Il moderno mondo dello sviluppo è pieno di varie specifiche progettate per semplificare la vita. Conoscendo gli strumenti, puoi scegliere quello giusto. Senza saperlo, puoi renderti la vita più difficile. Questa revisione solleverà il velo di segretezza sul concetto di JPA - Java Persistence API. Spero che dopo aver letto vorrai immergerti ancora più a fondo in questo mondo misterioso.
introduzione
Come sappiamo, uno dei compiti principali dei programmi è l'archiviazione e l'elaborazione dei dati. Ai vecchi tempi, le persone semplicemente archiviavano i dati in file. Ma non appena è necessario l'accesso simultaneo in lettura e modifica, quando c'è un carico (cioè arrivano più richieste contemporaneamente), archiviare i dati semplicemente nei file diventa un problema. Per maggiori informazioni su quali problemi risolvono i database e come, ti consiglio di leggere l’articolo “
Come sono strutturati i database ”. Ciò significa che decidiamo di archiviare i nostri dati in un database. Per molto tempo Java è stato in grado di lavorare con i database utilizzando l'API JDBC (The Java Database Connectivity). Puoi leggere ulteriori informazioni su JDBC qui: "
JDBC o dove tutto inizia ". Ma il tempo passava e gli sviluppatori ogni volta si trovavano di fronte alla necessità di scrivere lo stesso tipo e codice di "manutenzione" non necessario (il cosiddetto codice Boilerplate) per operazioni banali sul salvataggio di oggetti Java nel database e viceversa, creando oggetti Java utilizzando i dati dal Banca dati. E poi, per risolvere questi problemi, è nato un concetto come ORM.
ORM - Object-Relational Mapping o tradotto in russo mappatura relazionale di oggetti. È una tecnologia di programmazione che collega i database con i concetti dei linguaggi di programmazione orientati agli oggetti. Per semplificare, ORM è la connessione tra oggetti Java e record in un database:
![JPA: Introduzione alla tecnologia - 2]()
ORM è essenzialmente il concetto secondo cui un oggetto Java può essere rappresentato come dati in un database (e viceversa). È stato incarnato sotto forma di specifica JPA: Java Persistence API. La specifica è già una descrizione dell'API Java che esprime questo concetto. Le specifiche ci dicono quali strumenti dobbiamo essere forniti (cioè con quali interfacce possiamo lavorare) per poter lavorare secondo il concetto ORM. E come utilizzare questi fondi. La specifica non descrive l'implementazione degli strumenti. Ciò rende possibile utilizzare diverse implementazioni per una specifica. Puoi semplificarlo e dire che una specifica è una descrizione dell'API. Il testo della specifica JPA è reperibile sul sito web di Oracle: "
JSR 338: JavaTM Persistence API ". Pertanto, per utilizzare JPA, abbiamo bisogno di un'implementazione con cui utilizzeremo la tecnologia. Le implementazioni JPA sono anche chiamate provider JPA. Una delle implementazioni JPA più importanti è
Hibernate . Pertanto, propongo di considerarlo.
Creazione di un progetto
Poiché JPA riguarda Java, avremo bisogno di un progetto Java. Potremmo creare manualmente noi stessi la struttura delle directory e aggiungere noi stessi le librerie necessarie. Ma è molto più comodo e corretto utilizzare sistemi per automatizzare l'assemblaggio dei progetti (ovvero, in sostanza, questo è solo un programma che gestirà l'assemblaggio dei progetti per noi. Crea directory, aggiungi le librerie necessarie al classpath, ecc. .). Uno di questi sistemi è Gradle. Puoi leggere ulteriori informazioni su Gradle qui: "
Una breve introduzione a Gradle ". Come sappiamo, la funzionalità Gradle (ovvero le cose che può fare) viene implementata utilizzando vari plugin Gradle. Usiamo Gradle e il plugin "
Gradle Build Init Plugin ". Eseguiamo il comando:
gradle init --type java-application
Gradle creerà per noi la struttura di directory necessaria e creerà una descrizione dichiarativa di base del progetto nello script di build
build.gradle. Quindi, abbiamo un'applicazione. Dobbiamo pensare a cosa vogliamo descrivere o modellare con la nostra applicazione. Usiamo qualche strumento di modellazione, ad esempio:
app.quickdatabasediagrams.com ![JPA: Introduzione alla tecnologia - 4]()
Qui vale la pena dire che quello che abbiamo descritto è il nostro “modello di dominio”. Un dominio è un “ambito tematico”. In generale, dominio è “possesso” in latino. Nel Medioevo si chiamavano così le zone possedute da re o feudatari. E in francese è diventata la parola "domaine", che si traduce semplicemente come "area". Così abbiamo descritto il nostro “modello di dominio” = “modello di soggetto”. Ogni elemento di questo modello è una sorta di “essenza”, qualcosa della vita reale. Nel nostro caso si tratta di entità: Categoria (
Category), Oggetto (
Topic). Creiamo un pacchetto separato per le entità, ad esempio con il nome model. E aggiungiamo lì le classi Java che descrivono le entità. Nel codice Java, tali entità sono dei
POJO regolari , che potrebbero assomigliare a questo:
public class Category {
private Long id;
private String title;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
Copiamo il contenuto della classe e creiamo una classe per analogia
Topic. Differirà solo per ciò che sa della categoria a cui appartiene. Pertanto, aggiungiamo
Topicalla classe un campo di categoria e i metodi per lavorarci:
private Category category;
public Category getCategory() {
return category;
}
public void setCategory(Category category) {
this.category = category;
}
Ora abbiamo un'applicazione Java che ha il proprio modello di dominio. Ora è il momento di iniziare a connettersi al progetto JPA.
Aggiunta dell'APP
Quindi, come ricordiamo, JPA significa che salveremo qualcosa nel database. Pertanto, abbiamo bisogno di un database. Per utilizzare una connessione al database nel nostro progetto, dobbiamo aggiungere una libreria di dipendenze per connetterci al database. Come ricordiamo, abbiamo utilizzato Gradle, che ha creato per noi uno script di build
build.gradle. In esso descriveremo le dipendenze di cui il nostro progetto ha bisogno. Le dipendenze sono quelle librerie senza le quali il nostro codice non può funzionare. Iniziamo con una descrizione della dipendenza dalla connessione al database. Lo facciamo nello stesso modo in cui lo faremmo se lavorassimo solo con JDBC:
dependencies {
implementation 'com.h2database:h2:1.4.199'
Ora abbiamo un database. Ora possiamo aggiungere un livello alla nostra applicazione che è responsabile della mappatura dei nostri oggetti Java nei concetti di database (da Java a SQL). Come ricordiamo, utilizzeremo un'implementazione della specifica JPA chiamata Hibernate per questo:
dependencies {
implementation 'com.h2database:h2:1.4.199'
implementation 'org.hibernate:hibernate-core:5.4.2.Final'
Ora dobbiamo configurare JPA. Se leggiamo le specifiche e la sezione "8.1 Unità di persistenza", sapremo che un'Unità di persistenza è una sorta di combinazione di configurazioni, metadati ed entità. E affinché JPA funzioni, è necessario descrivere almeno un'unità di persistenza nel file di configurazione, chiamato
persistence.xml. La sua posizione è descritta nel capitolo delle specifiche "8.2 Imballaggio dell'unità di persistenza". Secondo questa sezione, se disponiamo di un ambiente Java SE, dobbiamo inserirlo nella radice della directory META-INF.
Copiamo il contenuto dall'esempio fornito nelle specifiche JPA nel
8.2.1 persistence.xml filecapitolo " ":
<persistence>
<persistence-unit name="JavaRush">
<description>Persistence Unit For test</description>
<class>hibernate.model.Category</class>
<class>hibernate.model.Topic</class>
</persistence-unit>
</persistence>
Ma questo non basta. Dobbiamo dire chi è il nostro fornitore JPA, ad es. colui che implementa la specifica JPA:
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
Ora aggiungiamo le impostazioni (
properties). Alcune di esse (che iniziano con
javax.persistence) sono configurazioni JPA standard e sono descritte nelle specifiche JPA nella sezione "Proprietà 8.2.1.9". Alcune configurazioni sono specifiche del provider (nel nostro caso, influenzano Hibernate come provider Jpa. Il nostro blocco delle impostazioni sarà simile a questo:
<properties>
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE" />
<property name="javax.persistence.jdbc.user" value="sa" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
Ora abbiamo una configurazione compatibile con JPA
persistence.xml, c'è un provider JPA Hibernate e c'è un database H2 e ci sono anche 2 classi che sono il nostro modello di dominio. Facciamo finalmente in modo che tutto funzioni. Nel catalogo
/test/java, il nostro Gradle ha gentilmente generato un modello per i test unitari e lo ha chiamato AppTest. Usiamolo. Come affermato nel capitolo "7.1 Contesti di persistenza" delle specifiche JPA, le entità nel mondo JPA vivono in uno spazio chiamato Contesto di persistenza. Ma non lavoriamo direttamente con il contesto di persistenza. Per questo usiamo
Entity Managero "entity manager". È lui che conosce il contesto e quali entità lo abitano. Interagiamo con
Entity Manager'om. Allora non resta che capire da dove possiamo ricavare questo
Entity Manager? Secondo il capitolo "7.2.2 Come ottenere un gestore di entità gestito dall'applicazione" delle specifiche JPA, dobbiamo utilizzare
EntityManagerFactory. Armiamoci quindi delle specifiche JPA e prendiamo un esempio dal capitolo “7.3.2 Come ottenere una Entity Manager Factory in un ambiente Java SE” e formattiamolo sotto forma di un semplice Unit test:
@Test
public void shouldStartHibernate() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
EntityManager entityManager = emf.createEntityManager();
}
Questo test mostrerà già l'errore "Versione XSD JPA persistence.xml non riconosciuta". Il motivo è che
persistence.xmlè necessario specificare correttamente lo schema da utilizzare, come indicato nella specifica JPA nella sezione "8.3 persistence.xml Schema":
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
Inoltre, l'ordine degli elementi è importante. Pertanto,
providerdeve essere specificato prima di elencare le classi. Successivamente, il test verrà eseguito con successo. Abbiamo completato la connessione diretta all'APP. Prima di andare avanti, pensiamo ai test rimanenti. Ciascuno dei nostri test richiederà
EntityManager. Assicuriamoci che ogni test abbia il proprio
EntityManagerall'inizio dell'esecuzione. Inoltre, vogliamo che il database sia nuovo ogni volta. Poiché utilizziamo
inmemoryl'opzione, è sufficiente chiudere
EntityManagerFactory. La creazione
Factoryè un’operazione costosa. Ma per i test è giustificato. JUnit consente di specificare i metodi che verranno eseguiti prima (Before) e dopo (After) l'esecuzione di ciascun test:
public class AppTest {
private EntityManager em;
@Before
public void init() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
em = emf.createEntityManager();
}
@After
public void close() {
em.getEntityManagerFactory().close();
em.close();
}
Ora, prima di eseguire qualsiasi test, ne verrà creato uno nuovo
EntityManagerFactory, che comporterà la creazione di un nuovo database, perché
hibernate.hbm2ddl.autoha il significato
create. E dalla nuova fabbrica ne avremo una nuova
EntityManager.
Entità
Come ricordiamo, abbiamo precedentemente creato classi che descrivono il nostro modello di dominio. Abbiamo già detto che queste sono le nostre “essenze”. Questa è l'Entità che gestiremo utilizzando
EntityManager. Scriviamo un semplice test per salvare l'essenza di una categoria:
@Test
public void shouldPersistCategory() {
Category cat = new Category();
cat.setTitle("new category");
em.persist(cat);
}
Ma questo test non funzionerà subito, perché... riceveremo diversi errori che ci aiuteranno a capire cosa sono le entità:
-
Unknown entity: hibernate.model.Category
Perché Hibernate non capisce di cosa Categorysi tratta entity? Il fatto è che le entità devono essere descritte secondo lo standard JPA.
Le classi di entità devono essere annotate con l'annotation @Entity, come indicato nel capitolo "2.1 La classe di entità" delle specifiche JPA.
-
No identifier specified for entity: hibernate.model.Category
Le entità devono avere un identificatore univoco che può essere utilizzato per distinguere un record da un altro.
Secondo il capitolo "2.4 Chiavi primarie e identità dell'entità" delle specifiche JPA, "Ogni entità deve avere una chiave primaria", ovvero Ogni entità deve avere una "chiave primaria". Tale chiave primaria deve essere specificata dall'annotazione@Id
-
ids for this class must be manually assigned before calling save()
L'ID deve provenire da qualche parte. Può essere specificato manualmente oppure ottenuto automaticamente.
Pertanto, come indicato nei capitoli "11.2.3.3 GeneratedValue" e "11.1.20 GeneratedValue Annotation", possiamo specificare l'annotazione @GeneratedValue.
Quindi affinché la classe categoria diventi un'entità dobbiamo apportare le seguenti modifiche:
@Entity
public class Category {
@Id
@GeneratedValue
private Long id;
Inoltre, l'annotazione
@Idindica quale utilizzare
Access Type. Puoi leggere ulteriori informazioni sul tipo di accesso nelle specifiche JPA, nella sezione "2.3 Tipo di accesso". Per dirla in breve, perché... abbiamo specificato
@Idsopra il campo (
field), quindi il tipo di accesso sarà quello predefinito
field-based, non
property-based. Pertanto, il provider JPA leggerà e memorizzerà i valori direttamente dai campi. Se posizionassimo
@Idsopra il getter,
property-basedverrebbe utilizzato l'accesso, ad es. tramite getter e setter. Durante l'esecuzione del test vediamo anche quali richieste vengono inviate al database (grazie all'opzione
hibernate.show_sql). Ma durante il salvataggio, non vediamo nessuno
insert. Si scopre che in realtà non abbiamo salvato nulla? JPA consente di sincronizzare il contesto di persistenza e il database utilizzando il metodo
flush:
entityManager.flush();
Ma se lo eseguiamo ora, otterremo un errore:
nessuna transazione in corso . E ora è il momento di scoprire come l’APP utilizza le transazioni.
Transazioni dell'APP
Come ricordiamo, JPA si basa sul concetto di contesto di persistenza. Questo è il luogo in cui vivono le entità. E gestiamo le entità attraverso
EntityManager. Quando eseguiamo il comando
persist, inseriamo l'entità nel contesto. Più precisamente, vi diciamo
EntityManagerche è necessario farlo. Ma questo contesto è solo un'area di stoccaggio. A volte viene anche chiamata "cache di primo livello". Ma deve essere connesso al database. Il comando
flush, che in precedenza non era riuscito con un errore, sincronizza i dati dal contesto di persistenza con il database. Ma ciò richiede un trasporto e questo trasporto è una transazione. Le transazioni nell'APP sono descritte nella sezione "7.5 Controllo delle transazioni" delle specifiche. Esiste un'API speciale per l'utilizzo delle transazioni in JPA:
entityManager.getTransaction().begin();
entityManager.getTransaction().commit();
Dobbiamo aggiungere la gestione delle transazioni al nostro codice, che viene eseguito prima e dopo i test:
@Before
public void init() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "JavaRush" );
em = emf.createEntityManager();
em.getTransaction().begin();
}
@After
public void close() {
if (em.getTransaction().isActive()) {
em.getTransaction().commit();
}
em.getEntityManagerFactory().close();
em.close();
}
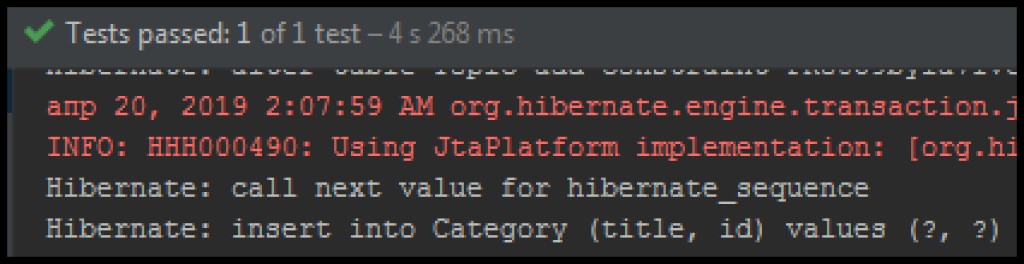
Dopo l'aggiunta, vedremo nel log di inserimento un'espressione in SQL che prima non c'era:
Le modifiche accumulate nella
EntityManagertransazione sono state confermate (confermate e salvate) nel database. Proviamo ora a ritrovare la nostra essenza. Creiamo un test per cercare un'entità in base al suo ID:
@Test
public void shouldFindCategory() {
Category cat = new Category();
cat.setTitle("test");
em.persist(cat);
Category result = em.find(Category.class, 1L);
assertNotNull(result);
}
In questo caso riceveremo l'entità che abbiamo salvato in precedenza, ma non vedremo le query SELECT nel log. E tutto si basa su ciò che diciamo: "Gestore entità, per favore trovami l'entità Categoria con ID=1." E il gestore entità prima guarda nel suo contesto (usa una sorta di cache), e solo se non lo trova, va a cercare nel database. Vale la pena cambiare l'ID in 2 (non esiste una cosa del genere, abbiamo salvato solo 1 istanza) e vedremo che
SELECTappare la richiesta. Poiché non è stata trovata alcuna entità nel contesto e
EntityManageril database sta cercando di trovare un'entità, esistono diversi comandi che possiamo utilizzare per controllare lo stato di un'entità nel contesto. La transizione di un'entità da uno stato a un altro è chiamata ciclo di vita dell'entità -
lifecycle.
Ciclo di vita dell'entità
Il ciclo di vita delle entità è descritto nelle specifiche JPA nel capitolo "3.2 Ciclo di vita dell'istanza dell'entità". Perché le entità vivono in un contesto e sono controllate da
EntityManager, allora dicono che le entità sono controllate, cioè gestito. Vediamo le fasi della vita di un'entità:
Category cat = new Category();
cat.setTitle("new category");
entityManager.persist(cat);
entityManager.getTransaction().begin();
entityManager.getTransaction().commit();
entityManager.detach(cat);
Category managed = entityManager.merge(cat);
entityManager.remove(managed);
Ed ecco un diagramma per consolidarlo:
Mappatura
In JPA possiamo descrivere le relazioni tra entità tra loro. Ricordiamo che abbiamo già esaminato le relazioni tra le entità tra loro quando abbiamo trattato il nostro modello di dominio. Quindi abbiamo utilizzato la risorsa
quickdatabasediagrams.com :
Stabilire connessioni tra entità è chiamato mappatura o associazione (Association Mappings). I tipi di associazioni che possono essere istituite utilizzando l'APP sono presentati di seguito:
Diamo un'occhiata a un'entità
Topicche descrive un argomento. Cosa possiamo dire dell'atteggiamento
Topicverso
Category? Molti
Topicapparterranno ad una categoria. Pertanto abbiamo bisogno di un'associazione
ManyToOne. Esprimiamo questa relazione in JPA:
@ManyToOne
@JoinColumn(name = "category_id")
private Category category;
Per ricordare quali annotazioni mettere, puoi ricordare che l'ultima parte è responsabile del campo sopra il quale è indicata l'annotazione.
ToOne- istanza specifica.
ToMany- collezioni. Ora la nostra connessione è unidirezionale. Rendiamola una comunicazione bidirezionale. Aggiungiamo alla
Categoryconoscenza di tutti coloro
Topicche sono inclusi in questa categoria. Deve terminare con
ToMany, perché abbiamo una lista
Topic. Cioè, l'atteggiamento “A molti” argomenti. La domanda rimane:
OneToManyovvero
ManyToMany:
Una buona risposta sullo stesso argomento può essere letta qui: "
Spiega la relazione ORM oneToMany, manyToMany come se avessi cinque ". Se una categoria ha una connessione con
ToManyargomenti, allora ognuno di questi argomenti può avere solo una categoria, allora sarà
One, altrimenti
Many. Quindi l'
Categoryelenco di tutti gli argomenti sarà simile a questo:
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name = "topic_id")
private Set<Topic> topics = new HashSet<>();
E non dimentichiamoci di
Categoryscrivere essenzialmente un getter per ottenere un elenco di tutti gli argomenti:
public Set<Topic> getTopics() {
return this.topics;
}
Le relazioni bidirezionali sono una cosa molto difficile da tracciare automaticamente. Pertanto, l'APP trasferisce questa responsabilità allo sviluppatore. Ciò significa per noi che quando stabiliamo una
Topicrelazione di entità con
Category, dobbiamo garantire noi stessi la coerenza dei dati. Questo viene fatto semplicemente:
public void setCategory(Category category) {
category.getTopics().add(this);
this.category = category;
}
Scriviamo un semplice test per verificare:
@Test
public void shouldPersistCategoryAndTopics() {
Category cat = new Category();
cat.setTitle("test");
Topic topic = new Topic();
topic.setTitle("topic");
topic.setCategory(cat);
em.persist(cat);
}
La mappatura è un argomento completamente separato. Lo scopo di questa revisione è comprendere i mezzi con cui ciò viene raggiunto. Puoi leggere ulteriori informazioni sulla mappatura qui:
JPQL
JPA introduce uno strumento interessante: le query nel Java Persistence Query Language. Questo linguaggio è simile a SQL, ma utilizza il modello a oggetti Java anziché le tabelle SQL. Diamo un'occhiata ad un esempio:
@Test
public void shouldPerformQuery() {
Category cat = new Category();
cat.setTitle("query");
em.persist(cat);
Query query = em.createQuery("SELECT c from Category c WHERE c.title = 'query'");
assertNotNull(query.getSingleResult());
}
Come possiamo vedere, nella query abbiamo utilizzato un riferimento ad un'entità
Categorye non ad una tabella. E anche sul campo di questa entità
title. JPQL fornisce molte funzionalità utili e merita un articolo a parte. Maggiori dettagli possono essere trovati nella recensione:
API dei criteri
E infine, vorrei toccare l'API Criteria. JPA introduce uno strumento di creazione di query dinamiche. Esempio di utilizzo dell'API Criteri:
@Test
public void shouldFindWithCriteriaAPI() {
Category cat = new Category();
em.persist(cat);
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Category> query = cb.createQuery(Category.class);
Root<Category> c = query.from(Category.class);
query.select(c);
List<Category> resultList = em.createQuery(query).getResultList();
assertEquals(1, resultList.size());
}
Questo esempio equivale all'esecuzione della richiesta "
SELECT c FROM Category c".
L'API Criteria è uno strumento potente. Puoi leggere di più a riguardo qui:
Conclusione
Come possiamo vedere, JPA fornisce un numero enorme di funzionalità e strumenti. Ognuno di loro richiede esperienza e conoscenza. Anche nell'ambito della revisione dell'APP non è stato possibile menzionare tutto, per non parlare di un'immersione dettagliata. Ma spero che dopo averlo letto sia diventato più chiaro cosa sono ORM e JPA, come funziona e cosa si può fare con esso. Bene, per uno spuntino offro vari materiali:
#Viacheslav
 ORM è essenzialmente il concetto secondo cui un oggetto Java può essere rappresentato come dati in un database (e viceversa). È stato incarnato sotto forma di specifica JPA: Java Persistence API. La specifica è già una descrizione dell'API Java che esprime questo concetto. Le specifiche ci dicono quali strumenti dobbiamo essere forniti (cioè con quali interfacce possiamo lavorare) per poter lavorare secondo il concetto ORM. E come utilizzare questi fondi. La specifica non descrive l'implementazione degli strumenti. Ciò rende possibile utilizzare diverse implementazioni per una specifica. Puoi semplificarlo e dire che una specifica è una descrizione dell'API. Il testo della specifica JPA è reperibile sul sito web di Oracle: " JSR 338: JavaTM Persistence API ". Pertanto, per utilizzare JPA, abbiamo bisogno di un'implementazione con cui utilizzeremo la tecnologia. Le implementazioni JPA sono anche chiamate provider JPA. Una delle implementazioni JPA più importanti è Hibernate . Pertanto, propongo di considerarlo.
ORM è essenzialmente il concetto secondo cui un oggetto Java può essere rappresentato come dati in un database (e viceversa). È stato incarnato sotto forma di specifica JPA: Java Persistence API. La specifica è già una descrizione dell'API Java che esprime questo concetto. Le specifiche ci dicono quali strumenti dobbiamo essere forniti (cioè con quali interfacce possiamo lavorare) per poter lavorare secondo il concetto ORM. E come utilizzare questi fondi. La specifica non descrive l'implementazione degli strumenti. Ciò rende possibile utilizzare diverse implementazioni per una specifica. Puoi semplificarlo e dire che una specifica è una descrizione dell'API. Il testo della specifica JPA è reperibile sul sito web di Oracle: " JSR 338: JavaTM Persistence API ". Pertanto, per utilizzare JPA, abbiamo bisogno di un'implementazione con cui utilizzeremo la tecnologia. Le implementazioni JPA sono anche chiamate provider JPA. Una delle implementazioni JPA più importanti è Hibernate . Pertanto, propongo di considerarlo.

 Qui vale la pena dire che quello che abbiamo descritto è il nostro “modello di dominio”. Un dominio è un “ambito tematico”. In generale, dominio è “possesso” in latino. Nel Medioevo si chiamavano così le zone possedute da re o feudatari. E in francese è diventata la parola "domaine", che si traduce semplicemente come "area". Così abbiamo descritto il nostro “modello di dominio” = “modello di soggetto”. Ogni elemento di questo modello è una sorta di “essenza”, qualcosa della vita reale. Nel nostro caso si tratta di entità: Categoria (
Qui vale la pena dire che quello che abbiamo descritto è il nostro “modello di dominio”. Un dominio è un “ambito tematico”. In generale, dominio è “possesso” in latino. Nel Medioevo si chiamavano così le zone possedute da re o feudatari. E in francese è diventata la parola "domaine", che si traduce semplicemente come "area". Così abbiamo descritto il nostro “modello di dominio” = “modello di soggetto”. Ogni elemento di questo modello è una sorta di “essenza”, qualcosa della vita reale. Nel nostro caso si tratta di entità: Categoria ( 













GO TO FULL VERSION