Никогда не пишите свое решение по кешированию
Еще один способ ускорить работу с базой данных — это кешировать объекты, которые мы уже запрашивали раннее.
Важно! Никогда не пиши свое решение по кешированию. Эта задача имеет столько подводных камней, что тебе и не снилось.
Проблема 1 — сброс кэша. Иногда происходят события, когда нужно удалить объект из кэша или обновить его в нем. Единственный способ сделать это грамотно — пропускать все запросы к базе через движок кэша. Иначе тебе каждый раз придется явно указывать кэшу, какие объекты в нем стоит удалить или обновить.
Проблема 2 — нехватка памяти. Кеширование кажется отличной идеей, пока ты не столкнёшься с тем, что объекты в памяти занимают много места. Тебе нужны дополнительно десятки гигабайт памяти для эффективной работы кэша серверного приложения.
А так как памяти всегда не хватает, то нужна эффективная стратегия удаления объектов из кэша. Это чем-то напоминает сборщик мусора в Java. И как ты помнишь, уже десятки лет лучшие умы изобретают различные способы маркировки объектов по поколениям и т. п.
Проблема 3 — различные стратегии. Как показывает практика, для разных объектов эффективны различные стратегии хранения и обновления в кэше. Эффективная система кэширования не может обойтись одой стратегией для всех объектов.

Проблема 4 — эффективное хранение объектов. Нельзя просто хранить объекты в кэше. Объекты слишком часто содержат ссылки на другие объекты и т. п. Такими темпами тебе не понадобится сборщик мусора: ему просто будет нечего удалять.
Поэтому вместо того, чтобы хранить сами объекты, иногда гораздо эффективнее хранить значения их полей-примитивов. И системы быстрого конструирования объектов по ним.
На выходе ты получишь целую виртуальную СУБД в памяти, которая должна быстро работать и потреблять мало памяти.
Кеширование в базе данных
Кроме кеширования прямо в Java-программе еще часто организовывают кеширование прямо в базе данных.
Там есть четыре больших подхода:
Подход первый — денормализация базы данных. SQL-сервер у себя в памяти хранит данные не так, как они храниться в таблицах.
Когда данные хранятся на диске в таблицах, то очень часто разработчики стараются по максимуму избежать дублирования данных — такой процесс называется нормализацией базы данных. Так вот, для ускорения работы с данными в памяти выполняется обратный процесс — денормализация базы данных. Куча связанных таблиц может храниться уже в объединённом виде — в виде большущих таблиц и т. п.
Второй подход — кэширование запросов. И результатов запросов.
СУБД видит, что очень часто к ней приходят одинаковые или похожие запросы. Тогда она начинает просто кешировать эти запросы и ответы на них. Но при этом нужно четко следить за тем, чтобы из кэша своевременно удалялись строки, которые изменились в базе.
Этот подход может быть очень эффективным при участии человека, который может проанализировать запросы и помочь СУБД понять, как их лучше кэшировать.
Третий подход — база данных в памяти.
Еще один часто используемый подход. Между сервером и СУБД ставится еще одна база, которая хранит все свои данные только в памяти. Ее еще называют In-Memory-DB. Если у тебя много разных серверов обращаются к одной базе данных, то с помощью In-Memory-DB можно организовать кэширование, ориентированное на тип конкретного сервера.
Пример:

Подход 4 — кластер баз данных. Несколько read-only баз.
Еще одно решение — использование кластера: несколько СУБД одного типа содержат идентичные данные. При этом читать данные можно из всех баз, а писать — только в одну. Которая потом синхронизируется с остальными базами.
Это очень хорошее решение, потому что его легко конфигурировать и оно работает на практике. Обычно на один запрос к базе на изменение данных к ней приходит 10-100 запросов на чтение данных.
Виды кеширования в Hibernate
Hibernate поддерживает три уровня кэширования:
- Кеширование на уровне сессии (Session)
- Кеширование на уровне SessionFactory
- Кеширование запросов (и их результатов)
Эту системы можно попробовать представить в виде такого рисунка:
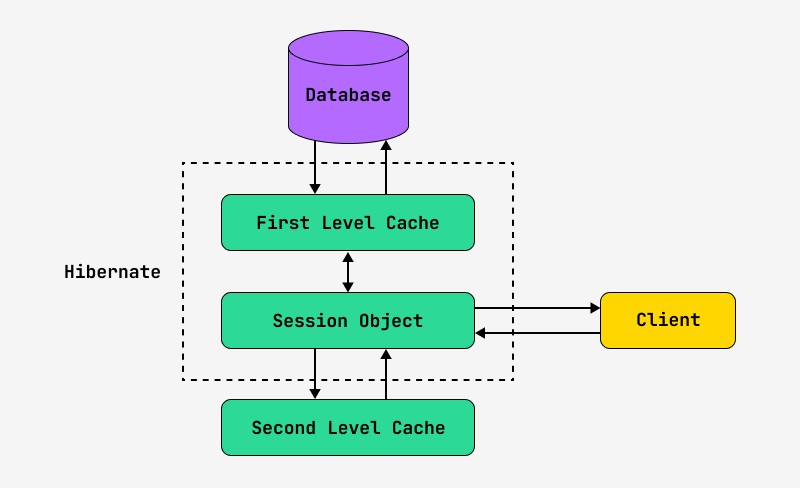
Самый простой вид кеширования (его еще называют кэшем первого уровня) реализован на уровне Hibernate-сессии. Hibernate всегда по умолчанию использует этот кэш и его нельзя отключить.
Давай сразу рассмотрим следующий пример:
Employee director1 = session.get(Employee.class, 4);
Employee director2 = session.get(Employee.class, 4);
assertTrue(director1 == director2);
Может показаться, что тут будет выполнено два запроса в базу, однако это не так. После первого запроса в базу объект Employee будет закэширован. И если ты снова выполнишь запрос объекта в той же сессии, то Hibernate вернет тот же Java-объект.
Тот же объект — это значит, что даже ссылки на объекты будут идентичными. Это реально один и тот же объект.
При использовании методов save(), update(), saveOrUpdate(), load(), get(), list(), iterate() и scroll() всегда будет задействован кэш первого уровня. Собственно, тут нечего больше добавить.
Кэширование второго уровня
Если кэш первого уровня привязан к объекту сессии, то кэш второго уровня привязан к объекту SessionFactory. Что означает, что видимость объектов в этом кэше гораздо шире, чем в кэше первого уровня.
Пример:
Session session = factory.openSession();
Employee director1 = session.get(Employee.class, 4);
session.close();
Session session = factory.openSession();
Employee director2 = session.get(Employee.class, 4);
session.close();
assertTrue(director1 != director2);
assertTrue(director1.equals(director2));
В этом примере будет выполнено два запроса в базу. Hibernate вернет идентичные объекты, но это будет не тот же объект — они будут иметь разные ссылки.
Кэширование второго уровня по умолчанию отключено. Поэтому мы имеем два запроса к базе вместо одного.
Чтобы его включить, нужно в файле hibernate.cfg.xml написать такие строчки:
<property name="hibernate.cache.provider_class" value="net.sf.ehcache.hibernate.SingletEhCacheProvider"/>
<property name="hibernate.cache.use_second_level_cache" value="true"/>
После включения кэширования второго уровня поведение Hibernate немного изменится:
Session session = factory.openSession();
Employee director1 = session.get(Employee.class, 4);
session.close();
Session session = factory.openSession();
Employee director2 = session.get(Employee.class, 4);
session.close();
assertTrue(director1 == director2);
Только после всех этих манипуляций кэш второго уровня будет включен, и в примере выше будет выполнен только один запрос в базу.
ПЕРЕЙДИТЕ В ПОЛНУЮ ВЕРСИЮ