Misurare la velocità di un algoritmo in tempo reale, in secondi e minuti, non è facile. Un programma può funzionare più lentamente di un altro non a causa della sua inefficienza, ma a causa della lentezza del sistema operativo, dell'incompatibilità con l'hardware, della memoria del computer occupata da altri processi... Per misurare l'efficacia degli algoritmi, sono stati inventati concetti universali , indipendentemente dall'ambiente in cui viene eseguito il programma. La complessità asintotica di un problema viene misurata utilizzando la notazione Big O. Siano f(x) e g(x) funzioni definite in un certo intorno di x0, e lì g non si annulla. Allora f è “O” maggiore di g per (x -> x0) se esiste una costante C> 0 , che per tutti gli x da qualche intorno del punto x0 vale la disuguaglianza |f(x)| <= C |g(x)| Leggermente meno stringente: f è “O” maggiore di g se esiste una costante C>0, che per tutti x > x0 f(x) <= C*g(x) Non aver paura di la definizione formale! In sostanza, determina l'aumento asintotico del tempo di esecuzione del programma quando la quantità di dati di input cresce verso l'infinito. Ad esempio, stai confrontando l'ordinamento di un array di 1000 elementi e 10 elementi e devi capire come aumenterà il tempo di esecuzione del programma. Oppure devi calcolare la lunghezza di una stringa di caratteri procedendo carattere per carattere e aggiungendo 1 per ogni carattere: c - 1 a - 2 t - 3 la sua velocità asintotica = O(n), dove n è il numero di lettere nella parola. Se conti secondo questo principio, il tempo necessario per contare l'intera riga è proporzionale al numero di caratteri. Il conteggio del numero di caratteri in una stringa di 20 caratteri richiede il doppio del tempo rispetto al conteggio del numero di caratteri in una stringa di dieci caratteri. Immagina che nella variabile length tu abbia memorizzato un valore pari al numero di caratteri nella stringa. Ad esempio, lunghezza = 1000. Per ottenere la lunghezza di una stringa, devi solo accedere a questa variabile e non devi nemmeno guardare la stringa stessa. E non importa come modifichiamo la lunghezza, possiamo sempre accedere a questa variabile. In questo caso, velocità asintotica = O(1). La modifica dei dati di input non cambia la velocità di tale attività; la ricerca viene completata in un tempo costante. In questo caso il programma è asintoticamente costante. Svantaggio: si spreca memoria del computer memorizzando una variabile aggiuntiva e tempo aggiuntivo per aggiornarne il valore. Se pensi che il tempo lineare sia negativo, possiamo assicurarti che può essere molto peggio. Ad esempio, O(n2 ) . Questa notazione significa che man mano che n cresce, il tempo richiesto per scorrere gli elementi (o un'altra azione) aumenterà sempre di più. Ma per n piccoli, gli algoritmi con velocità asintotica O(n 2 ) possono funzionare più velocemente degli algoritmi con velocità asintotica O(n). Ma ad un certo punto la funzione quadratica supererà quella lineare, non c'è modo di aggirarla. Un'altra complessità asintotica è il tempo logaritmico o O(log n). All'aumentare di n, questa funzione aumenta molto lentamente. O(log n) è il tempo di esecuzione del classico algoritmo di ricerca binaria in un array ordinato (ricordate l'elenco telefonico strappato nella lezione?). L'array viene diviso in due, quindi viene selezionata la metà in cui si trova l'elemento e così, riducendo ogni volta della metà l'area di ricerca, si cerca l'elemento. Cosa succede se ci imbattiamo immediatamente in ciò che stiamo cercando, dividendo per la prima volta il nostro array di dati a metà? Esiste un termine per indicare il momento migliore: Omega-grande o Ω(n). Nel caso della ricerca binaria = Ω(1) (trova in tempo costante, indipendentemente dalla dimensione dell'array). La ricerca lineare viene eseguita in tempo O(n) e Ω(1) se l'elemento da cercare è il primo. Un altro simbolo è theta (Θ(n)). Viene utilizzato quando le opzioni migliori e peggiori coincidono. Questo è adatto per un esempio in cui abbiamo memorizzato la lunghezza di una stringa in una variabile separata, quindi per qualsiasi lunghezza è sufficiente fare riferimento a questa variabile. Per questo algoritmo, il caso migliore e quello peggiore sono rispettivamente Ω(1) e O(1). Ciò significa che l'algoritmo viene eseguito nel tempo Θ(1).
Ricerca lineare
Quando apri un browser web, cerchi una pagina, informazioni, amici sui social network, stai facendo una ricerca, proprio come quando cerchi di trovare il paio di scarpe giusto in un negozio. Probabilmente hai notato che l'ordine ha un grande impatto sul modo in cui effettui le ricerche. Se hai tutte le camicie nell'armadio, solitamente è più facile trovare quella che ti serve tra queste piuttosto che tra quelle sparse senza sistema per la stanza. La ricerca lineare è un metodo di ricerca sequenziale, uno per uno. Quando esamini i risultati di ricerca di Google dall'alto verso il basso, stai utilizzando una ricerca lineare. Esempio . Diciamo di avere una lista di numeri: 2 4 0 5 3 7 8 1 e dobbiamo trovare lo 0. Lo vediamo subito, ma un programma per computer non funziona in questo modo. Comincia dall'inizio dell'elenco e vede il numero 2. Poi controlla, 2=0? Non lo è, quindi continua e passa al secondo personaggio. Anche lì l'attende il fallimento e solo nella terza posizione l'algoritmo trova il numero richiesto. Pseudocodice per la ricerca lineare: La funzione linearSearch riceve due argomenti come input: la chiave key e l'array array[]. La chiave è il valore desiderato, nell'esempio precedente key = 0. L'array è un elenco di numeri che noi guarderò attraverso. Se non troviamo nulla, la funzione restituirà -1 (una posizione che non esiste nell'array). Se la ricerca lineare trova l'elemento desiderato, la funzione restituirà la posizione in cui si trova l'elemento desiderato nell'array. L'aspetto positivo della ricerca lineare è che funzionerà per qualsiasi array, indipendentemente dall'ordine degli elementi: esamineremo comunque l'intero array. Questa è anche la sua debolezza. Se devi trovare il numero 198 in un array di 200 numeri ordinati, il ciclo for eseguirà 198 passaggi. Probabilmente hai già indovinato quale metodo funziona meglio per un array ordinato?
Ricerca binaria e alberi
Immagina di avere un elenco di personaggi Disney in ordine alfabetico e di dover trovare Topolino. Linearmente ci vorrebbe molto tempo. E se usiamo il "metodo di dividere la directory a metà", arriviamo direttamente a Jasmine e possiamo tranquillamente scartare la prima metà dell'elenco, rendendoci conto che Topolino non può essere lì. Utilizzando lo stesso principio, scartiamo la seconda colonna. Proseguendo questa strategia troveremo Topolino in un paio di passaggi. Troviamo il numero 144. Dividiamo la lista a metà e arriviamo al numero 13. Valutiamo se il numero che cerchiamo è maggiore o minore di 13. 13 < 144, quindi possiamo ignorare tutto ciò che si trova a sinistra di 13 e questo numero stesso. Ora il nostro elenco di ricerca si presenta così: C'è un numero pari di elementi, quindi scegliamo il principio in base al quale selezioniamo il "centro" (più vicino all'inizio o alla fine). Diciamo che abbiamo scelto fin dall'inizio la strategia della prossimità. In questo caso, il nostro "centro" = 55. 55 < 144. Scartiamo nuovamente la metà sinistra della lista. Fortunatamente per noi, il numero medio successivo è 144. Abbiamo trovato 144 in un array di 13 elementi utilizzando la ricerca binaria in soli tre passaggi. Una ricerca lineare gestirebbe la stessa situazione in un massimo di 12 passaggi. Poiché questo algoritmo riduce della metà il numero di elementi nell'array ad ogni passaggio, troverà quello richiesto in tempo asintotico O(log n), dove n è il numero di elementi nell'elenco. Cioè, nel nostro caso, il tempo asintotico = O(log 13) (questo è poco più di tre). Pseudocodice della funzione di ricerca binaria: La funzione accetta 4 argomenti come input: la chiave desiderata, l'array di dati array [], in cui si trova quello desiderato, min e max sono puntatori al numero massimo e minimo nell'array, che stiamo esaminando questo passaggio dell'algoritmo. Per il nostro esempio inizialmente è stata fornita la seguente immagine: Analizziamo ulteriormente il codice. il punto medio è il nostro centro dell'array. Dipende dai punti estremi ed è centrato tra loro. Dopo aver trovato la metà, controlliamo se è inferiore al nostro numero di chiave. Se è così, allora anche la chiave è maggiore di qualsiasi numero a sinistra del centro e possiamo chiamare di nuovo la funzione binaria, solo che ora il nostro min = punto medio + 1. Se risulta che chiave < punto medio, possiamo scartare quel numero stesso e tutti i numeri, che giacciono alla sua destra. E chiamiamo una ricerca binaria attraverso l'array dal numero min fino al valore (punto medio – 1). Infine, il terzo ramo: se il valore nel punto medio non è né maggiore né minore della chiave, non ha altra scelta che essere il numero desiderato. In questo caso, lo restituiamo e terminiamo il programma. Infine, può succedere che il numero che stai cercando non sia affatto nell'array. Per tenere conto di questo caso, eseguiamo il seguente controllo: E restituiamo (-1) per indicare che non abbiamo trovato nulla. Sai già che la ricerca binaria richiede l'ordinamento dell'array. Pertanto, se abbiamo un array non ordinato in cui dobbiamo trovare un determinato elemento, abbiamo due opzioni:
Ordina l'elenco e applica la ricerca binaria
Mantieni l'elenco sempre ordinato aggiungendo e rimuovendo contemporaneamente elementi da esso.
Un modo per mantenere ordinati gli elenchi è utilizzare un albero di ricerca binario. Un albero di ricerca binario è una struttura dati che soddisfa i seguenti requisiti:
È un albero (una struttura dati che emula una struttura ad albero - ha una radice e altri nodi (foglie) collegati da "rami" o bordi senza cicli)
Ogni nodo ha 0, 1 o 2 figli
Entrambi i sottoalberi sinistro e destro sono alberi di ricerca binari.
Tutti i nodi del sottoalbero sinistro di un nodo X arbitrario hanno valori della chiave dati inferiori al valore della chiave dati del nodo X stesso.
Tutti i nodi nel sottoalbero destro di un nodo X arbitrario hanno valori della chiave dati maggiori o uguali al valore della chiave dati del nodo X stesso.
Attenzione: la radice dell'albero “programmatore”, a differenza di quello reale, è in alto. Ogni cella è chiamata vertice e i vertici sono collegati da bordi. La radice dell'albero è la cella numero 13. Il sottoalbero sinistro del vertice 3 è evidenziato a colori nell'immagine seguente: Il nostro albero soddisfa tutti i requisiti per gli alberi binari. Ciò significa che ciascuno dei suoi sottoalberi di sinistra contiene solo valori inferiori o uguali al valore del vertice, mentre il sottoalbero di destra contiene solo valori maggiori o uguali al valore del vertice. Entrambi i sottoalberi sinistro e destro sono essi stessi sottoalberi binari. Il metodo per costruire un albero binario non è l'unico: sotto nell'immagine vedi un'altra opzione per lo stesso insieme di numeri, e in pratica possono essercene molti. Questa struttura aiuta ad effettuare la ricerca: troviamo il valore minimo spostandoci ogni volta dall'alto verso sinistra e verso il basso. Se hai bisogno di trovare il numero massimo, andiamo dall'alto verso il basso e verso destra. Anche trovare un numero che non sia il minimo o il massimo è abbastanza semplice. Scendiamo dalla radice verso sinistra o verso destra, a seconda che il nostro vertice sia più grande o più piccolo di quello che cerchiamo. Quindi, se dobbiamo trovare il numero 89, seguiamo questo percorso: puoi anche visualizzare i numeri in ordine. Se ad esempio dobbiamo visualizzare tutti i numeri in ordine crescente, prendiamo il sottoalbero di sinistra e, partendo dal vertice più a sinistra, saliamo. Anche aggiungere qualcosa all'albero è facile. La cosa principale da ricordare è la struttura. Diciamo che dobbiamo aggiungere all'albero il valore 7. Andiamo alla radice e controlliamo. Il numero 7 < 13, quindi andiamo a sinistra. Qui vediamo 5 e andiamo a destra, poiché 7 > 5. Inoltre, poiché 7 > 8 e 8 non ha discendenti, costruiamo un ramo da 8 a sinistra e gli attacchiamo 7. Puoi anche rimuovere i vertici da l'albero, ma questo è un po' più complicato. Esistono tre diversi scenari di eliminazione che dobbiamo considerare.
L'opzione più semplice: dobbiamo eliminare un vertice che non ha figli. Ad esempio, il numero 7 che abbiamo appena aggiunto. In questo caso seguiamo semplicemente il percorso fino al vertice con questo numero e lo cancelliamo.
Un vertice ha un vertice figlio. In questo caso è possibile eliminare il vertice desiderato, ma il suo discendente deve essere collegato al “nonno”, cioè al vertice da cui è cresciuto il suo immediato antenato. Ad esempio, dallo stesso albero dobbiamo rimuovere il numero 3. In questo caso uniamo il suo discendente, uno, insieme all'intero sottoalbero a 5. Questo viene fatto semplicemente, poiché tutti i vertici a sinistra di 5 saranno inferiore a questo numero (e inferiore alla tripla remota).
Il caso più difficile è quando il vertice da eliminare ha due figli. Ora la prima cosa che dobbiamo fare è trovare il vertice in cui è nascosto il valore successivo più grande, dobbiamo scambiarli e quindi eliminare il vertice desiderato. Si noti che il successivo vertice con il valore più alto non può avere due figli, quindi il figlio sinistro sarà il miglior candidato per il valore successivo. Rimuoviamo dal nostro albero il nodo radice 13. Per prima cosa cerchiamo il numero più vicino a 13, che è maggiore di esso. Questo è 21. Scambia 21 e 13 ed elimina 13.
Esistono diversi modi per costruire alberi binari, alcuni buoni, altri meno buoni. Cosa succede se proviamo a costruire un albero binario da un elenco ordinato? Tutti i numeri verranno semplicemente aggiunti al ramo destro del precedente. Se vogliamo trovare un numero, non avremo altra scelta che seguire semplicemente la catena verso il basso. Non è meglio della ricerca lineare. Esistono altre strutture dati più complesse. Ma per ora non li prenderemo in considerazione. Diciamo solo che per risolvere il problema della costruzione di un albero da un elenco ordinato, è possibile mescolare in modo casuale i dati di input.
Algoritmi di ordinamento
C'è una serie di numeri. Dobbiamo sistemarlo. Per semplicità, supponiamo di ordinare i numeri interi in ordine crescente (dal più piccolo al più grande). Esistono diversi modi noti per eseguire questo processo. Inoltre, puoi sempre inventare l'argomento e inventare una modifica dell'algoritmo.
Ordinamento per selezione
L'idea principale è dividere la nostra lista in due parti, ordinate e non ordinate. Ad ogni passo dell'algoritmo, un nuovo numero viene spostato dalla parte non ordinata a quella ordinata, e così via finché tutti i numeri non si trovano nella parte ordinata.
Trova il valore minimo non ordinato.
Scambiamo questo valore con il primo valore non ordinato, posizionandolo così alla fine dell'array ordinato.
Se sono rimasti valori non ordinati, tornare al passaggio 1.
Nel primo passaggio, tutti i valori non sono ordinati. Chiameremo la parte non ordinata Unsorted e la parte ordinata Ordinata (queste sono solo parole inglesi e lo facciamo solo perché Sorted è molto più breve di "Parte ordinata" e avrà un aspetto migliore nelle immagini). Troviamo il numero minimo nella parte non ordinata dell'array (ovvero, in questo passaggio, nell'intero array). Questo numero è 2. Ora lo cambiamo con il primo tra quelli non ordinati e lo mettiamo alla fine dell'array ordinato (in questo passaggio - al primo posto). In questo passaggio, questo è il primo numero nell'array, ovvero 3. Passaggio due. Non guardiamo il numero 2; è già nel sottoarray ordinato. Iniziamo a cercare il minimo, partendo dal secondo elemento, questo è 5. Facciamo attenzione che 3 sia il minimo tra gli non ordinati, 5 sia il primo tra i non ordinati. Li scambiamo e aggiungiamo 3 al sottoarray ordinato. Nel terzo passaggio , vediamo che il numero più piccolo nel sottoarray non ordinato è 4. Lo cambiamo con il primo numero tra quelli non ordinati - 5. Nel quarto passaggio, troviamo che nel array non ordinato il numero più piccolo è 5. Lo cambiamo da 6 e lo aggiungiamo al sottoarray ordinato. Quando tra quelli non ordinati rimane solo un numero (il più grande), significa che l'intero array è ordinato! Questo è l'aspetto dell'implementazione dell'array nel codice. Prova a farlo da solo. Sia nel migliore che nel peggiore dei casi, per trovare l'elemento minimo non ordinato, dobbiamo confrontare ciascun elemento con ciascun elemento dell'array non ordinato, e lo faremo ad ogni iterazione. Ma non abbiamo bisogno di visualizzare l'intero elenco, ma solo la parte non ordinata. Questo cambia la velocità dell’algoritmo? Nel primo passaggio, per un array di 5 elementi, facciamo 4 confronti, nel secondo - 3, nel terzo - 2. Per ottenere il numero di confronti, dobbiamo sommare tutti questi numeri. Otteniamo la somma. Pertanto, la velocità attesa dell'algoritmo nel caso migliore e in quello peggiore è Θ(n 2 ). Non è l'algoritmo più efficiente! Tuttavia, per scopi didattici e per piccoli set di dati è abbastanza applicabile.
Ordinamento delle bolle
L'algoritmo di bubble sort è uno dei più semplici. Percorriamo l'intero array e confrontiamo 2 elementi vicini. Se sono nell'ordine sbagliato, li scambiamo. Al primo passaggio, alla fine apparirà l'elemento più piccolo (“float”) (se ordiniamo in ordine decrescente). Ripetere il primo passaggio se nel passaggio precedente è stato completato almeno uno scambio. Ordiniamo l'array. Passaggio 1: esaminare l'array. L'algoritmo inizia con i primi due elementi, 8 e 6, e controlla se sono nell'ordine corretto. 8 > 6, quindi li invertiamo. Successivamente guardiamo il secondo e il terzo elemento, ora questi sono 8 e 4. Per gli stessi motivi, li scambiamo. Per la terza volta confrontiamo 8 e 2. In totale facciamo tre scambi (8, 6), (8, 4), (8, 2). Il valore 8 "fluttua" alla fine dell'elenco nella posizione corretta. Passaggio 2: scambiare (6,4) e (6,2). 6 è ora in penultima posizione e non c'è bisogno di confrontarlo con la “coda” già ordinata della lista. Passaggio 3: scambia 4 e 2. I quattro "galleggiano" al posto giusto. Passaggio 4: esaminiamo l'array, ma non abbiamo nulla da modificare. Ciò segnala che l'array è completamente ordinato. E questo è il codice dell'algoritmo. Prova a implementarlo in C! Il bubble sort richiede un tempo O(n 2 ) nel caso peggiore (tutti i numeri sono sbagliati), poiché dobbiamo fare n passi ad ogni iterazione, di cui ci sono anche n. Infatti, come nel caso dell'algoritmo di ordinamento per selezione, il tempo sarà leggermente inferiore (n 2 /2 – n/2), ma questo può essere trascurato. Nel migliore dei casi (se tutti gli elementi sono già presenti), possiamo farlo in n passaggi, ovvero Ω(n), poiché dovremo solo scorrere l'array una volta e assicurarci che tutti gli elementi siano al loro posto (cioè anche n-1 elementi).
Ordinamento di inserimento
L'idea principale di questo algoritmo è dividere il nostro array in due parti, ordinate e non ordinate. Ad ogni passo dell'algoritmo, il numero si sposta dalla parte non ordinata a quella ordinata. Diamo un'occhiata a come funziona l'ordinamento per inserzione utilizzando l'esempio seguente. Prima di iniziare, tutti gli elementi sono considerati non ordinati. Passaggio 1: prendi il primo valore non ordinato (3) e inseriscilo nel sottoarray ordinato. A questo punto, l'intero sottoarray ordinato, il suo inizio e la sua fine saranno proprio questi tre. Passaggio 2: poiché 3 > 5, inseriremo 5 nel sottoarray ordinato a destra di 3. Passaggio 3: ora lavoriamo sull'inserimento del numero 2 nel nostro array ordinato. Confrontiamo 2 con valori da destra a sinistra per trovare la posizione corretta. Dato che 2 < 5 e 2 < 3 abbiamo raggiunto l'inizio del sottoarray ordinato. Dobbiamo quindi inserire 2 a sinistra di 3. Per fare ciò, sposta 3 e 5 a destra in modo che ci sia spazio per il 2 e inseriscilo all'inizio dell'array. Passaggio 4. Siamo fortunati: 6 > 5, quindi possiamo inserire quel numero subito dopo il numero 5. Passaggio 5. 4 < 6 e 4 < 5, ma 4 > 3. Pertanto, sappiamo che 4 deve essere inserito per a destra di 3. Ancora una volta, siamo costretti a spostare 5 e 6 a destra per creare uno spazio per 4. Fatto! Algoritmo generalizzato: prendi ogni elemento non ordinato di n e confrontalo con i valori nel sottoarray ordinato da destra a sinistra finché non troviamo una posizione adatta per n (ovvero nel momento in cui troviamo il primo numero inferiore a n) . Quindi spostiamo tutti gli elementi ordinati che si trovano a destra di questo numero a destra per fare spazio al nostro n, e lo inseriamo lì, espandendo così la parte ordinata dell'array. Per ogni elemento non ordinato n è necessario:
Determina la posizione nella parte ordinata dell'array in cui deve essere inserito n
Sposta gli elementi ordinati a destra per creare uno spazio per n
Inserisci n nello spazio risultante nella parte ordinata dell'array.
Ed ecco il codice! Ti consigliamo di scrivere la tua versione del programma di ordinamento.
Velocità asintotica dell'algoritmo
Nel peggiore dei casi faremo un confronto con il secondo elemento, due confronti con il terzo e così via. Quindi la nostra velocità è O(n 2 ). Nella migliore delle ipotesi, lavoreremo con un array già ordinato. La parte ordinata, che costruiremo da sinistra a destra senza inserimenti e spostamenti di elementi, impiegherà tempo Ω(n).
Unisci ordinamento
Questo algoritmo è ricorsivo; suddivide un grande problema di ordinamento in sottoattività, la cui esecuzione lo avvicina alla risoluzione del grande problema originale. L'idea principale è dividere un array non ordinato in due parti e ordinare ricorsivamente le singole metà. Diciamo che abbiamo n elementi da ordinare. Se n < 2, terminiamo l'ordinamento, altrimenti ordiniamo separatamente le parti sinistra e destra dell'array e poi le combiniamo. Ordiniamo l'array: dividiamolo in due parti e continuiamo a dividere finché non otteniamo sottoarray di dimensione 1, che ovviamente sono ordinati. Due sottoarray ordinati possono essere uniti in tempo O(n) utilizzando un semplice algoritmo: rimuovere il numero più piccolo all'inizio di ciascun sottoarray e inserirlo nell'array unito. Ripeti fino a quando tutti gli elementi non saranno scomparsi. Il merge sort richiede tempo O(nlog n) per tutti i casi. Mentre dividiamo gli array a metà ad ogni livello di ricorsione otteniamo il log n. Quindi, l'unione dei sottoarray richiede solo n confronti. Pertanto O(nlog n). Il caso migliore e quello peggiore per il merge sort sono gli stessi, il tempo di esecuzione previsto dell'algoritmo = Θ(nlog n). Questo algoritmo è il più efficace tra quelli considerati.
 Ma ad un certo punto la funzione quadratica supererà quella lineare, non c'è modo di aggirarla. Un'altra complessità asintotica è il tempo logaritmico o O(log n). All'aumentare di n, questa funzione aumenta molto lentamente. O(log n) è il tempo di esecuzione del classico algoritmo di ricerca binaria in un array ordinato (ricordate l'elenco telefonico strappato nella lezione?). L'array viene diviso in due, quindi viene selezionata la metà in cui si trova l'elemento e così, riducendo ogni volta della metà l'area di ricerca, si cerca l'elemento.
Ma ad un certo punto la funzione quadratica supererà quella lineare, non c'è modo di aggirarla. Un'altra complessità asintotica è il tempo logaritmico o O(log n). All'aumentare di n, questa funzione aumenta molto lentamente. O(log n) è il tempo di esecuzione del classico algoritmo di ricerca binaria in un array ordinato (ricordate l'elenco telefonico strappato nella lezione?). L'array viene diviso in due, quindi viene selezionata la metà in cui si trova l'elemento e così, riducendo ogni volta della metà l'area di ricerca, si cerca l'elemento.  Cosa succede se ci imbattiamo immediatamente in ciò che stiamo cercando, dividendo per la prima volta il nostro array di dati a metà? Esiste un termine per indicare il momento migliore: Omega-grande o Ω(n). Nel caso della ricerca binaria = Ω(1) (trova in tempo costante, indipendentemente dalla dimensione dell'array). La ricerca lineare viene eseguita in tempo O(n) e Ω(1) se l'elemento da cercare è il primo. Un altro simbolo è theta (Θ(n)). Viene utilizzato quando le opzioni migliori e peggiori coincidono. Questo è adatto per un esempio in cui abbiamo memorizzato la lunghezza di una stringa in una variabile separata, quindi per qualsiasi lunghezza è sufficiente fare riferimento a questa variabile. Per questo algoritmo, il caso migliore e quello peggiore sono rispettivamente Ω(1) e O(1). Ciò significa che l'algoritmo viene eseguito nel tempo Θ(1).
Cosa succede se ci imbattiamo immediatamente in ciò che stiamo cercando, dividendo per la prima volta il nostro array di dati a metà? Esiste un termine per indicare il momento migliore: Omega-grande o Ω(n). Nel caso della ricerca binaria = Ω(1) (trova in tempo costante, indipendentemente dalla dimensione dell'array). La ricerca lineare viene eseguita in tempo O(n) e Ω(1) se l'elemento da cercare è il primo. Un altro simbolo è theta (Θ(n)). Viene utilizzato quando le opzioni migliori e peggiori coincidono. Questo è adatto per un esempio in cui abbiamo memorizzato la lunghezza di una stringa in una variabile separata, quindi per qualsiasi lunghezza è sufficiente fare riferimento a questa variabile. Per questo algoritmo, il caso migliore e quello peggiore sono rispettivamente Ω(1) e O(1). Ciò significa che l'algoritmo viene eseguito nel tempo Θ(1).
 funzione linearSearch riceve due argomenti come input: la chiave key e l'array array[]. La chiave è il valore desiderato, nell'esempio precedente key = 0. L'array è un elenco di numeri che noi guarderò attraverso. Se non troviamo nulla, la funzione restituirà -1 (una posizione che non esiste nell'array). Se la ricerca lineare trova l'elemento desiderato, la funzione restituirà la posizione in cui si trova l'elemento desiderato nell'array. L'aspetto positivo della ricerca lineare è che funzionerà per qualsiasi array, indipendentemente dall'ordine degli elementi: esamineremo comunque l'intero array. Questa è anche la sua debolezza. Se devi trovare il numero 198 in un array di 200 numeri ordinati, il ciclo for eseguirà 198 passaggi.
funzione linearSearch riceve due argomenti come input: la chiave key e l'array array[]. La chiave è il valore desiderato, nell'esempio precedente key = 0. L'array è un elenco di numeri che noi guarderò attraverso. Se non troviamo nulla, la funzione restituirà -1 (una posizione che non esiste nell'array). Se la ricerca lineare trova l'elemento desiderato, la funzione restituirà la posizione in cui si trova l'elemento desiderato nell'array. L'aspetto positivo della ricerca lineare è che funzionerà per qualsiasi array, indipendentemente dall'ordine degli elementi: esamineremo comunque l'intero array. Questa è anche la sua debolezza. Se devi trovare il numero 198 in un array di 200 numeri ordinati, il ciclo for eseguirà 198 passaggi.  Probabilmente hai già indovinato quale metodo funziona meglio per un array ordinato?
Probabilmente hai già indovinato quale metodo funziona meglio per un array ordinato?

 Linearmente ci vorrebbe molto tempo. E se usiamo il "metodo di dividere la directory a metà", arriviamo direttamente a Jasmine e possiamo tranquillamente scartare la prima metà dell'elenco, rendendoci conto che Topolino non può essere lì.
Linearmente ci vorrebbe molto tempo. E se usiamo il "metodo di dividere la directory a metà", arriviamo direttamente a Jasmine e possiamo tranquillamente scartare la prima metà dell'elenco, rendendoci conto che Topolino non può essere lì.  Utilizzando lo stesso principio, scartiamo la seconda colonna. Proseguendo questa strategia troveremo Topolino in un paio di passaggi.
Utilizzando lo stesso principio, scartiamo la seconda colonna. Proseguendo questa strategia troveremo Topolino in un paio di passaggi.  Troviamo il numero 144. Dividiamo la lista a metà e arriviamo al numero 13. Valutiamo se il numero che cerchiamo è maggiore o minore di 13. 13 < 144, quindi possiamo ignorare tutto ciò che si trova a sinistra
Troviamo il numero 144. Dividiamo la lista a metà e arriviamo al numero 13. Valutiamo se il numero che cerchiamo è maggiore o minore di 13. 13 < 144, quindi possiamo ignorare tutto ciò che si trova a sinistra  di 13 e questo numero stesso. Ora il nostro elenco di ricerca si presenta così:
di 13 e questo numero stesso. Ora il nostro elenco di ricerca si presenta così: 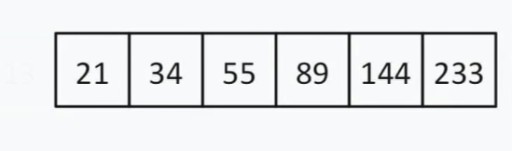 C'è un numero pari di elementi, quindi scegliamo il principio in base al quale selezioniamo il "centro" (più vicino all'inizio o alla fine). Diciamo che abbiamo scelto fin dall'inizio la strategia della prossimità. In questo caso, il nostro "centro" = 55.
C'è un numero pari di elementi, quindi scegliamo il principio in base al quale selezioniamo il "centro" (più vicino all'inizio o alla fine). Diciamo che abbiamo scelto fin dall'inizio la strategia della prossimità. In questo caso, il nostro "centro" = 55.  55 < 144. Scartiamo nuovamente la metà sinistra della lista. Fortunatamente per noi, il numero medio successivo è 144.
55 < 144. Scartiamo nuovamente la metà sinistra della lista. Fortunatamente per noi, il numero medio successivo è 144.  Abbiamo trovato 144 in un array di 13 elementi utilizzando la ricerca binaria in soli tre passaggi. Una ricerca lineare gestirebbe la stessa situazione in un massimo di 12 passaggi. Poiché questo algoritmo riduce della metà il numero di elementi nell'array ad ogni passaggio, troverà quello richiesto in tempo asintotico O(log n), dove n è il numero di elementi nell'elenco. Cioè, nel nostro caso, il tempo asintotico = O(log 13) (questo è poco più di tre). Pseudocodice della funzione di ricerca binaria:
Abbiamo trovato 144 in un array di 13 elementi utilizzando la ricerca binaria in soli tre passaggi. Una ricerca lineare gestirebbe la stessa situazione in un massimo di 12 passaggi. Poiché questo algoritmo riduce della metà il numero di elementi nell'array ad ogni passaggio, troverà quello richiesto in tempo asintotico O(log n), dove n è il numero di elementi nell'elenco. Cioè, nel nostro caso, il tempo asintotico = O(log 13) (questo è poco più di tre). Pseudocodice della funzione di ricerca binaria: 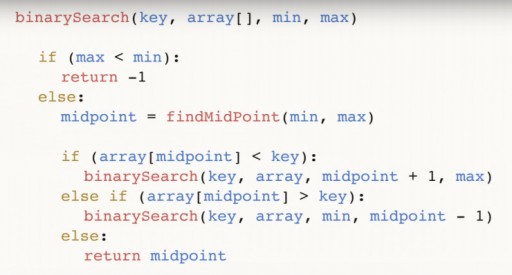 La funzione accetta 4 argomenti come input: la chiave desiderata, l'array di dati array [], in cui si trova quello desiderato, min e max sono puntatori al numero massimo e minimo nell'array, che stiamo esaminando questo passaggio dell'algoritmo. Per il nostro esempio inizialmente è stata fornita la seguente immagine:
La funzione accetta 4 argomenti come input: la chiave desiderata, l'array di dati array [], in cui si trova quello desiderato, min e max sono puntatori al numero massimo e minimo nell'array, che stiamo esaminando questo passaggio dell'algoritmo. Per il nostro esempio inizialmente è stata fornita la seguente immagine:  Analizziamo ulteriormente il codice. il punto medio è il nostro centro dell'array. Dipende dai punti estremi ed è centrato tra loro. Dopo aver trovato la metà, controlliamo se è inferiore al nostro numero di chiave.
Analizziamo ulteriormente il codice. il punto medio è il nostro centro dell'array. Dipende dai punti estremi ed è centrato tra loro. Dopo aver trovato la metà, controlliamo se è inferiore al nostro numero di chiave.  Se è così, allora anche la chiave è maggiore di qualsiasi numero a sinistra del centro e possiamo chiamare di nuovo la funzione binaria, solo che ora il nostro min = punto medio + 1. Se risulta che chiave < punto medio, possiamo scartare quel numero stesso e tutti i numeri, che giacciono alla sua destra. E chiamiamo una ricerca binaria attraverso l'array dal numero min fino al valore (punto medio – 1).
Se è così, allora anche la chiave è maggiore di qualsiasi numero a sinistra del centro e possiamo chiamare di nuovo la funzione binaria, solo che ora il nostro min = punto medio + 1. Se risulta che chiave < punto medio, possiamo scartare quel numero stesso e tutti i numeri, che giacciono alla sua destra. E chiamiamo una ricerca binaria attraverso l'array dal numero min fino al valore (punto medio – 1).  Infine, il terzo ramo: se il valore nel punto medio non è né maggiore né minore della chiave, non ha altra scelta che essere il numero desiderato. In questo caso, lo restituiamo e terminiamo il programma.
Infine, il terzo ramo: se il valore nel punto medio non è né maggiore né minore della chiave, non ha altra scelta che essere il numero desiderato. In questo caso, lo restituiamo e terminiamo il programma.  Infine, può succedere che il numero che stai cercando non sia affatto nell'array. Per tenere conto di questo caso, eseguiamo il seguente controllo:
Infine, può succedere che il numero che stai cercando non sia affatto nell'array. Per tenere conto di questo caso, eseguiamo il seguente controllo:  E restituiamo (-1) per indicare che non abbiamo trovato nulla. Sai già che la ricerca binaria richiede l'ordinamento dell'array. Pertanto, se abbiamo un array non ordinato in cui dobbiamo trovare un determinato elemento, abbiamo due opzioni:
E restituiamo (-1) per indicare che non abbiamo trovato nulla. Sai già che la ricerca binaria richiede l'ordinamento dell'array. Pertanto, se abbiamo un array non ordinato in cui dobbiamo trovare un determinato elemento, abbiamo due opzioni:
 Attenzione: la radice dell'albero “programmatore”, a differenza di quello reale, è in alto. Ogni cella è chiamata vertice e i vertici sono collegati da bordi. La radice dell'albero è la cella numero 13. Il sottoalbero sinistro del vertice 3 è evidenziato a colori nell'immagine seguente:
Attenzione: la radice dell'albero “programmatore”, a differenza di quello reale, è in alto. Ogni cella è chiamata vertice e i vertici sono collegati da bordi. La radice dell'albero è la cella numero 13. Il sottoalbero sinistro del vertice 3 è evidenziato a colori nell'immagine seguente: 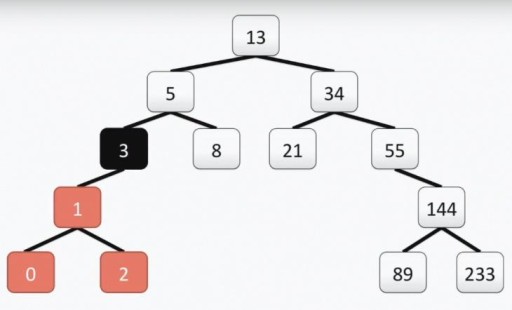 Il nostro albero soddisfa tutti i requisiti per gli alberi binari. Ciò significa che ciascuno dei suoi sottoalberi di sinistra contiene solo valori inferiori o uguali al valore del vertice, mentre il sottoalbero di destra contiene solo valori maggiori o uguali al valore del vertice. Entrambi i sottoalberi sinistro e destro sono essi stessi sottoalberi binari. Il metodo per costruire un albero binario non è l'unico: sotto nell'immagine vedi un'altra opzione per lo stesso insieme di numeri, e in pratica possono essercene molti.
Il nostro albero soddisfa tutti i requisiti per gli alberi binari. Ciò significa che ciascuno dei suoi sottoalberi di sinistra contiene solo valori inferiori o uguali al valore del vertice, mentre il sottoalbero di destra contiene solo valori maggiori o uguali al valore del vertice. Entrambi i sottoalberi sinistro e destro sono essi stessi sottoalberi binari. Il metodo per costruire un albero binario non è l'unico: sotto nell'immagine vedi un'altra opzione per lo stesso insieme di numeri, e in pratica possono essercene molti.  Questa struttura aiuta ad effettuare la ricerca: troviamo il valore minimo spostandoci ogni volta dall'alto verso sinistra e verso il basso.
Questa struttura aiuta ad effettuare la ricerca: troviamo il valore minimo spostandoci ogni volta dall'alto verso sinistra e verso il basso. 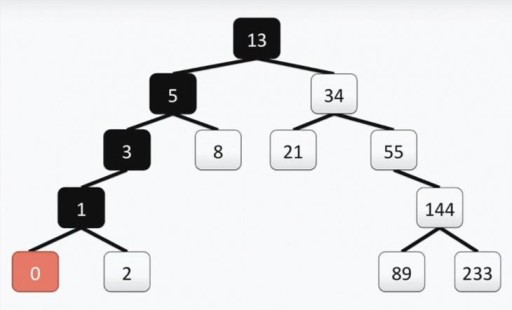 Se hai bisogno di trovare il numero massimo, andiamo dall'alto verso il basso e verso destra. Anche trovare un numero che non sia il minimo o il massimo è abbastanza semplice. Scendiamo dalla radice verso sinistra o verso destra, a seconda che il nostro vertice sia più grande o più piccolo di quello che cerchiamo. Quindi, se dobbiamo trovare il numero 89, seguiamo questo percorso:
Se hai bisogno di trovare il numero massimo, andiamo dall'alto verso il basso e verso destra. Anche trovare un numero che non sia il minimo o il massimo è abbastanza semplice. Scendiamo dalla radice verso sinistra o verso destra, a seconda che il nostro vertice sia più grande o più piccolo di quello che cerchiamo. Quindi, se dobbiamo trovare il numero 89, seguiamo questo percorso:  puoi anche visualizzare i numeri in ordine. Se ad esempio dobbiamo visualizzare tutti i numeri in ordine crescente, prendiamo il sottoalbero di sinistra e, partendo dal vertice più a sinistra, saliamo. Anche aggiungere qualcosa all'albero è facile. La cosa principale da ricordare è la struttura. Diciamo che dobbiamo aggiungere all'albero il valore 7. Andiamo alla radice e controlliamo. Il numero 7 < 13, quindi andiamo a sinistra. Qui vediamo 5 e andiamo a destra, poiché 7 > 5. Inoltre, poiché 7 > 8 e 8 non ha discendenti, costruiamo un ramo da 8 a sinistra e gli attacchiamo 7. Puoi anche rimuovere i vertici
puoi anche visualizzare i numeri in ordine. Se ad esempio dobbiamo visualizzare tutti i numeri in ordine crescente, prendiamo il sottoalbero di sinistra e, partendo dal vertice più a sinistra, saliamo. Anche aggiungere qualcosa all'albero è facile. La cosa principale da ricordare è la struttura. Diciamo che dobbiamo aggiungere all'albero il valore 7. Andiamo alla radice e controlliamo. Il numero 7 < 13, quindi andiamo a sinistra. Qui vediamo 5 e andiamo a destra, poiché 7 > 5. Inoltre, poiché 7 > 8 e 8 non ha discendenti, costruiamo un ramo da 8 a sinistra e gli attacchiamo 7. Puoi anche rimuovere i vertici 
 da l'albero, ma questo è un po' più complicato. Esistono tre diversi scenari di eliminazione che dobbiamo considerare.
da l'albero, ma questo è un po' più complicato. Esistono tre diversi scenari di eliminazione che dobbiamo considerare.



 Tutti i numeri verranno semplicemente aggiunti al ramo destro del precedente. Se vogliamo trovare un numero, non avremo altra scelta che seguire semplicemente la catena verso il basso.
Tutti i numeri verranno semplicemente aggiunti al ramo destro del precedente. Se vogliamo trovare un numero, non avremo altra scelta che seguire semplicemente la catena verso il basso.  Non è meglio della ricerca lineare. Esistono altre strutture dati più complesse. Ma per ora non li prenderemo in considerazione. Diciamo solo che per risolvere il problema della costruzione di un albero da un elenco ordinato, è possibile mescolare in modo casuale i dati di input.
Non è meglio della ricerca lineare. Esistono altre strutture dati più complesse. Ma per ora non li prenderemo in considerazione. Diciamo solo che per risolvere il problema della costruzione di un albero da un elenco ordinato, è possibile mescolare in modo casuale i dati di input.
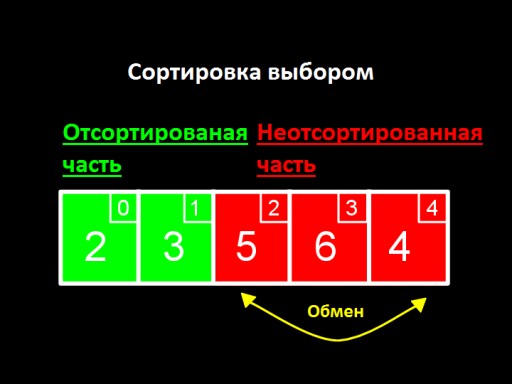 L'idea principale è dividere la nostra lista in due parti, ordinate e non ordinate. Ad ogni passo dell'algoritmo, un nuovo numero viene spostato dalla parte non ordinata a quella ordinata, e così via finché tutti i numeri non si trovano nella parte ordinata.
L'idea principale è dividere la nostra lista in due parti, ordinate e non ordinate. Ad ogni passo dell'algoritmo, un nuovo numero viene spostato dalla parte non ordinata a quella ordinata, e così via finché tutti i numeri non si trovano nella parte ordinata.
 Troviamo il numero minimo nella parte non ordinata dell'array (ovvero, in questo passaggio, nell'intero array). Questo numero è 2. Ora lo cambiamo con il primo tra quelli non ordinati e lo mettiamo alla fine dell'array ordinato (in questo passaggio - al primo posto). In questo passaggio, questo è il primo numero nell'array, ovvero 3.
Troviamo il numero minimo nella parte non ordinata dell'array (ovvero, in questo passaggio, nell'intero array). Questo numero è 2. Ora lo cambiamo con il primo tra quelli non ordinati e lo mettiamo alla fine dell'array ordinato (in questo passaggio - al primo posto). In questo passaggio, questo è il primo numero nell'array, ovvero 3.  Passaggio due. Non guardiamo il numero 2; è già nel sottoarray ordinato. Iniziamo a cercare il minimo, partendo dal secondo elemento, questo è 5. Facciamo attenzione che 3 sia il minimo tra gli non ordinati, 5 sia il primo tra i non ordinati. Li scambiamo e aggiungiamo 3 al sottoarray ordinato.
Passaggio due. Non guardiamo il numero 2; è già nel sottoarray ordinato. Iniziamo a cercare il minimo, partendo dal secondo elemento, questo è 5. Facciamo attenzione che 3 sia il minimo tra gli non ordinati, 5 sia il primo tra i non ordinati. Li scambiamo e aggiungiamo 3 al sottoarray ordinato.  Nel terzo passaggio , vediamo che il numero più piccolo nel sottoarray non ordinato è 4. Lo cambiamo con il primo numero tra quelli non ordinati - 5.
Nel terzo passaggio , vediamo che il numero più piccolo nel sottoarray non ordinato è 4. Lo cambiamo con il primo numero tra quelli non ordinati - 5.  Nel quarto passaggio, troviamo che nel array non ordinato il numero più piccolo è 5. Lo cambiamo da 6 e lo aggiungiamo al sottoarray ordinato.
Nel quarto passaggio, troviamo che nel array non ordinato il numero più piccolo è 5. Lo cambiamo da 6 e lo aggiungiamo al sottoarray ordinato. 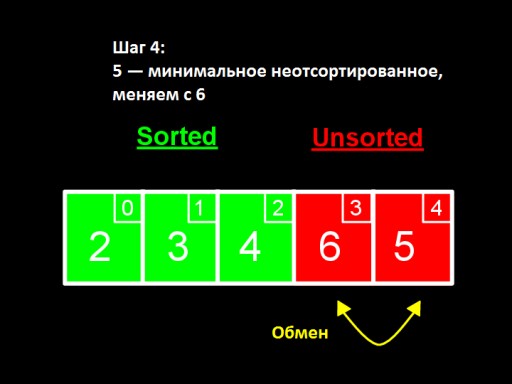 Quando tra quelli non ordinati rimane solo un numero (il più grande), significa che l'intero array è ordinato!
Quando tra quelli non ordinati rimane solo un numero (il più grande), significa che l'intero array è ordinato! 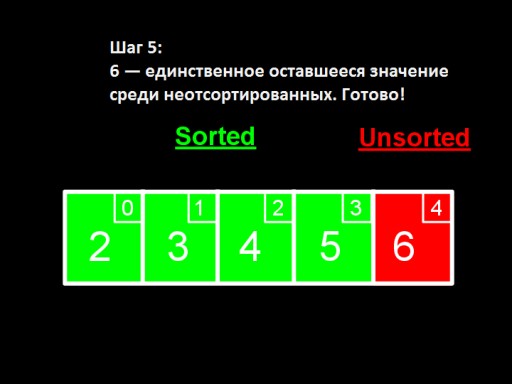 Questo è l'aspetto dell'implementazione dell'array nel codice. Prova a farlo da solo.
Questo è l'aspetto dell'implementazione dell'array nel codice. Prova a farlo da solo.  Sia nel migliore che nel peggiore dei casi, per trovare l'elemento minimo non ordinato, dobbiamo confrontare ciascun elemento con ciascun elemento dell'array non ordinato, e lo faremo ad ogni iterazione. Ma non abbiamo bisogno di visualizzare l'intero elenco, ma solo la parte non ordinata. Questo cambia la velocità dell’algoritmo? Nel primo passaggio, per un array di 5 elementi, facciamo 4 confronti, nel secondo - 3, nel terzo - 2. Per ottenere il numero di confronti, dobbiamo sommare tutti questi numeri. Otteniamo la somma.
Sia nel migliore che nel peggiore dei casi, per trovare l'elemento minimo non ordinato, dobbiamo confrontare ciascun elemento con ciascun elemento dell'array non ordinato, e lo faremo ad ogni iterazione. Ma non abbiamo bisogno di visualizzare l'intero elenco, ma solo la parte non ordinata. Questo cambia la velocità dell’algoritmo? Nel primo passaggio, per un array di 5 elementi, facciamo 4 confronti, nel secondo - 3, nel terzo - 2. Per ottenere il numero di confronti, dobbiamo sommare tutti questi numeri. Otteniamo la somma.  Pertanto, la velocità attesa dell'algoritmo nel caso migliore e in quello peggiore è Θ(n 2 ). Non è l'algoritmo più efficiente! Tuttavia, per scopi didattici e per piccoli set di dati è abbastanza applicabile.
Pertanto, la velocità attesa dell'algoritmo nel caso migliore e in quello peggiore è Θ(n 2 ). Non è l'algoritmo più efficiente! Tuttavia, per scopi didattici e per piccoli set di dati è abbastanza applicabile.
 Passaggio 1: esaminare l'array. L'algoritmo inizia con i primi due elementi, 8 e 6, e controlla se sono nell'ordine corretto. 8 > 6, quindi li invertiamo. Successivamente guardiamo il secondo e il terzo elemento, ora questi sono 8 e 4. Per gli stessi motivi, li scambiamo. Per la terza volta confrontiamo 8 e 2. In totale facciamo tre scambi (8, 6), (8, 4), (8, 2). Il valore 8 "fluttua" alla fine dell'elenco nella posizione corretta.
Passaggio 1: esaminare l'array. L'algoritmo inizia con i primi due elementi, 8 e 6, e controlla se sono nell'ordine corretto. 8 > 6, quindi li invertiamo. Successivamente guardiamo il secondo e il terzo elemento, ora questi sono 8 e 4. Per gli stessi motivi, li scambiamo. Per la terza volta confrontiamo 8 e 2. In totale facciamo tre scambi (8, 6), (8, 4), (8, 2). Il valore 8 "fluttua" alla fine dell'elenco nella posizione corretta.  Passaggio 2: scambiare (6,4) e (6,2). 6 è ora in penultima posizione e non c'è bisogno di confrontarlo con la “coda” già ordinata della lista.
Passaggio 2: scambiare (6,4) e (6,2). 6 è ora in penultima posizione e non c'è bisogno di confrontarlo con la “coda” già ordinata della lista.  Passaggio 3: scambia 4 e 2. I quattro "galleggiano" al posto giusto.
Passaggio 3: scambia 4 e 2. I quattro "galleggiano" al posto giusto.  Passaggio 4: esaminiamo l'array, ma non abbiamo nulla da modificare. Ciò segnala che l'array è completamente ordinato.
Passaggio 4: esaminiamo l'array, ma non abbiamo nulla da modificare. Ciò segnala che l'array è completamente ordinato. 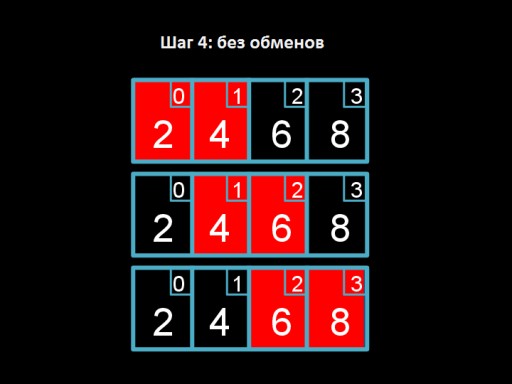 E questo è il codice dell'algoritmo. Prova a implementarlo in C!
E questo è il codice dell'algoritmo. Prova a implementarlo in C!  Il bubble sort richiede un tempo O(n 2 ) nel caso peggiore (tutti i numeri sono sbagliati), poiché dobbiamo fare n passi ad ogni iterazione, di cui ci sono anche n. Infatti, come nel caso dell'algoritmo di ordinamento per selezione, il tempo sarà leggermente inferiore (n 2 /2 – n/2), ma questo può essere trascurato. Nel migliore dei casi (se tutti gli elementi sono già presenti), possiamo farlo in n passaggi, ovvero Ω(n), poiché dovremo solo scorrere l'array una volta e assicurarci che tutti gli elementi siano al loro posto (cioè anche n-1 elementi).
Il bubble sort richiede un tempo O(n 2 ) nel caso peggiore (tutti i numeri sono sbagliati), poiché dobbiamo fare n passi ad ogni iterazione, di cui ci sono anche n. Infatti, come nel caso dell'algoritmo di ordinamento per selezione, il tempo sarà leggermente inferiore (n 2 /2 – n/2), ma questo può essere trascurato. Nel migliore dei casi (se tutti gli elementi sono già presenti), possiamo farlo in n passaggi, ovvero Ω(n), poiché dovremo solo scorrere l'array una volta e assicurarci che tutti gli elementi siano al loro posto (cioè anche n-1 elementi).
 Diamo un'occhiata a come funziona l'ordinamento per inserzione utilizzando l'esempio seguente. Prima di iniziare, tutti gli elementi sono considerati non ordinati.
Diamo un'occhiata a come funziona l'ordinamento per inserzione utilizzando l'esempio seguente. Prima di iniziare, tutti gli elementi sono considerati non ordinati.  Passaggio 1: prendi il primo valore non ordinato (3) e inseriscilo nel sottoarray ordinato. A questo punto, l'intero sottoarray ordinato, il suo inizio e la sua fine saranno proprio questi tre.
Passaggio 1: prendi il primo valore non ordinato (3) e inseriscilo nel sottoarray ordinato. A questo punto, l'intero sottoarray ordinato, il suo inizio e la sua fine saranno proprio questi tre.  Passaggio 2: poiché 3 > 5, inseriremo 5 nel sottoarray ordinato a destra di 3.
Passaggio 2: poiché 3 > 5, inseriremo 5 nel sottoarray ordinato a destra di 3.  Passaggio 3: ora lavoriamo sull'inserimento del numero 2 nel nostro array ordinato. Confrontiamo 2 con valori da destra a sinistra per trovare la posizione corretta. Dato che 2 < 5 e 2 < 3 abbiamo raggiunto l'inizio del sottoarray ordinato. Dobbiamo quindi inserire 2 a sinistra di 3. Per fare ciò, sposta 3 e 5 a destra in modo che ci sia spazio per il 2 e inseriscilo all'inizio dell'array.
Passaggio 3: ora lavoriamo sull'inserimento del numero 2 nel nostro array ordinato. Confrontiamo 2 con valori da destra a sinistra per trovare la posizione corretta. Dato che 2 < 5 e 2 < 3 abbiamo raggiunto l'inizio del sottoarray ordinato. Dobbiamo quindi inserire 2 a sinistra di 3. Per fare ciò, sposta 3 e 5 a destra in modo che ci sia spazio per il 2 e inseriscilo all'inizio dell'array.  Passaggio 4. Siamo fortunati: 6 > 5, quindi possiamo inserire quel numero subito dopo il numero 5.
Passaggio 4. Siamo fortunati: 6 > 5, quindi possiamo inserire quel numero subito dopo il numero 5.  Passaggio 5. 4 < 6 e 4 < 5, ma 4 > 3. Pertanto, sappiamo che 4 deve essere inserito per a destra di 3. Ancora una volta, siamo costretti a spostare 5 e 6 a destra per creare uno spazio per 4.
Passaggio 5. 4 < 6 e 4 < 5, ma 4 > 3. Pertanto, sappiamo che 4 deve essere inserito per a destra di 3. Ancora una volta, siamo costretti a spostare 5 e 6 a destra per creare uno spazio per 4.  Fatto! Algoritmo generalizzato: prendi ogni elemento non ordinato di n e confrontalo con i valori nel sottoarray ordinato da destra a sinistra finché non troviamo una posizione adatta per n (ovvero nel momento in cui troviamo il primo numero inferiore a n) . Quindi spostiamo tutti gli elementi ordinati che si trovano a destra di questo numero a destra per fare spazio al nostro n, e lo inseriamo lì, espandendo così la parte ordinata dell'array. Per ogni elemento non ordinato n è necessario:
Fatto! Algoritmo generalizzato: prendi ogni elemento non ordinato di n e confrontalo con i valori nel sottoarray ordinato da destra a sinistra finché non troviamo una posizione adatta per n (ovvero nel momento in cui troviamo il primo numero inferiore a n) . Quindi spostiamo tutti gli elementi ordinati che si trovano a destra di questo numero a destra per fare spazio al nostro n, e lo inseriamo lì, espandendo così la parte ordinata dell'array. Per ogni elemento non ordinato n è necessario:

 Diciamo che abbiamo n elementi da ordinare. Se n < 2, terminiamo l'ordinamento, altrimenti ordiniamo separatamente le parti sinistra e destra dell'array e poi le combiniamo. Ordiniamo l'array:
Diciamo che abbiamo n elementi da ordinare. Se n < 2, terminiamo l'ordinamento, altrimenti ordiniamo separatamente le parti sinistra e destra dell'array e poi le combiniamo. Ordiniamo l'array:  dividiamolo in due parti e continuiamo a dividere finché non otteniamo sottoarray di dimensione 1, che ovviamente sono ordinati.
dividiamolo in due parti e continuiamo a dividere finché non otteniamo sottoarray di dimensione 1, che ovviamente sono ordinati.  Due sottoarray ordinati possono essere uniti in tempo O(n) utilizzando un semplice algoritmo: rimuovere il numero più piccolo all'inizio di ciascun sottoarray e inserirlo nell'array unito. Ripeti fino a quando tutti gli elementi non saranno scomparsi.
Due sottoarray ordinati possono essere uniti in tempo O(n) utilizzando un semplice algoritmo: rimuovere il numero più piccolo all'inizio di ciascun sottoarray e inserirlo nell'array unito. Ripeti fino a quando tutti gli elementi non saranno scomparsi. 
 Il merge sort richiede tempo O(nlog n) per tutti i casi. Mentre dividiamo gli array a metà ad ogni livello di ricorsione otteniamo il log n. Quindi, l'unione dei sottoarray richiede solo n confronti. Pertanto O(nlog n). Il caso migliore e quello peggiore per il merge sort sono gli stessi, il tempo di esecuzione previsto dell'algoritmo = Θ(nlog n). Questo algoritmo è il più efficace tra quelli considerati.
Il merge sort richiede tempo O(nlog n) per tutti i casi. Mentre dividiamo gli array a metà ad ogni livello di ricorsione otteniamo il log n. Quindi, l'unione dei sottoarray richiede solo n confronti. Pertanto O(nlog n). Il caso migliore e quello peggiore per il merge sort sono gli stessi, il tempo di esecuzione previsto dell'algoritmo = Θ(nlog n). Questo algoritmo è il più efficace tra quelli considerati. 

GO TO FULL VERSION