先生长的顶点。例如,我们需要从同一棵树中删除数字 3。在这种情况下,我们将其后代 1 与整个子树一起连接到 5。这很简单,因为 5 左侧的所有顶点都将是小于这个数字(并且小于远程三倍)。
![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 24]()
- 最困难的情况是被删除的顶点有两个子节点。现在我们需要做的第一件事是找到隐藏下一个较大值的顶点,我们需要交换它们,然后删除所需的顶点。请注意,下一个最高值顶点不能有两个子节点,那么它的左子节点将是下一个值的最佳候选。让我们从树中删除根节点 13。首先,我们寻找最接近 13 且大于 13 的数字。这是 21。交换 21 和 13 并删除 13。
![附加材料 CS50(第 3 周,第 7 课和第 8 课):渐近表示法、排序和搜索算法 - 25]()
![CS50 补充材料(第 3 周,第 7 课和第 8 课):渐近符号、排序和搜索算法 - 27]()



 所有数字都将简单地添加到前一个数字的右侧分支中。如果我们想找到一个数字,我们别无选择,只能顺着链条往下走。
所有数字都将简单地添加到前一个数字的右侧分支中。如果我们想找到一个数字,我们别无选择,只能顺着链条往下走。  它并不比线性搜索更好。还有其他更复杂的数据结构。但我们暂时不考虑它们。这么说吧,要解决从排序列表构造树的问题,您可以随机混合输入数据。
它并不比线性搜索更好。还有其他更复杂的数据结构。但我们暂时不考虑它们。这么说吧,要解决从排序列表构造树的问题,您可以随机混合输入数据。
排序算法
有一个数字数组。我们需要对其进行排序。为了简单起见,我们假设我们按升序(从最小到最大)对整数进行排序。有几种已知的方法可以完成这个过程。另外,您始终可以构思主题并提出对算法的修改。按选择排序
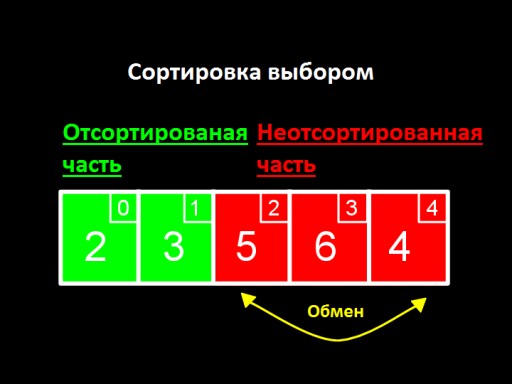 主要思想是将我们的列表分为两部分:已排序和未排序。在算法的每个步骤中,都会将一个新数字从未排序部分移动到已排序部分,依此类推,直到所有数字都位于已排序部分中。
主要思想是将我们的列表分为两部分:已排序和未排序。在算法的每个步骤中,都会将一个新数字从未排序部分移动到已排序部分,依此类推,直到所有数字都位于已排序部分中。
- 找到最小的未排序值。
- 我们将此值与第一个未排序的值交换,从而将其放置在已排序数组的末尾。
- 如果还有未排序的值,则返回步骤1。
 我们在数组的未排序部分(即在这一步 - 在整个数组中)找到最小数。这个数字是2。现在我们用未排序的第一个来改变它,并将它放在排序数组的末尾(在这一步中放在第一位)。在此步骤中,这是数组中的第一个数字,即 3。
我们在数组的未排序部分(即在这一步 - 在整个数组中)找到最小数。这个数字是2。现在我们用未排序的第一个来改变它,并将它放在排序数组的末尾(在这一步中放在第一位)。在此步骤中,这是数组中的第一个数字,即 3。  第二步。我们不看数字 2;它已经在已排序的子数组中了。我们开始寻找最小值,从第二个元素开始,这是5。我们确保3是未排序中的最小值,5是未排序中的第一个。我们交换它们并将 3 添加到已排序的子数组中。
第二步。我们不看数字 2;它已经在已排序的子数组中了。我们开始寻找最小值,从第二个元素开始,这是5。我们确保3是未排序中的最小值,5是未排序中的第一个。我们交换它们并将 3 添加到已排序的子数组中。  在第三步中,我们看到未排序子数组中的最小数字是4。我们将其更改为未排序子数组中的第一个数字 - 5。在第四步中,我们发现在
在第三步中,我们看到未排序子数组中的最小数字是4。我们将其更改为未排序子数组中的第一个数字 - 5。在第四步中,我们发现在  未排序数组中最小数字是5。我们将其从 6 更改并将其添加到已排序的子数组中。
未排序数组中最小数字是5。我们将其从 6 更改并将其添加到已排序的子数组中。 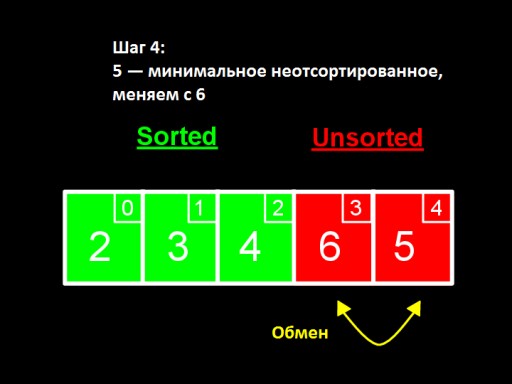 当未排序的数中只剩下一个数(最大的)时,这意味着整个数组已排序!
当未排序的数中只剩下一个数(最大的)时,这意味着整个数组已排序! 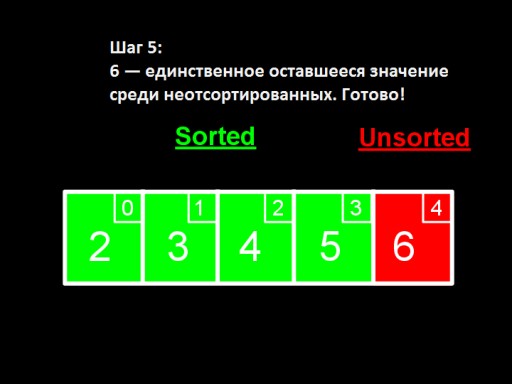 这就是数组实现在代码中的样子。尝试自己做一下。
这就是数组实现在代码中的样子。尝试自己做一下。  在最好和最坏的情况下,为了找到最小的未排序元素,我们必须将每个元素与未排序数组的每个元素进行比较,并且我们将在每次迭代时执行此操作。但我们不需要查看整个列表,而只需查看未排序的部分。这会改变算法的速度吗?第一步,对于 5 个元素的数组,我们进行 4 次比较,第二次比较 3 次,第三次比较 2 次。要获得比较次数,我们需要将所有这些数字相加。我们得到总和
在最好和最坏的情况下,为了找到最小的未排序元素,我们必须将每个元素与未排序数组的每个元素进行比较,并且我们将在每次迭代时执行此操作。但我们不需要查看整个列表,而只需查看未排序的部分。这会改变算法的速度吗?第一步,对于 5 个元素的数组,我们进行 4 次比较,第二次比较 3 次,第三次比较 2 次。要获得比较次数,我们需要将所有这些数字相加。我们得到总和  因此,算法在最好和最坏情况下的预期速度是 θ(n 2 )。不是最有效的算法!然而,出于教育目的和小数据集,它非常适用。
因此,算法在最好和最坏情况下的预期速度是 θ(n 2 )。不是最有效的算法!然而,出于教育目的和小数据集,它非常适用。
冒泡排序
冒泡排序算法是最简单的算法之一。我们遍历整个数组并比较 2 个相邻元素。如果它们的顺序错误,我们就交换它们。在第一遍中,最小的元素将出现(“浮动”)在末尾(如果我们按降序排序)。如果上一步中至少完成了一次交换,请重复第一步。让我们对数组进行排序。 第一步:遍历数组。该算法从前两个元素 8 和 6 开始,并检查它们的顺序是否正确。8 > 6,所以我们交换它们。接下来我们看第二个和第三个元素,现在是8和4。出于同样的原因,我们交换它们。我们第三次比较 8 和 2。总共,我们进行了三次交换 (8, 6)、(8, 4)、(8, 2)。值 8 “浮动”到列表末尾的正确位置。
第一步:遍历数组。该算法从前两个元素 8 和 6 开始,并检查它们的顺序是否正确。8 > 6,所以我们交换它们。接下来我们看第二个和第三个元素,现在是8和4。出于同样的原因,我们交换它们。我们第三次比较 8 和 2。总共,我们进行了三次交换 (8, 6)、(8, 4)、(8, 2)。值 8 “浮动”到列表末尾的正确位置。  步骤2:交换(6,4)和(6,2)。6 现在位于倒数第二个位置,无需将其与已排序的列表“尾部”进行比较。
步骤2:交换(6,4)和(6,2)。6 现在位于倒数第二个位置,无需将其与已排序的列表“尾部”进行比较。  第三步:交换4和2。四个“漂浮”到正确的位置。
第三步:交换4和2。四个“漂浮”到正确的位置。  第四步:我们遍历数组,但没有什么可以改变的。这表明数组已完全排序。
第四步:我们遍历数组,但没有什么可以改变的。这表明数组已完全排序。 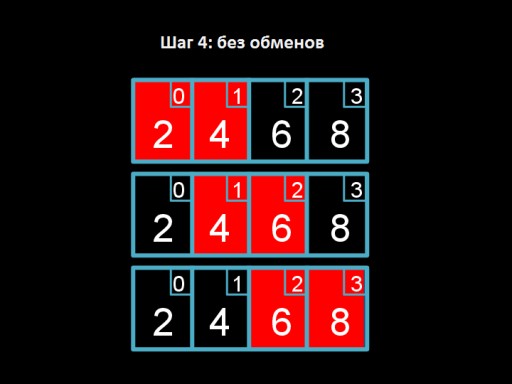 这是算法代码。尝试用 C 实现它! 冒泡排序在最坏的情况下(所有数字都是错误的)需要
这是算法代码。尝试用 C 实现它! 冒泡排序在最坏的情况下(所有数字都是错误的)需要 O(n 2 ) 时间,因为我们每次迭代需要执行 n 步,其中也有 n 步。事实上,与选择排序算法的情况一样,时间会稍微少一些(n 2 /2 – n/2),但这可以忽略不计。在最好的情况下(如果所有元素都已经就位),我们可以分 n 步完成,即 Ω(n),因为我们只需要遍历数组一次并确保所有元素都就位(即甚至 n-1 个元素)。
O(n 2 ) 时间,因为我们每次迭代需要执行 n 步,其中也有 n 步。事实上,与选择排序算法的情况一样,时间会稍微少一些(n 2 /2 – n/2),但这可以忽略不计。在最好的情况下(如果所有元素都已经就位),我们可以分 n 步完成,即 Ω(n),因为我们只需要遍历数组一次并确保所有元素都就位(即甚至 n-1 个元素)。
插入排序
该算法的主要思想是将我们的数组分为两部分,已排序和未排序。在算法的每一步,数字都会从未排序的部分移动到已排序的部分。 让我们使用下面的示例来了解插入排序的工作原理。在开始之前,所有元素都被视为未排序。
让我们使用下面的示例来了解插入排序的工作原理。在开始之前,所有元素都被视为未排序。  步骤 1:取出第一个未排序的值 (3) 并将其插入已排序的子数组中。在这一步,整个排序子数组,它的开始和结束将是这三个。
步骤 1:取出第一个未排序的值 (3) 并将其插入已排序的子数组中。在这一步,整个排序子数组,它的开始和结束将是这三个。  步骤 2:由于 3 > 5,我们将把 5 插入到 3 右侧的已排序子数组中。
步骤 2:由于 3 > 5,我们将把 5 插入到 3 右侧的已排序子数组中。  步骤 3:现在我们将数字 2 插入到已排序数组中。我们从右到左比较2的值来找到正确的位置。由于 2 < 5 和 2 < 3,我们已经到达排序子数组的开头。因此,我们必须将 2 插入到 3 的左侧。为此,请将 3 和 5 向右移动,以便有空间容纳 2,并将其插入到数组的开头。
步骤 3:现在我们将数字 2 插入到已排序数组中。我们从右到左比较2的值来找到正确的位置。由于 2 < 5 和 2 < 3,我们已经到达排序子数组的开头。因此,我们必须将 2 插入到 3 的左侧。为此,请将 3 和 5 向右移动,以便有空间容纳 2,并将其插入到数组的开头。  步骤 4.我们很幸运:6 > 5,所以我们可以在数字 5 之后插入该数字。 步骤
步骤 4.我们很幸运:6 > 5,所以我们可以在数字 5 之后插入该数字。 步骤  5. 4 < 6 且 4 < 5,但 4 > 3。因此,我们知道必须插入 4 3 的右侧。同样,我们被迫将 5 和 6 向右移动,为 4 创建间隙。
5. 4 < 6 且 4 < 5,但 4 > 3。因此,我们知道必须插入 4 3 的右侧。同样,我们被迫将 5 和 6 向右移动,为 4 创建间隙。  完成!广义算法:取出n的每个未排序元素,并从右到左将其与已排序子数组中的值进行比较,直到找到n的合适位置(即找到第一个小于n的数的那一刻) 。然后,我们将这个数字右侧的所有已排序元素向右移动,为 n 腾出空间,并将其插入那里,从而扩展数组的已排序部分。对于每个未排序的元素 n,您需要:
完成!广义算法:取出n的每个未排序元素,并从右到左将其与已排序子数组中的值进行比较,直到找到n的合适位置(即找到第一个小于n的数的那一刻) 。然后,我们将这个数字右侧的所有已排序元素向右移动,为 n 腾出空间,并将其插入那里,从而扩展数组的已排序部分。对于每个未排序的元素 n,您需要:
- 确定数组已排序部分中应插入 n 的位置
- 将已排序的元素向右移动以创建 n 的间隙
- 将 n 插入到数组已排序部分的结果间隙中。

算法的渐近速度
在最坏的情况下,我们将与第二个元素进行一次比较,与第三个元素进行两次比较,依此类推。因此我们的速度是 O(n 2 )。充其量,我们将使用已经排序的数组。我们从左到右构建的排序部分无需插入和移动元素,将花费 Ω(n) 时间。归并排序
该算法是递归的;它将一个大型排序问题分解为子任务,子任务的执行使其更接近于解决原始大问题。主要思想是将未排序的数组分成两部分,并对各个半部分进行递归排序。 假设我们有 n 个元素要排序。如果n < 2,我们完成排序,否则我们将数组的左右部分分别排序,然后将它们组合起来。让我们对数组进行排序,
假设我们有 n 个元素要排序。如果n < 2,我们完成排序,否则我们将数组的左右部分分别排序,然后将它们组合起来。让我们对数组进行排序,  将其分为两部分,继续划分,直到得到大小为 1 的子数组,这些子数组显然已排序。
将其分为两部分,继续划分,直到得到大小为 1 的子数组,这些子数组显然已排序。  使用简单的算法可以在 O(n) 时间内合并两个已排序的子数组:删除每个子数组开头的较小数字并将其插入到合并的数组中。重复直到所有元素都消失。
使用简单的算法可以在 O(n) 时间内合并两个已排序的子数组:删除每个子数组开头的较小数字并将其插入到合并的数组中。重复直到所有元素都消失。 
 对于所有情况,合并排序都需要 O(nlog n) 时间。当我们在每个递归级别将数组分成两半时,我们得到 log n。然后,合并子数组只需要 n 次比较。因此 O(nlog n)。归并排序的最佳和最差情况是相同的,算法的预期运行时间 = θ(nlog n)。该算法是所考虑的算法中最有效的。
对于所有情况,合并排序都需要 O(nlog n) 时间。当我们在每个递归级别将数组分成两半时,我们得到 log n。然后,合并子数组只需要 n 次比较。因此 O(nlog n)。归并排序的最佳和最差情况是相同的,算法的预期运行时间 = θ(nlog n)。该算法是所考虑的算法中最有效的。 

GO TO FULL VERSION