Medir la velocidad de un algoritmo en tiempo real (en segundos y minutos) no es fácil. Un programa puede funcionar más lento que otro no por su propia ineficiencia, sino por la lentitud del sistema operativo, la incompatibilidad con el hardware, la ocupación de la memoria del ordenador por otros procesos... Para medir la eficacia de los algoritmos se han inventado conceptos universales , independientemente del entorno en el que se ejecute el programa. La complejidad asintótica de un problema se mide utilizando la notación O grande. Sean f(x) y g(x) funciones definidas en una determinada vecindad de x0, y g no desaparece allí. Entonces f es “O” mayor que g para (x -> x0) si existe una constante C> 0 , que para todo x desde alguna vecindad del punto x0 la desigualdad se cumple. Ligeramente menos estricta : |f(x)| <= C |g(x)| f es “O” mayor que g si hay una constante C>0, que para todo x > x0 f(x) <= C*g(x)¡La definición formal! Esencialmente, determina el aumento asintótico en el tiempo de ejecución del programa cuando la cantidad de datos de entrada crece hacia el infinito. Por ejemplo, está comparando la clasificación de una matriz de 1000 elementos y 10 elementos, y necesita comprender cómo aumentará el tiempo de ejecución del programa. O necesita calcular la longitud de una cadena de caracteres yendo carácter por carácter y sumando 1 por cada carácter: c - 1 a - 2 t - 3 Su velocidad asintótica = O(n), donde n es el número de letras de la palabra. Si cuenta según este principio, el tiempo necesario para contar la línea completa es proporcional al número de caracteres. Contar el número de caracteres en una cadena de 20 caracteres lleva el doble de tiempo que contar el número de caracteres en una cadena de diez caracteres. Imagina que en la variable de longitud almacenaste un valor igual al número de caracteres de la cadena. Por ejemplo, longitud = 1000. Para obtener la longitud de una cadena, sólo necesita acceso a esta variable; ni siquiera tiene que mirar la cadena misma. Y no importa cómo cambiemos la longitud, siempre podremos acceder a esta variable. En este caso, velocidad asintótica = O(1). Cambiar los datos de entrada no cambia la velocidad de dicha tarea; la búsqueda se completa en un tiempo constante. En este caso, el programa es asintóticamente constante. Desventaja: desperdicia memoria de la computadora almacenando una variable adicional y tiempo adicional actualizando su valor. Si crees que el tiempo lineal es malo, te podemos asegurar que puede ser mucho peor. Por ejemplo, O(n 2 ). Esta notación significa que a medida que n crece, el tiempo necesario para iterar a través de elementos (u otra acción) aumentará cada vez más. Pero para n pequeño, los algoritmos con velocidad asintótica O(n 2 ) pueden funcionar más rápido que los algoritmos con velocidad asintótica O(n). Pero en algún momento la función cuadrática superará a la lineal, no hay forma de evitarlo. Otra complejidad asintótica es el tiempo logarítmico u O (log n). A medida que n aumenta, esta función aumenta muy lentamente. O(log n) es el tiempo de ejecución del clásico algoritmo de búsqueda binaria en una matriz ordenada (¿recuerda la guía telefónica rota de la conferencia?). Se divide el array en dos, luego se selecciona la mitad en la que se encuentra el elemento, y así, cada vez reduciendo el área de búsqueda a la mitad, buscamos el elemento. ¿Qué sucede si inmediatamente nos topamos con lo que estamos buscando, dividiendo nuestra matriz de datos por la mitad por primera vez? Existe un término para el mejor momento: Omega-grande o Ω(n). En el caso de búsqueda binaria = Ω(1) (busca en tiempo constante, independientemente del tamaño de la matriz). La búsqueda lineal se ejecuta en tiempo O(n) y Ω(1) si el elemento que se busca es el primero. Otro símbolo es theta (Θ(n)). Se utiliza cuando las mejores y peores opciones son las mismas. Esto es adecuado para un ejemplo en el que almacenamos la longitud de una cadena en una variable separada, por lo que para cualquier longitud es suficiente hacer referencia a esta variable. Para este algoritmo, los mejores y peores casos son Ω(1) y O(1), respectivamente. Esto significa que el algoritmo se ejecuta en el tiempo Θ(1).
búsqueda lineal
Cuando abres un navegador web, buscas una página, información, amigos en las redes sociales, estás haciendo una búsqueda, como cuando intentas encontrar el par de zapatos adecuado en una tienda. Probablemente hayas notado que el orden tiene un gran impacto en la forma de realizar búsquedas. Si tienes todas tus camisas en tu armario, suele ser más fácil encontrar la que necesitas entre ellas que entre las que están esparcidas sin sistema por la habitación. La búsqueda lineal es un método de búsqueda secuencial, uno por uno. Cuando revisa los resultados de búsqueda de Google de arriba a abajo, está utilizando una búsqueda lineal. Ejemplo . Digamos que tenemos una lista de números: 2 4 0 5 3 7 8 1 y necesitamos encontrar el 0. Lo vemos de inmediato, pero un programa de computadora no funciona de esa manera. Empieza al principio de la lista y ve el número 2. Luego comprueba, ¿2=0? No lo es, así que continúa y pasa al segundo personaje. Allí también le espera el fracaso y sólo en la tercera posición el algoritmo encuentra el número deseado. Pseudocódigo para búsqueda lineal: la función linearSearch recibe dos argumentos como entrada: la clave clave y la matriz matriz[]. La clave es el valor deseado, en el ejemplo anterior clave = 0. La matriz es una lista de números que mirará a través. Si no encontramos nada, la función devolverá -1 (una posición que no existe en la matriz). Si la búsqueda lineal encuentra el elemento deseado, la función devolverá la posición en la que se encuentra el elemento deseado en la matriz. Lo bueno de la búsqueda lineal es que funcionará para cualquier matriz, independientemente del orden de los elementos: igualmente recorreremos toda la matriz. Ésta es también su debilidad. Si necesita encontrar el número 198 en una matriz de 200 números ordenados, el bucle for pasará por 198 pasos. Probablemente ya hayas adivinado qué método funciona mejor para una matriz ordenada.
Búsqueda binaria y árboles.
Imagina que tienes una lista de personajes de Disney ordenados alfabéticamente y necesitas encontrar a Mickey Mouse. Linealmente llevaría mucho tiempo. Y si utilizamos el “método de dividir el directorio por la mitad”, llegamos directamente a Jasmine y podemos descartar con seguridad la primera mitad de la lista, al darnos cuenta de que Mickey no puede estar allí. Usando el mismo principio, descartamos la segunda columna. Siguiendo esta estrategia, encontraremos a Mickey en tan solo un par de pasos. Encontremos el número 144. Dividimos la lista por la mitad y llegamos al número 13. Evaluamos si el número que buscamos es mayor o menor que 13. 13 < 144, así podemos ignorar todo lo que está a la izquierda de 13 y este número en sí. Ahora nuestra lista de búsqueda se ve así: Hay un número par de elementos, por lo que elegimos el principio mediante el cual seleccionamos el "medio" (más cerca del principio o del final). Digamos que elegimos la estrategia de proximidad al principio. En este caso, nuestro "medio" = 55. 55 < 144. Descartamos nuevamente la mitad izquierda de la lista. Afortunadamente para nosotros, el siguiente número promedio es 144. Encontramos 144 en una matriz de 13 elementos mediante búsqueda binaria en solo tres pasos. Una búsqueda lineal manejaría la misma situación en hasta 12 pasos. Dado que este algoritmo reduce la cantidad de elementos en la matriz a la mitad en cada paso, encontrará el requerido en tiempo asintótico O (log n), donde n es la cantidad de elementos en la lista. Es decir, en nuestro caso, el tiempo asintótico = O(log 13) (esto es un poco más de tres). Pseudocódigo de la función de búsqueda binaria: La función toma 4 argumentos como entrada: la clave deseada, la matriz de datos [], en la que se encuentra el deseado, min y max son punteros al número máximo y mínimo en la matriz, que Estamos analizando este paso del algoritmo. Para nuestro ejemplo, inicialmente se proporcionó la siguiente imagen: Analicemos el código más a fondo. El punto medio es nuestro punto medio de la matriz. Depende de los puntos extremos y está centrado entre ellos. Una vez que hayamos encontrado el medio, comprobamos si es menor que nuestro número clave. Si es así, entonces la clave también es mayor que cualquiera de los números a la izquierda del medio, y podemos llamar a la función binaria nuevamente, solo que ahora nuestro min = punto medio + 1. Si resulta que la clave <punto medio, podemos descartar ese número en sí y todos los números, a su derecha. Y llamamos a una búsqueda binaria a través de la matriz desde el número mínimo hasta el valor (punto medio – 1). Finalmente, la tercera rama: si el valor en el punto medio no es mayor ni menor que clave, no le queda más remedio que ser el número deseado. En este caso lo devolvemos y finalizamos el programa. Finalmente, puede suceder que el número que busca no esté en absoluto en la matriz. Para tener en cuenta este caso realizamos la siguiente comprobación: Y volvemos (-1) para indicar que no encontramos nada. Ya sabes que la búsqueda binaria requiere que la matriz esté ordenada. Así, si tenemos un array sin ordenar en el que necesitamos encontrar un determinado elemento, tenemos dos opciones:
Ordena la lista y aplica la búsqueda binaria.
Mantenga la lista siempre ordenada mientras agrega y elimina elementos simultáneamente.
Una forma de mantener las listas ordenadas es utilizar un árbol de búsqueda binario. Un árbol de búsqueda binario es una estructura de datos que cumple con los siguientes requisitos:
Es un árbol (una estructura de datos que emula una estructura de árbol; tiene una raíz y otros nodos (hojas) conectados por “ramas” o aristas sin ciclos)
Cada nodo tiene 0, 1 o 2 hijos.
Tanto el subárbol izquierdo como el derecho son árboles de búsqueda binarios.
Todos los nodos del subárbol izquierdo de un nodo X arbitrario tienen valores de clave de datos menores que el valor de la clave de datos del propio nodo X.
Todos los nodos en el subárbol derecho de un nodo X arbitrario tienen valores de clave de datos mayores o iguales al valor de la clave de datos del propio nodo X.
Atención: la raíz del árbol “programador”, a diferencia del real, está en la parte superior. Cada celda se llama vértice y los vértices están conectados por aristas. La raíz del árbol es la celda número 13. El subárbol izquierdo del vértice 3 está resaltado en color en la siguiente imagen: Nuestro árbol cumple con todos los requisitos para árboles binarios. Esto significa que cada uno de sus subárboles izquierdos contiene solo valores menores o iguales al valor del vértice, mientras que el subárbol derecho contiene solo valores mayores o iguales al valor del vértice. Tanto el subárbol izquierdo como el derecho son en sí mismos subárboles binarios. El método para construir un árbol binario no es el único: a continuación en la imagen ves otra opción para el mismo conjunto de números, y en la práctica puede haber muchos. Esta estructura ayuda a realizar la búsqueda: encontramos el valor mínimo moviéndonos de arriba a la izquierda y hacia abajo cada vez. Si necesitas encontrar el número máximo, vamos de arriba hacia abajo y hacia la derecha. Encontrar un número que no sea el mínimo ni el máximo también es bastante sencillo. Descendemos desde la raíz hacia la izquierda o hacia la derecha, según si nuestro vértice es mayor o menor que el que buscamos. Entonces, si necesitamos encontrar el número 89, seguimos este camino: También puedes mostrar los números en orden de clasificación. Por ejemplo, si necesitamos mostrar todos los números en orden ascendente, tomamos el subárbol izquierdo y, comenzando desde el vértice más a la izquierda, subimos. Agregar algo al árbol también es fácil. Lo principal a recordar es la estructura. Digamos que necesitamos agregar el valor 7 al árbol. Vayamos a la raíz y verifiquemos. El número 7 <13, así que vamos a la izquierda. Vemos 5 allí y vamos hacia la derecha, ya que 7 > 5. Además, como 7 > 8 y 8 no tiene descendientes, construimos una rama desde 8 hacia la izquierda y le adjuntamos 7. También puedes eliminar los vértices de el árbol, pero esto es algo más complicado. Hay tres escenarios de eliminación diferentes que debemos considerar.
La opción más sencilla: necesitamos eliminar un vértice que no tenga hijos. Por ejemplo, el número 7 que acabamos de agregar. En este caso, simplemente seguimos el camino hasta el vértice con este número y lo eliminamos.
Un vértice tiene un vértice hijo. En este caso, se puede eliminar el vértice deseado, pero su descendiente debe estar conectado al “abuelo”, es decir, el vértice a partir del cual creció su ancestro inmediato. Por ejemplo, del mismo árbol necesitamos eliminar el número 3. En este caso, unimos su descendiente, uno, junto con todo el subárbol al 5. Esto se hace de forma sencilla, ya que todos los vértices a la izquierda de 5 serán menos que este número (y menos que el triple remoto).
El caso más difícil es cuando el vértice que se elimina tiene dos hijos. Ahora lo primero que debemos hacer es encontrar el vértice en el que está oculto el siguiente valor mayor, debemos intercambiarlos y luego eliminar el vértice deseado. Tenga en cuenta que el siguiente vértice con el valor más alto no puede tener dos hijos, entonces su hijo izquierdo será el mejor candidato para el siguiente valor. Eliminemos de nuestro árbol el nodo raíz 13. Primero buscamos el número más cercano a 13, que sea mayor que él. Este es 21. Intercambia 21 y 13 y elimina 13.
Hay diferentes formas de construir árboles binarios, algunas buenas y otras no tan buenas. ¿Qué sucede si intentamos construir un árbol binario a partir de una lista ordenada? Todos los números simplemente se sumarán a la rama derecha del anterior. Si queremos encontrar un número, no nos quedará más remedio que simplemente seguir la cadena hacia abajo. No es mejor que la búsqueda lineal. Hay otras estructuras de datos que son más complejas. Pero no los consideraremos por ahora. Digamos que para resolver el problema de construir un árbol a partir de una lista ordenada, puedes mezclar aleatoriamente los datos de entrada.
Algoritmos de clasificación
Hay una variedad de números. Necesitamos ordenarlo. Para simplificar, asumiremos que estamos ordenando los números enteros en orden ascendente (de menor a mayor). Hay varias formas conocidas de realizar este proceso. Además, siempre puedes imaginar el tema y proponer una modificación del algoritmo.
Ordenar por selección
La idea principal es dividir nuestra lista en dos partes, ordenada y sin clasificar. En cada paso del algoritmo, se mueve un nuevo número de la parte no ordenada a la parte ordenada, y así sucesivamente hasta que todos los números estén en la parte ordenada.
Encuentre el valor mínimo sin clasificar.
Intercambiamos este valor con el primer valor sin ordenar, colocándolo así al final de la matriz ordenada.
Si quedan valores sin ordenar, regrese al paso 1.
En el primer paso, todos los valores están sin ordenar. Llamemos a la parte sin clasificar Sin clasificar y a la parte ordenada Ordenada (estas son solo palabras en inglés, y hacemos esto solo porque Ordenada es mucho más corta que “Parte ordenada” y se verá mejor en las imágenes). Encontramos el número mínimo en la parte no ordenada de la matriz (es decir, en este paso, en toda la matriz). Este número es 2. Ahora lo cambiamos por el primero entre los no ordenados y lo colocamos al final de la matriz ordenada (en este paso, en primer lugar). En este paso, este es el primer número de la matriz, es decir, 3. Paso dos. No miramos el número 2; ya está en el subconjunto ordenado. Empezamos a buscar el mínimo, partiendo del segundo elemento, este es 5. Nos aseguramos de que 3 sea el mínimo entre los sin clasificar, 5 sea el primero entre los sin clasificar. Los intercambiamos y agregamos 3 al subarreglo ordenado. En el tercer paso , vemos que el número más pequeño en el subarreglo sin ordenar es 4. Lo cambiamos con el primer número entre los sin ordenar: 5. En el cuarto paso, encontramos que en el arreglo sin ordenar el número más pequeño es 5. Lo cambiamos de 6 y lo agregamos al subarreglo ordenado. Cuando solo queda un número entre los no ordenados (el más grande), ¡esto significa que toda la matriz está ordenada! Así es como se ve la implementación de la matriz en el código. Intenta hacerlo tú mismo. Tanto en el mejor como en el peor de los casos, para encontrar el elemento mínimo sin clasificar, debemos comparar cada elemento con cada elemento de la matriz sin clasificar, y haremos esto en cada iteración. Pero no necesitamos ver la lista completa, sino sólo la parte sin ordenar. ¿Esto cambia la velocidad del algoritmo? En el primer paso, para una matriz de 5 elementos, hacemos 4 comparaciones, en el segundo - 3, en el tercero - 2. Para obtener el número de comparaciones, debemos sumar todos estos números. Obtenemos la suma. Por tanto, la velocidad esperada del algoritmo en el mejor y peor caso es Θ(n 2 ). ¡No es el algoritmo más eficiente! Sin embargo, para fines educativos y para conjuntos de datos pequeños es bastante aplicable.
Ordenamiento de burbuja
El algoritmo de clasificación de burbujas es uno de los más simples. Recorremos toda la matriz y comparamos 2 elementos vecinos. Si están en el orden incorrecto, los intercambiamos. En la primera pasada, el elemento más pequeño aparecerá (“flotante”) al final (si ordenamos en orden descendente). Repita el primer paso si se completó al menos un intercambio en el paso anterior. Ordenemos la matriz. Paso 1: revisa la matriz. El algoritmo comienza con los dos primeros elementos, 8 y 6, y comprueba si están en el orden correcto. 8 > 6, entonces los intercambiamos. A continuación miramos el segundo y tercer elemento, ahora son 8 y 4. Por las mismas razones, los intercambiamos. Por tercera vez comparamos 8 y 2. En total, hacemos tres intercambios (8, 6), (8, 4), (8, 2). El valor 8 "flotó" hasta el final de la lista en la posición correcta. Paso 2: intercambie (6,4) y (6,2). 6 se encuentra ahora en la penúltima posición y no es necesario compararlo con la “cola” ya ordenada de la lista. Paso 3: intercambie 4 y 2. El cuatro “flota” al lugar que le corresponde. Paso 4: recorremos el array, pero no tenemos nada que cambiar. Esto indica que la matriz está completamente ordenada. Y este es el código del algoritmo. ¡Intenta implementarlo en C! La clasificación de burbujas toma O(n 2 ) tiempo en el peor de los casos (todos los números son incorrectos), ya que necesitamos tomar n pasos en cada iteración, de los cuales también hay n. De hecho, como en el caso del algoritmo de clasificación por selección, el tiempo será ligeramente menor (n 2 /2 – n/2), pero esto puede despreciarse. En el mejor de los casos (si todos los elementos ya están en su lugar), podemos hacerlo en n pasos, es decir Ω(n), ya que solo necesitaremos iterar a través de la matriz una vez y asegurarnos de que todos los elementos estén en su lugar (es decir, incluso n-1 elementos).
Tipo de inserción
La idea principal de este algoritmo es dividir nuestra matriz en dos partes, ordenada y sin clasificar. En cada paso del algoritmo, el número pasa de la parte no ordenada a la parte ordenada. Veamos cómo funciona la ordenación por inserción usando el siguiente ejemplo. Antes de comenzar, todos los elementos se consideran desordenados. Paso 1: tome el primer valor sin ordenar (3) e insértelo en el subarreglo ordenado. En este paso, todo el subconjunto ordenado, su principio y su final, serán estos tres. Paso 2: Como 3 > 5, insertaremos 5 en el subarreglo ordenado a la derecha de 3. Paso 3: Ahora trabajamos para insertar el número 2 en nuestro arreglo ordenado. Comparamos 2 con valores de derecha a izquierda para encontrar la posición correcta. Desde 2 <5 y 2 <3 y hemos llegado al comienzo del subarreglo ordenado. Por lo tanto, debemos insertar 2 a la izquierda de 3. Para ello, mueve 3 y 5 hacia la derecha para que quede espacio para el 2 e insértalo al principio del array. Paso 4. Tenemos suerte: 6 > 5, entonces podemos insertar ese número justo después del número 5. Paso 5. 4 < 6 y 4 < 5, pero 4 > 3. Por lo tanto, sabemos que se debe insertar 4 para a la derecha de 3. Nuevamente, nos vemos obligados a mover 5 y 6 hacia la derecha para crear un espacio para 4. ¡ Listo! Algoritmo generalizado: tome cada elemento no ordenado de n y compárelo con los valores en el subarreglo ordenado de derecha a izquierda hasta que encontremos una posición adecuada para n (es decir, el momento en que encontramos el primer número que es menor que n) . Luego, desplazamos todos los elementos ordenados que están a la derecha de este número hacia la derecha para dejar espacio para nuestra n, y la insertamos allí, expandiendo así la parte ordenada de la matriz. Para cada elemento n sin clasificar necesitas:
Determine la ubicación en la parte ordenada de la matriz donde se debe insertar n
Mueva los elementos ordenados hacia la derecha para crear un espacio para n
Inserte n en el espacio resultante en la parte ordenada de la matriz.
¡Y aquí está el código! Recomendamos escribir su propia versión del programa de clasificación.
Velocidad asintótica del algoritmo.
En el peor de los casos haremos una comparación con el segundo elemento, dos comparaciones con el tercero, y así sucesivamente. Por tanto, nuestra velocidad es O(n 2 ). En el mejor de los casos, trabajaremos con una matriz ya ordenada. La parte ordenada, que construimos de izquierda a derecha sin inserciones ni movimientos de elementos, llevará un tiempo Ω(n).
Combinar ordenar
Este algoritmo es recursivo; divide un gran problema de clasificación en subtareas, cuya ejecución lo acerca a la resolución del gran problema original. La idea principal es dividir una matriz sin clasificar en dos partes y ordenar las mitades individuales de forma recursiva. Digamos que tenemos n elementos para ordenar. Si n <2, terminamos de ordenar; de lo contrario, ordenamos las partes izquierda y derecha de la matriz por separado y luego las combinamos. Ordenemos el arreglo, dividámoslo en dos partes y continuamos dividiéndolo hasta obtener subarreglos de tamaño 1, que obviamente están ordenados. Se pueden fusionar dos subarreglos ordenados en tiempo O(n) usando un algoritmo simple: elimine el número más pequeño al comienzo de cada subarreglo e insértelo en el arreglo fusionado. Repita hasta que se acaben todos los elementos. La clasificación por combinación requiere un tiempo O (nlog n) para todos los casos. Mientras dividimos las matrices en mitades en cada nivel de recursividad obtenemos log n. Entonces, fusionar los subarreglos requiere solo n comparaciones. Por lo tanto O(nlog n). Los mejores y peores casos para la ordenación por fusión son los mismos: el tiempo de ejecución esperado del algoritmo = Θ(nlog n). Este algoritmo es el más eficaz entre los considerados.
 Pero en algún momento la función cuadrática superará a la lineal, no hay forma de evitarlo. Otra complejidad asintótica es el tiempo logarítmico u O (log n). A medida que n aumenta, esta función aumenta muy lentamente. O(log n) es el tiempo de ejecución del clásico algoritmo de búsqueda binaria en una matriz ordenada (¿recuerda la guía telefónica rota de la conferencia?). Se divide el array en dos, luego se selecciona la mitad en la que se encuentra el elemento, y así, cada vez reduciendo el área de búsqueda a la mitad, buscamos el elemento.
Pero en algún momento la función cuadrática superará a la lineal, no hay forma de evitarlo. Otra complejidad asintótica es el tiempo logarítmico u O (log n). A medida que n aumenta, esta función aumenta muy lentamente. O(log n) es el tiempo de ejecución del clásico algoritmo de búsqueda binaria en una matriz ordenada (¿recuerda la guía telefónica rota de la conferencia?). Se divide el array en dos, luego se selecciona la mitad en la que se encuentra el elemento, y así, cada vez reduciendo el área de búsqueda a la mitad, buscamos el elemento.  ¿Qué sucede si inmediatamente nos topamos con lo que estamos buscando, dividiendo nuestra matriz de datos por la mitad por primera vez? Existe un término para el mejor momento: Omega-grande o Ω(n). En el caso de búsqueda binaria = Ω(1) (busca en tiempo constante, independientemente del tamaño de la matriz). La búsqueda lineal se ejecuta en tiempo O(n) y Ω(1) si el elemento que se busca es el primero. Otro símbolo es theta (Θ(n)). Se utiliza cuando las mejores y peores opciones son las mismas. Esto es adecuado para un ejemplo en el que almacenamos la longitud de una cadena en una variable separada, por lo que para cualquier longitud es suficiente hacer referencia a esta variable. Para este algoritmo, los mejores y peores casos son Ω(1) y O(1), respectivamente. Esto significa que el algoritmo se ejecuta en el tiempo Θ(1).
¿Qué sucede si inmediatamente nos topamos con lo que estamos buscando, dividiendo nuestra matriz de datos por la mitad por primera vez? Existe un término para el mejor momento: Omega-grande o Ω(n). En el caso de búsqueda binaria = Ω(1) (busca en tiempo constante, independientemente del tamaño de la matriz). La búsqueda lineal se ejecuta en tiempo O(n) y Ω(1) si el elemento que se busca es el primero. Otro símbolo es theta (Θ(n)). Se utiliza cuando las mejores y peores opciones son las mismas. Esto es adecuado para un ejemplo en el que almacenamos la longitud de una cadena en una variable separada, por lo que para cualquier longitud es suficiente hacer referencia a esta variable. Para este algoritmo, los mejores y peores casos son Ω(1) y O(1), respectivamente. Esto significa que el algoritmo se ejecuta en el tiempo Θ(1).
 función linearSearch recibe dos argumentos como entrada: la clave clave y la matriz matriz[]. La clave es el valor deseado, en el ejemplo anterior clave = 0. La matriz es una lista de números que mirará a través. Si no encontramos nada, la función devolverá -1 (una posición que no existe en la matriz). Si la búsqueda lineal encuentra el elemento deseado, la función devolverá la posición en la que se encuentra el elemento deseado en la matriz. Lo bueno de la búsqueda lineal es que funcionará para cualquier matriz, independientemente del orden de los elementos: igualmente recorreremos toda la matriz. Ésta es también su debilidad. Si necesita encontrar el número 198 en una matriz de 200 números ordenados, el bucle for pasará por 198 pasos.
función linearSearch recibe dos argumentos como entrada: la clave clave y la matriz matriz[]. La clave es el valor deseado, en el ejemplo anterior clave = 0. La matriz es una lista de números que mirará a través. Si no encontramos nada, la función devolverá -1 (una posición que no existe en la matriz). Si la búsqueda lineal encuentra el elemento deseado, la función devolverá la posición en la que se encuentra el elemento deseado en la matriz. Lo bueno de la búsqueda lineal es que funcionará para cualquier matriz, independientemente del orden de los elementos: igualmente recorreremos toda la matriz. Ésta es también su debilidad. Si necesita encontrar el número 198 en una matriz de 200 números ordenados, el bucle for pasará por 198 pasos.  Probablemente ya hayas adivinado qué método funciona mejor para una matriz ordenada.
Probablemente ya hayas adivinado qué método funciona mejor para una matriz ordenada.

 Linealmente llevaría mucho tiempo. Y si utilizamos el “método de dividir el directorio por la mitad”, llegamos directamente a Jasmine y podemos descartar con seguridad la primera mitad de la lista, al darnos cuenta de que Mickey no puede estar allí.
Linealmente llevaría mucho tiempo. Y si utilizamos el “método de dividir el directorio por la mitad”, llegamos directamente a Jasmine y podemos descartar con seguridad la primera mitad de la lista, al darnos cuenta de que Mickey no puede estar allí.  Usando el mismo principio, descartamos la segunda columna. Siguiendo esta estrategia, encontraremos a Mickey en tan solo un par de pasos.
Usando el mismo principio, descartamos la segunda columna. Siguiendo esta estrategia, encontraremos a Mickey en tan solo un par de pasos.  Encontremos el número 144. Dividimos la lista por la mitad y llegamos al número 13. Evaluamos si el número que buscamos es mayor o menor que 13. 13
Encontremos el número 144. Dividimos la lista por la mitad y llegamos al número 13. Evaluamos si el número que buscamos es mayor o menor que 13. 13  < 144, así podemos ignorar todo lo que está a la izquierda de 13 y este número en sí. Ahora nuestra lista de búsqueda se ve así:
< 144, así podemos ignorar todo lo que está a la izquierda de 13 y este número en sí. Ahora nuestra lista de búsqueda se ve así: 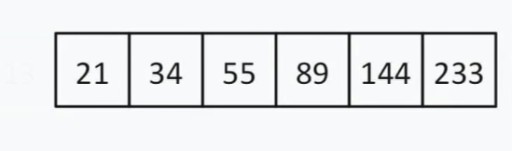 Hay un número par de elementos, por lo que elegimos el principio mediante el cual seleccionamos el "medio" (más cerca del principio o del final). Digamos que elegimos la estrategia de proximidad al principio. En este caso, nuestro "medio" = 55.
Hay un número par de elementos, por lo que elegimos el principio mediante el cual seleccionamos el "medio" (más cerca del principio o del final). Digamos que elegimos la estrategia de proximidad al principio. En este caso, nuestro "medio" = 55.  55 < 144. Descartamos nuevamente la mitad izquierda de la lista. Afortunadamente para nosotros, el siguiente número promedio es 144.
55 < 144. Descartamos nuevamente la mitad izquierda de la lista. Afortunadamente para nosotros, el siguiente número promedio es 144.  Encontramos 144 en una matriz de 13 elementos mediante búsqueda binaria en solo tres pasos. Una búsqueda lineal manejaría la misma situación en hasta 12 pasos. Dado que este algoritmo reduce la cantidad de elementos en la matriz a la mitad en cada paso, encontrará el requerido en tiempo asintótico O (log n), donde n es la cantidad de elementos en la lista. Es decir, en nuestro caso, el tiempo asintótico = O(log 13) (esto es un poco más de tres). Pseudocódigo de la función de búsqueda binaria:
Encontramos 144 en una matriz de 13 elementos mediante búsqueda binaria en solo tres pasos. Una búsqueda lineal manejaría la misma situación en hasta 12 pasos. Dado que este algoritmo reduce la cantidad de elementos en la matriz a la mitad en cada paso, encontrará el requerido en tiempo asintótico O (log n), donde n es la cantidad de elementos en la lista. Es decir, en nuestro caso, el tiempo asintótico = O(log 13) (esto es un poco más de tres). Pseudocódigo de la función de búsqueda binaria: 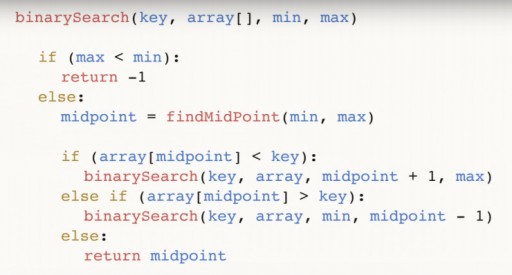 La función toma 4 argumentos como entrada: la clave deseada, la matriz de datos [], en la que se encuentra el deseado, min y max son punteros al número máximo y mínimo en la matriz, que Estamos analizando este paso del algoritmo. Para nuestro ejemplo, inicialmente se proporcionó la siguiente imagen:
La función toma 4 argumentos como entrada: la clave deseada, la matriz de datos [], en la que se encuentra el deseado, min y max son punteros al número máximo y mínimo en la matriz, que Estamos analizando este paso del algoritmo. Para nuestro ejemplo, inicialmente se proporcionó la siguiente imagen:  Analicemos el código más a fondo. El punto medio es nuestro punto medio de la matriz. Depende de los puntos extremos y está centrado entre ellos. Una vez que hayamos encontrado el medio, comprobamos si es menor que nuestro número clave.
Analicemos el código más a fondo. El punto medio es nuestro punto medio de la matriz. Depende de los puntos extremos y está centrado entre ellos. Una vez que hayamos encontrado el medio, comprobamos si es menor que nuestro número clave.  Si es así, entonces la clave también es mayor que cualquiera de los números a la izquierda del medio, y podemos llamar a la función binaria nuevamente, solo que ahora nuestro min = punto medio + 1. Si resulta que la clave <punto medio, podemos descartar ese número en sí y todos los números, a su derecha. Y llamamos a una búsqueda binaria a través de la matriz desde el número mínimo hasta el valor (punto medio – 1).
Si es así, entonces la clave también es mayor que cualquiera de los números a la izquierda del medio, y podemos llamar a la función binaria nuevamente, solo que ahora nuestro min = punto medio + 1. Si resulta que la clave <punto medio, podemos descartar ese número en sí y todos los números, a su derecha. Y llamamos a una búsqueda binaria a través de la matriz desde el número mínimo hasta el valor (punto medio – 1).  Finalmente, la tercera rama: si el valor en el punto medio no es mayor ni menor que clave, no le queda más remedio que ser el número deseado. En este caso lo devolvemos y finalizamos el programa.
Finalmente, la tercera rama: si el valor en el punto medio no es mayor ni menor que clave, no le queda más remedio que ser el número deseado. En este caso lo devolvemos y finalizamos el programa.  Finalmente, puede suceder que el número que busca no esté en absoluto en la matriz. Para tener en cuenta este caso realizamos la siguiente comprobación:
Finalmente, puede suceder que el número que busca no esté en absoluto en la matriz. Para tener en cuenta este caso realizamos la siguiente comprobación:  Y volvemos (-1) para indicar que no encontramos nada. Ya sabes que la búsqueda binaria requiere que la matriz esté ordenada. Así, si tenemos un array sin ordenar en el que necesitamos encontrar un determinado elemento, tenemos dos opciones:
Y volvemos (-1) para indicar que no encontramos nada. Ya sabes que la búsqueda binaria requiere que la matriz esté ordenada. Así, si tenemos un array sin ordenar en el que necesitamos encontrar un determinado elemento, tenemos dos opciones:
 Atención: la raíz del árbol “programador”, a diferencia del real, está en la parte superior. Cada celda se llama vértice y los vértices están conectados por aristas. La raíz del árbol es la celda número 13. El subárbol izquierdo del vértice 3 está resaltado en color en la siguiente imagen:
Atención: la raíz del árbol “programador”, a diferencia del real, está en la parte superior. Cada celda se llama vértice y los vértices están conectados por aristas. La raíz del árbol es la celda número 13. El subárbol izquierdo del vértice 3 está resaltado en color en la siguiente imagen: 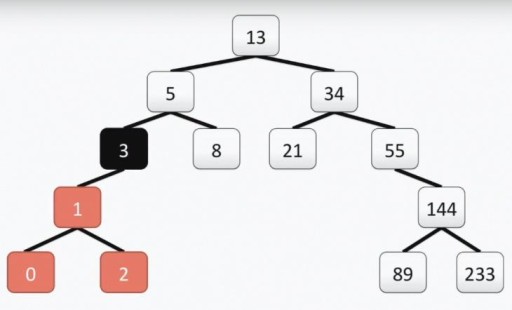 Nuestro árbol cumple con todos los requisitos para árboles binarios. Esto significa que cada uno de sus subárboles izquierdos contiene solo valores menores o iguales al valor del vértice, mientras que el subárbol derecho contiene solo valores mayores o iguales al valor del vértice. Tanto el subárbol izquierdo como el derecho son en sí mismos subárboles binarios. El método para construir un árbol binario no es el único: a continuación en la imagen ves otra opción para el mismo conjunto de números, y en la práctica puede haber muchos.
Nuestro árbol cumple con todos los requisitos para árboles binarios. Esto significa que cada uno de sus subárboles izquierdos contiene solo valores menores o iguales al valor del vértice, mientras que el subárbol derecho contiene solo valores mayores o iguales al valor del vértice. Tanto el subárbol izquierdo como el derecho son en sí mismos subárboles binarios. El método para construir un árbol binario no es el único: a continuación en la imagen ves otra opción para el mismo conjunto de números, y en la práctica puede haber muchos.  Esta estructura ayuda a realizar la búsqueda: encontramos el valor mínimo moviéndonos de arriba a la izquierda y hacia abajo cada vez.
Esta estructura ayuda a realizar la búsqueda: encontramos el valor mínimo moviéndonos de arriba a la izquierda y hacia abajo cada vez. 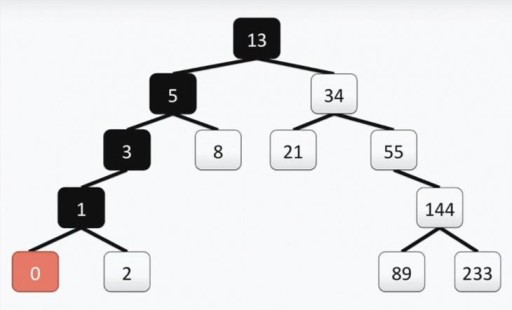 Si necesitas encontrar el número máximo, vamos de arriba hacia abajo y hacia la derecha. Encontrar un número que no sea el mínimo ni el máximo también es bastante sencillo. Descendemos desde la raíz hacia la izquierda o hacia la derecha, según si nuestro vértice es mayor o menor que el que buscamos. Entonces, si necesitamos encontrar el número 89, seguimos este camino:
Si necesitas encontrar el número máximo, vamos de arriba hacia abajo y hacia la derecha. Encontrar un número que no sea el mínimo ni el máximo también es bastante sencillo. Descendemos desde la raíz hacia la izquierda o hacia la derecha, según si nuestro vértice es mayor o menor que el que buscamos. Entonces, si necesitamos encontrar el número 89, seguimos este camino:  También puedes mostrar los números en orden de clasificación. Por ejemplo, si necesitamos mostrar todos los números en orden ascendente, tomamos el subárbol izquierdo y, comenzando desde el vértice más a la izquierda, subimos. Agregar algo al árbol también es fácil. Lo principal a recordar es la estructura. Digamos que necesitamos agregar el valor 7 al árbol. Vayamos a la raíz y verifiquemos. El número 7 <13, así que vamos a la izquierda. Vemos 5 allí y vamos hacia la derecha, ya que 7 > 5. Además, como 7 > 8 y 8 no tiene descendientes, construimos una rama desde 8 hacia la izquierda y le adjuntamos 7. También puedes eliminar los vértices
También puedes mostrar los números en orden de clasificación. Por ejemplo, si necesitamos mostrar todos los números en orden ascendente, tomamos el subárbol izquierdo y, comenzando desde el vértice más a la izquierda, subimos. Agregar algo al árbol también es fácil. Lo principal a recordar es la estructura. Digamos que necesitamos agregar el valor 7 al árbol. Vayamos a la raíz y verifiquemos. El número 7 <13, así que vamos a la izquierda. Vemos 5 allí y vamos hacia la derecha, ya que 7 > 5. Además, como 7 > 8 y 8 no tiene descendientes, construimos una rama desde 8 hacia la izquierda y le adjuntamos 7. También puedes eliminar los vértices 
 de el árbol, pero esto es algo más complicado. Hay tres escenarios de eliminación diferentes que debemos considerar.
de el árbol, pero esto es algo más complicado. Hay tres escenarios de eliminación diferentes que debemos considerar.



 Todos los números simplemente se sumarán a la rama derecha del anterior. Si queremos encontrar un número, no nos quedará más remedio que simplemente seguir la cadena hacia abajo.
Todos los números simplemente se sumarán a la rama derecha del anterior. Si queremos encontrar un número, no nos quedará más remedio que simplemente seguir la cadena hacia abajo.  No es mejor que la búsqueda lineal. Hay otras estructuras de datos que son más complejas. Pero no los consideraremos por ahora. Digamos que para resolver el problema de construir un árbol a partir de una lista ordenada, puedes mezclar aleatoriamente los datos de entrada.
No es mejor que la búsqueda lineal. Hay otras estructuras de datos que son más complejas. Pero no los consideraremos por ahora. Digamos que para resolver el problema de construir un árbol a partir de una lista ordenada, puedes mezclar aleatoriamente los datos de entrada.
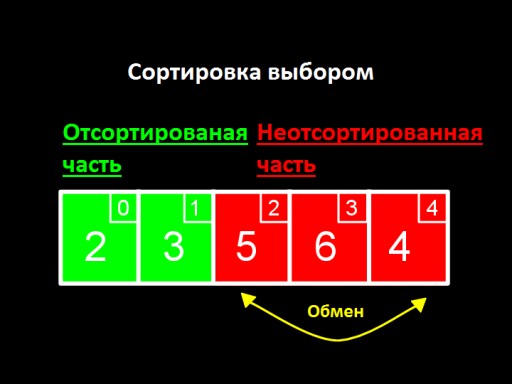 La idea principal es dividir nuestra lista en dos partes, ordenada y sin clasificar. En cada paso del algoritmo, se mueve un nuevo número de la parte no ordenada a la parte ordenada, y así sucesivamente hasta que todos los números estén en la parte ordenada.
La idea principal es dividir nuestra lista en dos partes, ordenada y sin clasificar. En cada paso del algoritmo, se mueve un nuevo número de la parte no ordenada a la parte ordenada, y así sucesivamente hasta que todos los números estén en la parte ordenada.
 Encontramos el número mínimo en la parte no ordenada de la matriz (es decir, en este paso, en toda la matriz). Este número es 2. Ahora lo cambiamos por el primero entre los no ordenados y lo colocamos al final de la matriz ordenada (en este paso, en primer lugar). En este paso, este es el primer número de la matriz, es decir, 3.
Encontramos el número mínimo en la parte no ordenada de la matriz (es decir, en este paso, en toda la matriz). Este número es 2. Ahora lo cambiamos por el primero entre los no ordenados y lo colocamos al final de la matriz ordenada (en este paso, en primer lugar). En este paso, este es el primer número de la matriz, es decir, 3.  Paso dos. No miramos el número 2; ya está en el subconjunto ordenado. Empezamos a buscar el mínimo, partiendo del segundo elemento, este es 5. Nos aseguramos de que 3 sea el mínimo entre los sin clasificar, 5 sea el primero entre los sin clasificar. Los intercambiamos y agregamos 3 al subarreglo ordenado.
Paso dos. No miramos el número 2; ya está en el subconjunto ordenado. Empezamos a buscar el mínimo, partiendo del segundo elemento, este es 5. Nos aseguramos de que 3 sea el mínimo entre los sin clasificar, 5 sea el primero entre los sin clasificar. Los intercambiamos y agregamos 3 al subarreglo ordenado.  En el tercer paso , vemos que el número más pequeño en el subarreglo sin ordenar es 4. Lo cambiamos con el primer número entre los sin ordenar: 5.
En el tercer paso , vemos que el número más pequeño en el subarreglo sin ordenar es 4. Lo cambiamos con el primer número entre los sin ordenar: 5.  En el cuarto paso, encontramos que en el arreglo sin ordenar el número más pequeño es 5. Lo cambiamos de 6 y lo agregamos al subarreglo ordenado.
En el cuarto paso, encontramos que en el arreglo sin ordenar el número más pequeño es 5. Lo cambiamos de 6 y lo agregamos al subarreglo ordenado. 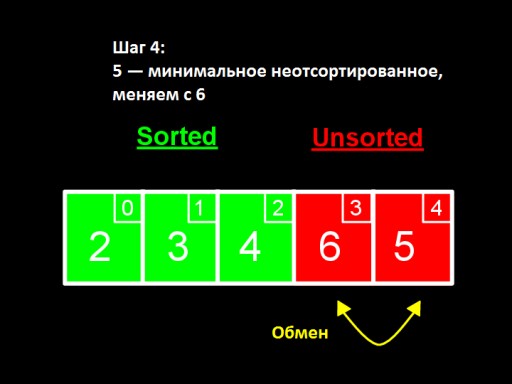 Cuando solo queda un número entre los no ordenados (el más grande), ¡esto significa que toda la matriz está ordenada!
Cuando solo queda un número entre los no ordenados (el más grande), ¡esto significa que toda la matriz está ordenada! 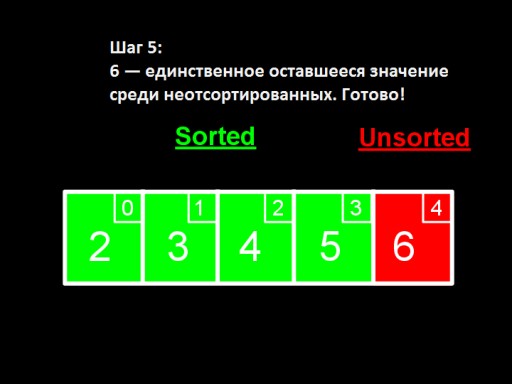 Así es como se ve la implementación de la matriz en el código. Intenta hacerlo tú mismo.
Así es como se ve la implementación de la matriz en el código. Intenta hacerlo tú mismo.  Tanto en el mejor como en el peor de los casos, para encontrar el elemento mínimo sin clasificar, debemos comparar cada elemento con cada elemento de la matriz sin clasificar, y haremos esto en cada iteración. Pero no necesitamos ver la lista completa, sino sólo la parte sin ordenar. ¿Esto cambia la velocidad del algoritmo? En el primer paso, para una matriz de 5 elementos, hacemos 4 comparaciones, en el segundo - 3, en el tercero - 2. Para obtener el número de comparaciones, debemos sumar todos estos números. Obtenemos la suma.
Tanto en el mejor como en el peor de los casos, para encontrar el elemento mínimo sin clasificar, debemos comparar cada elemento con cada elemento de la matriz sin clasificar, y haremos esto en cada iteración. Pero no necesitamos ver la lista completa, sino sólo la parte sin ordenar. ¿Esto cambia la velocidad del algoritmo? En el primer paso, para una matriz de 5 elementos, hacemos 4 comparaciones, en el segundo - 3, en el tercero - 2. Para obtener el número de comparaciones, debemos sumar todos estos números. Obtenemos la suma.  Por tanto, la velocidad esperada del algoritmo en el mejor y peor caso es Θ(n 2 ). ¡No es el algoritmo más eficiente! Sin embargo, para fines educativos y para conjuntos de datos pequeños es bastante aplicable.
Por tanto, la velocidad esperada del algoritmo en el mejor y peor caso es Θ(n 2 ). ¡No es el algoritmo más eficiente! Sin embargo, para fines educativos y para conjuntos de datos pequeños es bastante aplicable.
 Paso 1: revisa la matriz. El algoritmo comienza con los dos primeros elementos, 8 y 6, y comprueba si están en el orden correcto. 8 > 6, entonces los intercambiamos. A continuación miramos el segundo y tercer elemento, ahora son 8 y 4. Por las mismas razones, los intercambiamos. Por tercera vez comparamos 8 y 2. En total, hacemos tres intercambios (8, 6), (8, 4), (8, 2). El valor 8 "flotó" hasta el final de la lista en la posición correcta.
Paso 1: revisa la matriz. El algoritmo comienza con los dos primeros elementos, 8 y 6, y comprueba si están en el orden correcto. 8 > 6, entonces los intercambiamos. A continuación miramos el segundo y tercer elemento, ahora son 8 y 4. Por las mismas razones, los intercambiamos. Por tercera vez comparamos 8 y 2. En total, hacemos tres intercambios (8, 6), (8, 4), (8, 2). El valor 8 "flotó" hasta el final de la lista en la posición correcta.  Paso 2: intercambie (6,4) y (6,2). 6 se encuentra ahora en la penúltima posición y no es necesario compararlo con la “cola” ya ordenada de la lista.
Paso 2: intercambie (6,4) y (6,2). 6 se encuentra ahora en la penúltima posición y no es necesario compararlo con la “cola” ya ordenada de la lista.  Paso 3: intercambie 4 y 2. El cuatro “flota” al lugar que le corresponde.
Paso 3: intercambie 4 y 2. El cuatro “flota” al lugar que le corresponde.  Paso 4: recorremos el array, pero no tenemos nada que cambiar. Esto indica que la matriz está completamente ordenada.
Paso 4: recorremos el array, pero no tenemos nada que cambiar. Esto indica que la matriz está completamente ordenada. 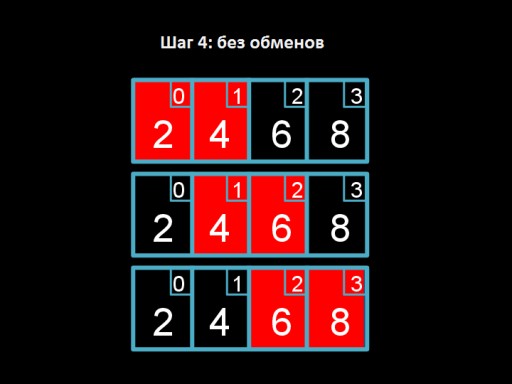 Y este es el código del algoritmo. ¡Intenta implementarlo en C!
Y este es el código del algoritmo. ¡Intenta implementarlo en C!  La clasificación de burbujas toma O(n 2 ) tiempo en el peor de los casos (todos los números son incorrectos), ya que necesitamos tomar n pasos en cada iteración, de los cuales también hay n. De hecho, como en el caso del algoritmo de clasificación por selección, el tiempo será ligeramente menor (n 2 /2 – n/2), pero esto puede despreciarse. En el mejor de los casos (si todos los elementos ya están en su lugar), podemos hacerlo en n pasos, es decir Ω(n), ya que solo necesitaremos iterar a través de la matriz una vez y asegurarnos de que todos los elementos estén en su lugar (es decir, incluso n-1 elementos).
La clasificación de burbujas toma O(n 2 ) tiempo en el peor de los casos (todos los números son incorrectos), ya que necesitamos tomar n pasos en cada iteración, de los cuales también hay n. De hecho, como en el caso del algoritmo de clasificación por selección, el tiempo será ligeramente menor (n 2 /2 – n/2), pero esto puede despreciarse. En el mejor de los casos (si todos los elementos ya están en su lugar), podemos hacerlo en n pasos, es decir Ω(n), ya que solo necesitaremos iterar a través de la matriz una vez y asegurarnos de que todos los elementos estén en su lugar (es decir, incluso n-1 elementos).

 Veamos cómo funciona la ordenación por inserción usando el siguiente ejemplo. Antes de comenzar, todos los elementos se consideran desordenados.
Veamos cómo funciona la ordenación por inserción usando el siguiente ejemplo. Antes de comenzar, todos los elementos se consideran desordenados.  Paso 1: tome el primer valor sin ordenar (3) e insértelo en el subarreglo ordenado. En este paso, todo el subconjunto ordenado, su principio y su final, serán estos tres.
Paso 1: tome el primer valor sin ordenar (3) e insértelo en el subarreglo ordenado. En este paso, todo el subconjunto ordenado, su principio y su final, serán estos tres.  Paso 2: Como 3 > 5, insertaremos 5 en el subarreglo ordenado a la derecha de 3.
Paso 2: Como 3 > 5, insertaremos 5 en el subarreglo ordenado a la derecha de 3.  Paso 3: Ahora trabajamos para insertar el número 2 en nuestro arreglo ordenado. Comparamos 2 con valores de derecha a izquierda para encontrar la posición correcta. Desde 2 <5 y 2 <3 y hemos llegado al comienzo del subarreglo ordenado. Por lo tanto, debemos insertar 2 a la izquierda de 3. Para ello, mueve 3 y 5 hacia la derecha para que quede espacio para el 2 e insértalo al principio del array.
Paso 3: Ahora trabajamos para insertar el número 2 en nuestro arreglo ordenado. Comparamos 2 con valores de derecha a izquierda para encontrar la posición correcta. Desde 2 <5 y 2 <3 y hemos llegado al comienzo del subarreglo ordenado. Por lo tanto, debemos insertar 2 a la izquierda de 3. Para ello, mueve 3 y 5 hacia la derecha para que quede espacio para el 2 e insértalo al principio del array.  Paso 4. Tenemos suerte: 6 > 5, entonces podemos insertar ese número justo después del número 5.
Paso 4. Tenemos suerte: 6 > 5, entonces podemos insertar ese número justo después del número 5.  Paso 5. 4 < 6 y 4 < 5, pero 4 > 3. Por lo tanto, sabemos que se debe insertar 4 para a la derecha de 3. Nuevamente, nos vemos obligados a mover 5 y 6 hacia la derecha para crear un espacio para 4. ¡
Paso 5. 4 < 6 y 4 < 5, pero 4 > 3. Por lo tanto, sabemos que se debe insertar 4 para a la derecha de 3. Nuevamente, nos vemos obligados a mover 5 y 6 hacia la derecha para crear un espacio para 4. ¡  Listo! Algoritmo generalizado: tome cada elemento no ordenado de n y compárelo con los valores en el subarreglo ordenado de derecha a izquierda hasta que encontremos una posición adecuada para n (es decir, el momento en que encontramos el primer número que es menor que n) . Luego, desplazamos todos los elementos ordenados que están a la derecha de este número hacia la derecha para dejar espacio para nuestra n, y la insertamos allí, expandiendo así la parte ordenada de la matriz. Para cada elemento n sin clasificar necesitas:
Listo! Algoritmo generalizado: tome cada elemento no ordenado de n y compárelo con los valores en el subarreglo ordenado de derecha a izquierda hasta que encontremos una posición adecuada para n (es decir, el momento en que encontramos el primer número que es menor que n) . Luego, desplazamos todos los elementos ordenados que están a la derecha de este número hacia la derecha para dejar espacio para nuestra n, y la insertamos allí, expandiendo así la parte ordenada de la matriz. Para cada elemento n sin clasificar necesitas:

 Digamos que tenemos n elementos para ordenar. Si n <2, terminamos de ordenar; de lo contrario, ordenamos las partes izquierda y derecha de la matriz por separado y luego las combinamos. Ordenemos el arreglo,
Digamos que tenemos n elementos para ordenar. Si n <2, terminamos de ordenar; de lo contrario, ordenamos las partes izquierda y derecha de la matriz por separado y luego las combinamos. Ordenemos el arreglo,  dividámoslo en dos partes y continuamos dividiéndolo hasta obtener subarreglos de tamaño 1, que obviamente están ordenados.
dividámoslo en dos partes y continuamos dividiéndolo hasta obtener subarreglos de tamaño 1, que obviamente están ordenados.  Se pueden fusionar dos subarreglos ordenados en tiempo O(n) usando un algoritmo simple: elimine el número más pequeño al comienzo de cada subarreglo e insértelo en el arreglo fusionado. Repita hasta que se acaben todos los elementos.
Se pueden fusionar dos subarreglos ordenados en tiempo O(n) usando un algoritmo simple: elimine el número más pequeño al comienzo de cada subarreglo e insértelo en el arreglo fusionado. Repita hasta que se acaben todos los elementos. 
 La clasificación por combinación requiere un tiempo O (nlog n) para todos los casos. Mientras dividimos las matrices en mitades en cada nivel de recursividad obtenemos log n. Entonces, fusionar los subarreglos requiere solo n comparaciones. Por lo tanto O(nlog n). Los mejores y peores casos para la ordenación por fusión son los mismos: el tiempo de ejecución esperado del algoritmo = Θ(nlog n). Este algoritmo es el más eficaz entre los considerados.
La clasificación por combinación requiere un tiempo O (nlog n) para todos los casos. Mientras dividimos las matrices en mitades en cada nivel de recursividad obtenemos log n. Entonces, fusionar los subarreglos requiere solo n comparaciones. Por lo tanto O(nlog n). Los mejores y peores casos para la ordenación por fusión son los mismos: el tiempo de ejecución esperado del algoritmo = Θ(nlog n). Este algoritmo es el más eficaz entre los considerados. 

GO TO FULL VERSION