Việc đo tốc độ của một thuật toán theo thời gian thực—tính bằng giây và phút—không phải là điều dễ dàng. Chương trình này có thể chạy chậm hơn chương trình khác không phải do bản thân nó kém hiệu quả mà do hệ điều hành chậm, không tương thích với phần cứng, bộ nhớ máy tính bị chiếm dụng bởi các tiến trình khác... Để đo lường tính hiệu quả của các thuật toán, các khái niệm phổ quát đã được phát minh ra. , bất kể môi trường mà chương trình đang chạy. Độ phức tạp tiệm cận của một bài toán được đo bằng ký hiệu Big O. Giả sử f(x) và g(x) là các hàm xác định trong một lân cận nhất định của x0 và g không triệt tiêu ở đó, khi đó f là “O” lớn hơn g với (x -> x0) nếu tồn tại hằng số C> 0 , với mọi x từ lân cận nào đó của điểm x0, bất đẳng thức đúng Ít |f(x)| <= C |g(x)| nghiêm ngặt hơn một chút: f là “O” lớn hơn g nếu có hằng số C>0, mà với mọi x > x0 f(x) <= C*g(x) Đừng sợ định nghĩa chính thức! Về cơ bản, nó xác định mức tăng tiệm cận của thời gian chạy chương trình khi lượng dữ liệu đầu vào của bạn tăng lên vô tận. Ví dụ: bạn đang so sánh việc sắp xếp một mảng gồm 1000 phần tử và 10 phần tử, và bạn cần hiểu thời gian chạy của chương trình sẽ tăng lên như thế nào. Hoặc bạn cần tính độ dài của một chuỗi ký tự bằng cách đi từng ký tự và cộng 1 cho mỗi ký tự: c - 1 a - 2 t - 3 Tốc độ tiệm cận của nó = O(n), trong đó n là số chữ cái trong từ. Nếu đếm theo nguyên tắc này thì thời gian cần thiết để đếm cả dòng tỷ lệ thuận với số ký tự. Việc đếm số ký tự trong chuỗi 20 ký tự mất gấp đôi thời gian đếm số ký tự trong chuỗi 10 ký tự. Hãy tưởng tượng rằng trong biến độ dài bạn lưu trữ một giá trị bằng số ký tự trong chuỗi. Ví dụ: độ dài = 1000. Để biết độ dài của một chuỗi, bạn chỉ cần truy cập vào biến này, thậm chí bạn không cần phải nhìn vào chính chuỗi đó. Và cho dù chúng ta có thay đổi độ dài như thế nào thì chúng ta vẫn luôn có thể truy cập vào biến này. Trong trường hợp này, tốc độ tiệm cận = O(1). Việc thay đổi dữ liệu đầu vào không làm thay đổi tốc độ của tác vụ đó; quá trình tìm kiếm được hoàn thành trong một khoảng thời gian không đổi. Trong trường hợp này, chương trình là hằng số tiệm cận. Nhược điểm: Bạn lãng phí bộ nhớ máy tính khi lưu trữ thêm một biến và tốn thêm thời gian để cập nhật giá trị của nó. Nếu bạn cho rằng thời gian tuyến tính là xấu, chúng tôi có thể đảm bảo với bạn rằng nó có thể còn tệ hơn nhiều. Ví dụ: O(n 2 ). Ký hiệu này có nghĩa là khi n tăng lên, thời gian cần thiết để lặp qua các phần tử (hoặc một hành động khác) sẽ ngày càng tăng nhanh hơn. Nhưng với n nhỏ, các thuật toán có tốc độ tiệm cận O(n 2 ) có thể hoạt động nhanh hơn các thuật toán có tốc độ tiệm cận O(n). Nhưng đến một lúc nào đó, hàm bậc hai sẽ vượt qua hàm tuyến tính, không còn cách nào khác. Một độ phức tạp tiệm cận khác là thời gian logarit hoặc O(log n). Khi n tăng thì hàm này tăng rất chậm. O(log n) là thời gian chạy của thuật toán tìm kiếm nhị phân cổ điển trong một mảng được sắp xếp (bạn có nhớ danh bạ điện thoại bị rách trong bài giảng không?). Mảng được chia làm hai, sau đó một nửa chứa phần tử được chọn và do đó, mỗi lần giảm một nửa diện tích tìm kiếm, chúng tôi sẽ tìm kiếm phần tử đó. Điều gì sẽ xảy ra nếu chúng ta ngay lập tức tìm thấy thứ mình đang tìm kiếm, chia mảng dữ liệu của mình làm đôi lần đầu tiên? Có một thuật ngữ chỉ thời gian tốt nhất - Omega-large hoặc Ω(n). Trong trường hợp tìm kiếm nhị phân = Ω(1) (tìm trong thời gian không đổi, bất kể kích thước của mảng). Tìm kiếm tuyến tính chạy trong thời gian O(n) và Ω(1) nếu phần tử được tìm kiếm là phần tử đầu tiên. Một biểu tượng khác là theta (Θ(n)). Nó được sử dụng khi các lựa chọn tốt nhất và tồi tệ nhất đều giống nhau. Điều này phù hợp với một ví dụ trong đó chúng tôi lưu trữ độ dài của một chuỗi trong một biến riêng biệt, do đó, với bất kỳ độ dài nào, chỉ cần tham chiếu đến biến này là đủ. Đối với thuật toán này, trường hợp tốt nhất và xấu nhất lần lượt là Ω(1) và O(1). Điều này có nghĩa là thuật toán chạy trong thời gian Θ(1).
Tìm kiếm tuyến tính
Khi bạn mở trình duyệt web, tìm kiếm một trang, thông tin, bạn bè trên mạng xã hội, bạn đang thực hiện tìm kiếm, giống như khi bạn cố gắng tìm một đôi giày phù hợp trong cửa hàng. Bạn có thể nhận thấy rằng sự ngăn nắp có tác động lớn đến cách bạn tìm kiếm. Nếu bạn có tất cả áo sơ mi trong tủ quần áo, bạn thường dễ dàng tìm thấy chiếc áo bạn cần trong số đó hơn là trong số những chiếc áo nằm rải rác không có hệ thống khắp phòng. Tìm kiếm tuyến tính là một phương pháp tìm kiếm tuần tự, từng cái một. Khi bạn xem lại kết quả tìm kiếm của Google từ trên xuống dưới, bạn đang sử dụng tìm kiếm tuyến tính. Ví dụ . Giả sử chúng ta có một danh sách các số: 2 4 0 5 3 7 8 1 Và chúng ta cần tìm số 0. Chúng ta nhìn thấy nó ngay lập tức, nhưng một chương trình máy tính không hoạt động theo cách đó. Cô ấy bắt đầu từ đầu danh sách và nhìn thấy số 2. Sau đó cô ấy kiểm tra, 2=0? Không phải vậy nên cô ấy tiếp tục và chuyển sang nhân vật thứ hai. Thất bại cũng đang chờ cô ở đó, và chỉ ở vị trí thứ ba, thuật toán mới tìm được số cần thiết. Mã giả cho tìm kiếm tuyến tính: Hàm LinearSearch nhận hai đối số làm đầu vào - khóa khóa và mảng mảng []. Khóa là giá trị mong muốn, trong ví dụ trước key = 0. Mảng là danh sách các số mà chúng ta sẽ xem qua. Nếu chúng ta không tìm thấy gì, hàm sẽ trả về -1 (một vị trí không tồn tại trong mảng). Nếu tìm kiếm tuyến tính tìm thấy phần tử mong muốn, hàm sẽ trả về vị trí mà phần tử mong muốn nằm trong mảng. Điểm hay của tìm kiếm tuyến tính là nó sẽ hoạt động với bất kỳ mảng nào, bất kể thứ tự của các phần tử: chúng ta vẫn sẽ duyệt qua toàn bộ mảng. Đây cũng chính là điểm yếu của anh ấy. Nếu bạn cần tìm số 198 trong mảng 200 số được sắp xếp theo thứ tự thì vòng lặp for sẽ trải qua 198 bước. Có lẽ bạn đã đoán được phương pháp nào hoạt động tốt hơn cho một mảng được sắp xếp?
Tìm kiếm nhị phân và cây
Hãy tưởng tượng bạn có một danh sách các nhân vật Disney được sắp xếp theo thứ tự bảng chữ cái và bạn cần tìm Chuột Mickey. Tuyến tính nó sẽ mất một thời gian dài. Và nếu chúng ta sử dụng “phương pháp xé thư mục làm đôi”, chúng ta sẽ đến thẳng Jasmine và chúng ta có thể loại bỏ nửa đầu danh sách một cách an toàn khi nhận ra rằng Mickey không thể ở đó. Sử dụng nguyên tắc tương tự, chúng tôi loại bỏ cột thứ hai. Tiếp tục chiến lược này, chúng ta sẽ tìm thấy Mickey chỉ sau vài bước. Hãy tìm số 144. Chúng ta chia danh sách làm đôi và được số 13. Chúng ta đánh giá xem số chúng ta đang tìm kiếm lớn hơn hay nhỏ hơn 13. 13 < 144, vì vậy chúng ta có thể bỏ qua mọi thứ ở bên trái của 13 và chính con số này. Bây giờ danh sách tìm kiếm của chúng tôi trông như thế này: Có một số phần tử chẵn, vì vậy chúng tôi chọn nguyên tắc mà chúng tôi chọn “ở giữa” (gần đầu hoặc cuối). Giả sử chúng ta đã chọn chiến lược gần với điểm khởi đầu. Trong trường hợp này, "giữa" của chúng tôi = 55,55 < 144. Chúng tôi lại loại bỏ nửa bên trái của danh sách. May mắn thay, số trung bình tiếp theo là 144. Chúng tôi đã tìm thấy 144 trong mảng 13 phần tử bằng cách sử dụng tìm kiếm nhị phân chỉ trong ba bước. Tìm kiếm tuyến tính sẽ xử lý tình huống tương tự trong tối đa 12 bước. Vì thuật toán này giảm một nửa số phần tử trong mảng ở mỗi bước, nên nó sẽ tìm phần tử cần thiết trong thời gian tiệm cận O(log n), trong đó n là số phần tử trong danh sách. Nghĩa là, trong trường hợp của chúng tôi, thời gian tiệm cận = O(log 13) (nhiều hơn ba một chút). Mã giả của hàm tìm kiếm nhị phân: Hàm lấy 4 đối số làm đầu vào: khóa mong muốn, mảng dữ liệu [], trong đó chứa đối số mong muốn, min và max là các con trỏ tới số tối đa và tối thiểu trong mảng, trong đó chúng tôi đang xem xét bước này của thuật toán. Đối với ví dụ của chúng tôi, hình ảnh sau đây ban đầu được đưa ra: Hãy phân tích mã sâu hơn. điểm giữa là giữa mảng của chúng tôi. Nó phụ thuộc vào các điểm cực trị và nằm ở giữa chúng. Sau khi tìm thấy số ở giữa, chúng tôi kiểm tra xem nó có nhỏ hơn số khóa của chúng tôi hay không. Nếu vậy thì khóa cũng lớn hơn bất kỳ số nào ở bên trái của phần giữa và chúng ta có thể gọi lại hàm nhị phân, chỉ bây giờ min = điểm giữa + 1. Nếu hóa ra khóa đó < điểm giữa, chúng ta có thể loại bỏ chính con số đó và tất cả các con số , nằm bên phải anh ấy. Và chúng ta gọi tìm kiếm nhị phân thông qua mảng từ số min trở lên cho đến giá trị (trung điểm – 1). Cuối cùng, nhánh thứ ba: nếu giá trị ở điểm giữa không lớn hơn cũng không nhỏ hơn khóa thì nó không có lựa chọn nào khác ngoài số mong muốn. Trong trường hợp này, chúng tôi trả lại và kết thúc chương trình. Cuối cùng, có thể xảy ra trường hợp số bạn đang tìm kiếm không hề có trong mảng. Để tính đến trường hợp này, chúng tôi thực hiện kiểm tra sau: Và chúng tôi trả về (-1) để cho biết rằng chúng tôi không tìm thấy gì. Bạn đã biết rằng tìm kiếm nhị phân yêu cầu mảng phải được sắp xếp. Vì vậy, nếu chúng ta có một mảng chưa được sắp xếp trong đó chúng ta cần tìm một phần tử nhất định, chúng ta có hai tùy chọn:
Sắp xếp danh sách và áp dụng tìm kiếm nhị phân
Giữ danh sách luôn được sắp xếp đồng thời thêm và xóa các phần tử khỏi danh sách.
Một cách để sắp xếp danh sách là sử dụng cây tìm kiếm nhị phân. Cây tìm kiếm nhị phân là cấu trúc dữ liệu đáp ứng các yêu cầu sau:
Đó là một cái cây (cấu trúc dữ liệu mô phỏng cấu trúc cây - nó có gốc và các nút (lá) khác được kết nối bằng các “nhánh” hoặc các cạnh không có chu trình)
Mỗi nút có 0, 1 hoặc 2 nút con
Cả cây con trái và cây con phải đều là cây tìm kiếm nhị phân.
Tất cả các nút của cây con bên trái của nút X tùy ý có giá trị khóa dữ liệu nhỏ hơn giá trị khóa dữ liệu của chính nút X.
Tất cả các nút trong cây con bên phải của một nút X tùy ý đều có giá trị khóa dữ liệu lớn hơn hoặc bằng giá trị khóa dữ liệu của chính nút X.
Lưu ý: gốc của cây “lập trình viên”, không giống như cây thật, nằm ở trên cùng. Mỗi ô được gọi là một đỉnh và các đỉnh được nối với nhau bằng các cạnh. Gốc của cây là ô số 13. Cây con bên trái của đỉnh 3 được tô màu như hình dưới đây: Cây của chúng ta đáp ứng đầy đủ các yêu cầu đối với cây nhị phân. Điều này có nghĩa là mỗi cây con bên trái của nó chỉ chứa các giá trị nhỏ hơn hoặc bằng giá trị của đỉnh, trong khi cây con bên phải chỉ chứa các giá trị lớn hơn hoặc bằng giá trị của đỉnh. Cả cây con trái và cây con phải đều là cây con nhị phân. Phương pháp xây dựng cây nhị phân không phải là phương pháp duy nhất: bên dưới trong hình, bạn sẽ thấy một tùy chọn khác cho cùng một bộ số và có thể có rất nhiều trong số chúng trong thực tế. Cấu trúc này giúp thực hiện tìm kiếm: chúng tôi tìm giá trị tối thiểu bằng cách di chuyển từ trên xuống bên trái và xuống dưới mỗi lần. Nếu cần tìm số lớn nhất thì ta đi từ trên xuống và sang phải. Việc tìm một số không phải là tối thiểu hoặc tối đa cũng khá đơn giản. Chúng ta đi xuống từ gốc sang trái hoặc sang phải, tùy thuộc vào đỉnh của chúng ta lớn hơn hay nhỏ hơn đỉnh mà chúng ta đang tìm kiếm. Vì vậy, nếu cần tìm số 89, chúng ta thực hiện theo đường dẫn sau: Bạn cũng có thể hiển thị các số theo thứ tự sắp xếp. Ví dụ: nếu chúng ta cần hiển thị tất cả các số theo thứ tự tăng dần, chúng ta lấy cây con bên trái và bắt đầu từ đỉnh ngoài cùng bên trái, đi lên. Thêm một cái gì đó vào cây cũng dễ dàng. Điều chính cần nhớ là cấu trúc. Giả sử chúng ta cần thêm giá trị 7 vào cây, hãy đi tới gốc và kiểm tra. Số 7 < 13 nên ta đi bên trái. Chúng ta thấy 5 ở đó, và chúng ta tiến về bên phải, vì 7 > 5. Hơn nữa, vì 7 > 8 và 8 không có con cháu, chúng ta dựng một nhánh từ 8 sang bên trái và gắn 7 vào nó. Bạn cũng có thể xóa các đỉnh khỏi cây, nhưng điều này có phần phức tạp hơn. Có ba kịch bản xóa khác nhau mà chúng ta cần xem xét.
Tùy chọn đơn giản nhất: chúng ta cần xóa một đỉnh không có con. Ví dụ: số 7 chúng tôi vừa thêm vào. Trong trường hợp này, chúng ta chỉ cần đi theo đường dẫn đến đỉnh có số này và xóa nó.
Một đỉnh có một đỉnh con. Trong trường hợp này, bạn có thể xóa đỉnh mong muốn, nhưng hậu duệ của nó phải được kết nối với “ông nội”, tức là đỉnh mà tổ tiên trực tiếp của nó đã phát triển. Ví dụ, từ cùng một cây, chúng ta cần loại bỏ số 3. Trong trường hợp này, chúng ta nối hậu duệ của nó, một, cùng với toàn bộ cây con thành 5. Việc này được thực hiện đơn giản, vì tất cả các đỉnh bên trái của 5 sẽ là ít hơn con số này (và ít hơn ba từ xa).
Trường hợp khó khăn nhất là khi đỉnh bị xóa có hai con. Bây giờ, điều đầu tiên chúng ta cần làm là tìm đỉnh chứa giá trị lớn hơn tiếp theo, chúng ta cần hoán đổi chúng và sau đó xóa đỉnh mong muốn. Lưu ý rằng đỉnh có giá trị cao nhất tiếp theo không thể có hai con, khi đó con trái của nó sẽ là ứng cử viên sáng giá nhất cho giá trị tiếp theo. Hãy loại bỏ nút gốc 13 khỏi cây của chúng ta. Đầu tiên, chúng ta tìm số gần 13 nhất, lớn hơn nó. Đây là 21. Hoán đổi 21 và 13 và xóa 13.
Có nhiều cách khác nhau để xây dựng cây nhị phân, một số tốt, một số khác thì không tốt. Điều gì xảy ra nếu chúng ta cố gắng xây dựng cây nhị phân từ một danh sách đã được sắp xếp? Tất cả các số sẽ chỉ được thêm vào nhánh bên phải của số trước đó. Nếu muốn tìm một số, chúng ta sẽ không có lựa chọn nào khác ngoài việc lần theo chuỗi xuống. Nó không tốt hơn tìm kiếm tuyến tính. Có những cấu trúc dữ liệu khác phức tạp hơn. Nhưng chúng tôi sẽ không xem xét chúng bây giờ. Giả sử rằng để giải quyết vấn đề xây dựng cây từ danh sách đã sắp xếp, bạn có thể trộn ngẫu nhiên dữ liệu đầu vào.
Thuật toán sắp xếp
Có một dãy số. Chúng ta cần sắp xếp nó. Để đơn giản, chúng ta giả sử rằng chúng ta sắp xếp các số nguyên theo thứ tự tăng dần (từ nhỏ nhất đến lớn nhất). Có một số cách đã biết để thực hiện quá trình này. Ngoài ra, bạn luôn có thể nghĩ ra chủ đề và đưa ra sửa đổi thuật toán.
Sắp xếp theo lựa chọn
Ý tưởng chính là chia danh sách của chúng tôi thành hai phần, được sắp xếp và chưa sắp xếp. Ở mỗi bước của thuật toán, một số mới được chuyển từ phần chưa được sắp xếp sang phần được sắp xếp, v.v. cho đến khi tất cả các số đều nằm trong phần được sắp xếp.
Tìm giá trị tối thiểu chưa được sắp xếp.
Chúng ta hoán đổi giá trị này với giá trị chưa được sắp xếp đầu tiên, do đó đặt nó ở cuối mảng đã sắp xếp.
Nếu còn lại các giá trị chưa được sắp xếp, hãy quay lại bước 1.
Ở bước đầu tiên, tất cả các giá trị đều chưa được sắp xếp. Hãy gọi phần chưa được sắp xếp là Unsorted và phần đã sắp xếp là Sorted (đây chỉ là những từ tiếng Anh và chúng tôi thực hiện điều này chỉ vì Sorted ngắn hơn nhiều so với “Sorted part” và sẽ trông đẹp hơn trong ảnh). Chúng tôi tìm thấy số tối thiểu trong phần chưa được sắp xếp của mảng (nghĩa là ở bước này - trong toàn bộ mảng). Số này là 2. Bây giờ chúng ta thay đổi nó bằng số đầu tiên trong số những số chưa được sắp xếp và đặt nó ở cuối mảng đã sắp xếp (ở bước này - ở vị trí đầu tiên). Ở bước này, đây là số đầu tiên trong mảng, tức là 3. Bước hai. Chúng ta không nhìn vào số 2; nó đã có trong mảng con được sắp xếp. Chúng tôi bắt đầu tìm kiếm mức tối thiểu, bắt đầu từ phần tử thứ hai, đây là 5. Chúng tôi đảm bảo rằng 3 là mức tối thiểu trong số các phần tử chưa được sắp xếp, 5 là phần tử đầu tiên trong số các phần tử chưa được sắp xếp. Chúng ta hoán đổi chúng và thêm 3 vào mảng con đã sắp xếp. Ở bước thứ ba , chúng ta thấy số nhỏ nhất trong mảng con chưa sắp xếp là 4. Chúng ta thay đổi nó bằng số đầu tiên trong số những số chưa được sắp xếp - 5. Ở bước thứ tư, chúng ta thấy rằng trong mảng con chưa sắp xếp, số nhỏ nhất là 5. Chúng tôi thay đổi nó từ 6 và thêm nó vào mảng con đã sắp xếp. Khi chỉ còn lại một số trong số những số chưa được sắp xếp (lớn nhất), điều này có nghĩa là toàn bộ mảng đã được sắp xếp! Đây là cách triển khai mảng trong mã. Hãy thử tự làm nó. Trong cả trường hợp tốt nhất và xấu nhất, để tìm phần tử chưa được sắp xếp nhỏ nhất, chúng ta phải so sánh từng phần tử với từng phần tử của mảng chưa được sắp xếp và chúng ta sẽ thực hiện điều này ở mỗi lần lặp. Nhưng chúng ta không cần xem toàn bộ danh sách mà chỉ xem phần chưa được sắp xếp. Điều này có làm thay đổi tốc độ của thuật toán không? Ở bước đầu tiên, đối với một mảng gồm 5 phần tử, chúng ta thực hiện 4 phép so sánh, ở phần thứ hai - 3, ở phần thứ ba - 2. Để có được số lượng so sánh, chúng ta cần cộng tất cả các số này. Chúng ta nhận được tổng Do đó, tốc độ dự kiến của thuật toán trong trường hợp tốt nhất và xấu nhất là Θ(n 2 ). Không phải là thuật toán hiệu quả nhất! Tuy nhiên, đối với mục đích giáo dục và các tập dữ liệu nhỏ, nó khá có thể áp dụng được.
Sắp xếp bong bóng
Thuật toán sắp xếp bong bóng là một trong những thuật toán đơn giản nhất. Chúng ta đi dọc toàn bộ mảng và so sánh 2 phần tử lân cận. Nếu chúng không đúng thứ tự, chúng tôi sẽ đổi chỗ cho chúng. Ở lần đầu tiên, phần tử nhỏ nhất sẽ xuất hiện (“float”) ở cuối (nếu chúng ta sắp xếp theo thứ tự giảm dần). Lặp lại bước đầu tiên nếu có ít nhất một lần trao đổi được hoàn thành ở bước trước. Hãy sắp xếp mảng. Bước 1: duyệt qua mảng. Thuật toán bắt đầu với hai phần tử đầu tiên, 8 và 6, và kiểm tra xem chúng có theo đúng thứ tự hay không. 8 > 6, vì vậy chúng ta hoán đổi chúng. Tiếp theo, chúng ta xem xét phần tử thứ hai và thứ ba, bây giờ là 8 và 4. Vì những lý do tương tự, chúng ta hoán đổi chúng. Lần thứ ba chúng ta so sánh 8 và 2. Tổng cộng, chúng ta thực hiện ba phép hoán đổi (8, 6), (8, 4), (8, 2). Giá trị 8 "nổi" ở cuối danh sách ở đúng vị trí. Bước 2: hoán đổi (6,4) và (6,2). Số 6 hiện đang ở vị trí áp chót, không cần phải so sánh với “đuôi” đã được sắp xếp sẵn của danh sách. Bước 3: Hoán đổi 4 và 2. Bốn “nổi” lên đúng vị trí của nó. Bước 4: Duyệt qua mảng nhưng không có gì cần thay đổi. Điều này báo hiệu rằng mảng đã được sắp xếp hoàn toàn. Và đây là mã thuật toán. Hãy thử triển khai nó trong C! Sắp xếp nổi bọt mất O(n 2 ) thời gian trong trường hợp xấu nhất (tất cả các số đều sai), vì chúng ta cần thực hiện n bước ở mỗi lần lặp, trong đó cũng có n bước. Trên thực tế, như trong trường hợp của thuật toán sắp xếp lựa chọn, thời gian sẽ ít hơn một chút (n 2/2 – n/2), nhưng điều này có thể bỏ qua. Trong trường hợp tốt nhất (nếu tất cả các phần tử đã sẵn sàng), chúng ta có thể thực hiện điều đó theo n bước, tức là. Ω(n), vì chúng ta sẽ chỉ cần lặp qua mảng một lần và đảm bảo rằng tất cả các phần tử đều ở đúng vị trí (tức là ngay cả n-1 phần tử).
Sắp xếp chèn
Ý tưởng chính của thuật toán này là chia mảng của chúng ta thành hai phần, được sắp xếp và chưa sắp xếp. Ở mỗi bước của thuật toán, số sẽ chuyển từ phần chưa được sắp xếp sang phần được sắp xếp. Hãy xem cách sắp xếp chèn hoạt động như thế nào bằng ví dụ bên dưới. Trước khi chúng ta bắt đầu, tất cả các phần tử được coi là chưa được sắp xếp. Bước 1: Lấy giá trị chưa sắp xếp đầu tiên (3) và chèn nó vào mảng con đã sắp xếp. Ở bước này, toàn bộ mảng con được sắp xếp, phần đầu và phần cuối của nó sẽ chính là ba phần này. Bước 2: Vì 3 > 5, chúng ta sẽ chèn 5 vào mảng con đã sắp xếp ở bên phải của 3. Bước 3: Bây giờ chúng ta tiến hành chèn số 2 vào mảng đã sắp xếp của mình. Ta so sánh 2 giá trị từ phải sang trái để tìm ra vị trí đúng. Vì 2 < 5 và 2 < 3 nên chúng ta đã đạt đến phần đầu của mảng con được sắp xếp. Do đó, chúng ta phải chèn 2 vào bên trái của 3. Để thực hiện việc này, hãy di chuyển 3 và 5 sang bên phải để có chỗ cho số 2 và chèn nó vào đầu mảng. Bước 4. Ta may mắn: 6 > 5 nên ta có thể chèn số đó ngay sau số 5. Bước 5. 4 < 6 và 4 < 5, nhưng 4 > 3. Do đó, ta biết rằng 4 phải được chèn vào bên phải của 3. Một lần nữa, chúng ta buộc phải di chuyển 5 và 6 sang bên phải để tạo khoảng trống cho 4. Xong! Thuật toán tổng quát: Lấy từng phần tử chưa sắp xếp của n và so sánh với các giá trị trong mảng con đã sắp xếp từ phải sang trái cho đến khi tìm được vị trí phù hợp cho n (tức là thời điểm tìm được số đầu tiên nhỏ hơn n) . Sau đó, chúng tôi chuyển tất cả các phần tử đã sắp xếp ở bên phải của số này sang bên phải để nhường chỗ cho n của chúng tôi và chúng tôi chèn nó vào đó, từ đó mở rộng phần được sắp xếp của mảng. Đối với mỗi phần tử chưa được sắp xếp n bạn cần:
Xác định vị trí trong phần được sắp xếp của mảng nơi cần chèn n
Dịch chuyển các phần tử đã sắp xếp sang phải để tạo khoảng trống cho n
Chèn n vào khoảng trống kết quả trong phần được sắp xếp của mảng.
Và đây là mã! Chúng tôi khuyên bạn nên viết phiên bản chương trình sắp xếp của riêng bạn.
Tốc độ tiệm cận của thuật toán
Trong trường hợp xấu nhất, chúng ta sẽ thực hiện một so sánh với phần tử thứ hai, hai so sánh với phần tử thứ ba, v.v. Do đó tốc độ của chúng ta là O(n 2 ). Tốt nhất là chúng ta sẽ làm việc với một mảng đã được sắp xếp sẵn. Phần được sắp xếp mà chúng ta xây dựng từ trái sang phải mà không chèn và di chuyển các phần tử sẽ mất thời gian Ω(n).
Hợp nhất sắp xếp
Thuật toán này có tính đệ quy; nó chia một vấn đề sắp xếp lớn thành các nhiệm vụ con, việc thực hiện nhiệm vụ này giúp nó tiến gần hơn đến việc giải quyết vấn đề lớn ban đầu. Ý tưởng chính là chia một mảng chưa được sắp xếp thành hai phần và sắp xếp các nửa riêng lẻ theo cách đệ quy. Giả sử chúng ta có n phần tử cần sắp xếp. Nếu n < 2, chúng ta sắp xếp xong, nếu không chúng ta sắp xếp riêng phần bên trái và bên phải của mảng, sau đó kết hợp chúng lại. Hãy sắp xếp mảng, chia nó thành hai phần và tiếp tục chia cho đến khi chúng ta nhận được các mảng con có kích thước 1, rõ ràng đã được sắp xếp. Hai mảng con đã sắp xếp có thể được hợp nhất trong thời gian O(n) bằng thuật toán đơn giản: loại bỏ số nhỏ hơn ở đầu mỗi mảng con và chèn số đó vào mảng đã hợp nhất. Lặp lại cho đến khi hết các phần tử. Sắp xếp hợp nhất mất O(nlog n) thời gian cho tất cả các trường hợp. Trong khi chúng tôi chia các mảng thành hai nửa ở mỗi cấp độ đệ quy, chúng tôi nhận được log n. Sau đó, việc hợp nhất các mảng con chỉ cần n phép so sánh. Do đó O(nlogn). Trường hợp tốt nhất và xấu nhất của sắp xếp hợp nhất là như nhau, thời gian chạy dự kiến của thuật toán = Θ(nlog n). Thuật toán này là hiệu quả nhất trong số những thuật toán được xem xét.
 Nhưng đến một lúc nào đó, hàm bậc hai sẽ vượt qua hàm tuyến tính, không còn cách nào khác. Một độ phức tạp tiệm cận khác là thời gian logarit hoặc O(log n). Khi n tăng thì hàm này tăng rất chậm. O(log n) là thời gian chạy của thuật toán tìm kiếm nhị phân cổ điển trong một mảng được sắp xếp (bạn có nhớ danh bạ điện thoại bị rách trong bài giảng không?). Mảng được chia làm hai, sau đó một nửa chứa phần tử được chọn và do đó, mỗi lần giảm một nửa diện tích tìm kiếm, chúng tôi sẽ tìm kiếm phần tử đó.
Nhưng đến một lúc nào đó, hàm bậc hai sẽ vượt qua hàm tuyến tính, không còn cách nào khác. Một độ phức tạp tiệm cận khác là thời gian logarit hoặc O(log n). Khi n tăng thì hàm này tăng rất chậm. O(log n) là thời gian chạy của thuật toán tìm kiếm nhị phân cổ điển trong một mảng được sắp xếp (bạn có nhớ danh bạ điện thoại bị rách trong bài giảng không?). Mảng được chia làm hai, sau đó một nửa chứa phần tử được chọn và do đó, mỗi lần giảm một nửa diện tích tìm kiếm, chúng tôi sẽ tìm kiếm phần tử đó.  Điều gì sẽ xảy ra nếu chúng ta ngay lập tức tìm thấy thứ mình đang tìm kiếm, chia mảng dữ liệu của mình làm đôi lần đầu tiên? Có một thuật ngữ chỉ thời gian tốt nhất - Omega-large hoặc Ω(n). Trong trường hợp tìm kiếm nhị phân = Ω(1) (tìm trong thời gian không đổi, bất kể kích thước của mảng). Tìm kiếm tuyến tính chạy trong thời gian O(n) và Ω(1) nếu phần tử được tìm kiếm là phần tử đầu tiên. Một biểu tượng khác là theta (Θ(n)). Nó được sử dụng khi các lựa chọn tốt nhất và tồi tệ nhất đều giống nhau. Điều này phù hợp với một ví dụ trong đó chúng tôi lưu trữ độ dài của một chuỗi trong một biến riêng biệt, do đó, với bất kỳ độ dài nào, chỉ cần tham chiếu đến biến này là đủ. Đối với thuật toán này, trường hợp tốt nhất và xấu nhất lần lượt là Ω(1) và O(1). Điều này có nghĩa là thuật toán chạy trong thời gian Θ(1).
Điều gì sẽ xảy ra nếu chúng ta ngay lập tức tìm thấy thứ mình đang tìm kiếm, chia mảng dữ liệu của mình làm đôi lần đầu tiên? Có một thuật ngữ chỉ thời gian tốt nhất - Omega-large hoặc Ω(n). Trong trường hợp tìm kiếm nhị phân = Ω(1) (tìm trong thời gian không đổi, bất kể kích thước của mảng). Tìm kiếm tuyến tính chạy trong thời gian O(n) và Ω(1) nếu phần tử được tìm kiếm là phần tử đầu tiên. Một biểu tượng khác là theta (Θ(n)). Nó được sử dụng khi các lựa chọn tốt nhất và tồi tệ nhất đều giống nhau. Điều này phù hợp với một ví dụ trong đó chúng tôi lưu trữ độ dài của một chuỗi trong một biến riêng biệt, do đó, với bất kỳ độ dài nào, chỉ cần tham chiếu đến biến này là đủ. Đối với thuật toán này, trường hợp tốt nhất và xấu nhất lần lượt là Ω(1) và O(1). Điều này có nghĩa là thuật toán chạy trong thời gian Θ(1).
 LinearSearch nhận hai đối số làm đầu vào - khóa khóa và mảng mảng []. Khóa là giá trị mong muốn, trong ví dụ trước key = 0. Mảng là danh sách các số mà chúng ta sẽ xem qua. Nếu chúng ta không tìm thấy gì, hàm sẽ trả về -1 (một vị trí không tồn tại trong mảng). Nếu tìm kiếm tuyến tính tìm thấy phần tử mong muốn, hàm sẽ trả về vị trí mà phần tử mong muốn nằm trong mảng. Điểm hay của tìm kiếm tuyến tính là nó sẽ hoạt động với bất kỳ mảng nào, bất kể thứ tự của các phần tử: chúng ta vẫn sẽ duyệt qua toàn bộ mảng. Đây cũng chính là điểm yếu của anh ấy. Nếu bạn cần tìm số 198 trong mảng 200 số được sắp xếp theo thứ tự thì vòng lặp for sẽ trải qua 198 bước.
LinearSearch nhận hai đối số làm đầu vào - khóa khóa và mảng mảng []. Khóa là giá trị mong muốn, trong ví dụ trước key = 0. Mảng là danh sách các số mà chúng ta sẽ xem qua. Nếu chúng ta không tìm thấy gì, hàm sẽ trả về -1 (một vị trí không tồn tại trong mảng). Nếu tìm kiếm tuyến tính tìm thấy phần tử mong muốn, hàm sẽ trả về vị trí mà phần tử mong muốn nằm trong mảng. Điểm hay của tìm kiếm tuyến tính là nó sẽ hoạt động với bất kỳ mảng nào, bất kể thứ tự của các phần tử: chúng ta vẫn sẽ duyệt qua toàn bộ mảng. Đây cũng chính là điểm yếu của anh ấy. Nếu bạn cần tìm số 198 trong mảng 200 số được sắp xếp theo thứ tự thì vòng lặp for sẽ trải qua 198 bước.  Có lẽ bạn đã đoán được phương pháp nào hoạt động tốt hơn cho một mảng được sắp xếp?
Có lẽ bạn đã đoán được phương pháp nào hoạt động tốt hơn cho một mảng được sắp xếp?

 Tuyến tính nó sẽ mất một thời gian dài. Và nếu chúng ta sử dụng “phương pháp xé thư mục làm đôi”, chúng ta sẽ đến thẳng Jasmine và chúng ta có thể loại bỏ nửa đầu danh sách một cách an toàn khi nhận ra rằng Mickey không thể ở đó.
Tuyến tính nó sẽ mất một thời gian dài. Và nếu chúng ta sử dụng “phương pháp xé thư mục làm đôi”, chúng ta sẽ đến thẳng Jasmine và chúng ta có thể loại bỏ nửa đầu danh sách một cách an toàn khi nhận ra rằng Mickey không thể ở đó.  Sử dụng nguyên tắc tương tự, chúng tôi loại bỏ cột thứ hai. Tiếp tục chiến lược này, chúng ta sẽ tìm thấy Mickey chỉ sau vài bước.
Sử dụng nguyên tắc tương tự, chúng tôi loại bỏ cột thứ hai. Tiếp tục chiến lược này, chúng ta sẽ tìm thấy Mickey chỉ sau vài bước.  Hãy tìm số 144. Chúng ta chia danh sách làm đôi và được số 13. Chúng ta đánh giá xem số chúng ta đang tìm kiếm lớn hơn hay nhỏ hơn 13. 13
Hãy tìm số 144. Chúng ta chia danh sách làm đôi và được số 13. Chúng ta đánh giá xem số chúng ta đang tìm kiếm lớn hơn hay nhỏ hơn 13. 13  < 144, vì vậy chúng ta có thể bỏ qua mọi thứ ở bên trái của 13 và chính con số này. Bây giờ danh sách tìm kiếm của chúng tôi trông như thế này:
< 144, vì vậy chúng ta có thể bỏ qua mọi thứ ở bên trái của 13 và chính con số này. Bây giờ danh sách tìm kiếm của chúng tôi trông như thế này: 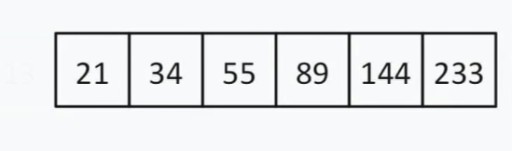 Có một số phần tử chẵn, vì vậy chúng tôi chọn nguyên tắc mà chúng tôi chọn “ở giữa” (gần đầu hoặc cuối). Giả sử chúng ta đã chọn chiến lược gần với điểm khởi đầu. Trong trường hợp này, "giữa" của chúng tôi = 55,55
Có một số phần tử chẵn, vì vậy chúng tôi chọn nguyên tắc mà chúng tôi chọn “ở giữa” (gần đầu hoặc cuối). Giả sử chúng ta đã chọn chiến lược gần với điểm khởi đầu. Trong trường hợp này, "giữa" của chúng tôi = 55,55  < 144. Chúng tôi lại loại bỏ nửa bên trái của danh sách. May mắn thay, số trung bình tiếp theo là 144.
< 144. Chúng tôi lại loại bỏ nửa bên trái của danh sách. May mắn thay, số trung bình tiếp theo là 144.  Chúng tôi đã tìm thấy 144 trong mảng 13 phần tử bằng cách sử dụng tìm kiếm nhị phân chỉ trong ba bước. Tìm kiếm tuyến tính sẽ xử lý tình huống tương tự trong tối đa 12 bước. Vì thuật toán này giảm một nửa số phần tử trong mảng ở mỗi bước, nên nó sẽ tìm phần tử cần thiết trong thời gian tiệm cận O(log n), trong đó n là số phần tử trong danh sách. Nghĩa là, trong trường hợp của chúng tôi, thời gian tiệm cận = O(log 13) (nhiều hơn ba một chút). Mã giả của hàm tìm kiếm nhị phân:
Chúng tôi đã tìm thấy 144 trong mảng 13 phần tử bằng cách sử dụng tìm kiếm nhị phân chỉ trong ba bước. Tìm kiếm tuyến tính sẽ xử lý tình huống tương tự trong tối đa 12 bước. Vì thuật toán này giảm một nửa số phần tử trong mảng ở mỗi bước, nên nó sẽ tìm phần tử cần thiết trong thời gian tiệm cận O(log n), trong đó n là số phần tử trong danh sách. Nghĩa là, trong trường hợp của chúng tôi, thời gian tiệm cận = O(log 13) (nhiều hơn ba một chút). Mã giả của hàm tìm kiếm nhị phân: 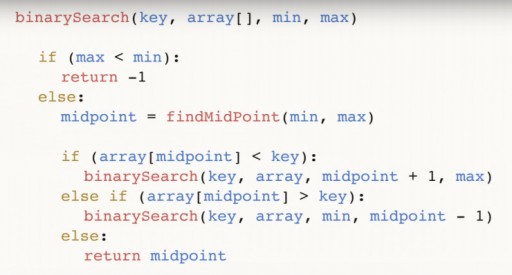 Hàm lấy 4 đối số làm đầu vào: khóa mong muốn, mảng dữ liệu [], trong đó chứa đối số mong muốn, min và max là các con trỏ tới số tối đa và tối thiểu trong mảng, trong đó chúng tôi đang xem xét bước này của thuật toán. Đối với ví dụ của chúng tôi, hình ảnh sau đây ban đầu được đưa ra:
Hàm lấy 4 đối số làm đầu vào: khóa mong muốn, mảng dữ liệu [], trong đó chứa đối số mong muốn, min và max là các con trỏ tới số tối đa và tối thiểu trong mảng, trong đó chúng tôi đang xem xét bước này của thuật toán. Đối với ví dụ của chúng tôi, hình ảnh sau đây ban đầu được đưa ra:  Hãy phân tích mã sâu hơn. điểm giữa là giữa mảng của chúng tôi. Nó phụ thuộc vào các điểm cực trị và nằm ở giữa chúng. Sau khi tìm thấy số ở giữa, chúng tôi kiểm tra xem nó có nhỏ hơn số khóa của chúng tôi hay không.
Hãy phân tích mã sâu hơn. điểm giữa là giữa mảng của chúng tôi. Nó phụ thuộc vào các điểm cực trị và nằm ở giữa chúng. Sau khi tìm thấy số ở giữa, chúng tôi kiểm tra xem nó có nhỏ hơn số khóa của chúng tôi hay không.  Nếu vậy thì khóa cũng lớn hơn bất kỳ số nào ở bên trái của phần giữa và chúng ta có thể gọi lại hàm nhị phân, chỉ bây giờ min = điểm giữa + 1. Nếu hóa ra khóa đó < điểm giữa, chúng ta có thể loại bỏ chính con số đó và tất cả các con số , nằm bên phải anh ấy. Và chúng ta gọi tìm kiếm nhị phân thông qua mảng từ số min trở lên cho đến giá trị (trung điểm – 1).
Nếu vậy thì khóa cũng lớn hơn bất kỳ số nào ở bên trái của phần giữa và chúng ta có thể gọi lại hàm nhị phân, chỉ bây giờ min = điểm giữa + 1. Nếu hóa ra khóa đó < điểm giữa, chúng ta có thể loại bỏ chính con số đó và tất cả các con số , nằm bên phải anh ấy. Và chúng ta gọi tìm kiếm nhị phân thông qua mảng từ số min trở lên cho đến giá trị (trung điểm – 1).  Cuối cùng, nhánh thứ ba: nếu giá trị ở điểm giữa không lớn hơn cũng không nhỏ hơn khóa thì nó không có lựa chọn nào khác ngoài số mong muốn. Trong trường hợp này, chúng tôi trả lại và kết thúc chương trình.
Cuối cùng, nhánh thứ ba: nếu giá trị ở điểm giữa không lớn hơn cũng không nhỏ hơn khóa thì nó không có lựa chọn nào khác ngoài số mong muốn. Trong trường hợp này, chúng tôi trả lại và kết thúc chương trình.  Cuối cùng, có thể xảy ra trường hợp số bạn đang tìm kiếm không hề có trong mảng. Để tính đến trường hợp này, chúng tôi thực hiện kiểm tra sau:
Cuối cùng, có thể xảy ra trường hợp số bạn đang tìm kiếm không hề có trong mảng. Để tính đến trường hợp này, chúng tôi thực hiện kiểm tra sau:  Và chúng tôi trả về (-1) để cho biết rằng chúng tôi không tìm thấy gì. Bạn đã biết rằng tìm kiếm nhị phân yêu cầu mảng phải được sắp xếp. Vì vậy, nếu chúng ta có một mảng chưa được sắp xếp trong đó chúng ta cần tìm một phần tử nhất định, chúng ta có hai tùy chọn:
Và chúng tôi trả về (-1) để cho biết rằng chúng tôi không tìm thấy gì. Bạn đã biết rằng tìm kiếm nhị phân yêu cầu mảng phải được sắp xếp. Vì vậy, nếu chúng ta có một mảng chưa được sắp xếp trong đó chúng ta cần tìm một phần tử nhất định, chúng ta có hai tùy chọn:
 Lưu ý: gốc của cây “lập trình viên”, không giống như cây thật, nằm ở trên cùng. Mỗi ô được gọi là một đỉnh và các đỉnh được nối với nhau bằng các cạnh. Gốc của cây là ô số 13. Cây con bên trái của đỉnh 3 được tô màu như hình dưới đây:
Lưu ý: gốc của cây “lập trình viên”, không giống như cây thật, nằm ở trên cùng. Mỗi ô được gọi là một đỉnh và các đỉnh được nối với nhau bằng các cạnh. Gốc của cây là ô số 13. Cây con bên trái của đỉnh 3 được tô màu như hình dưới đây: 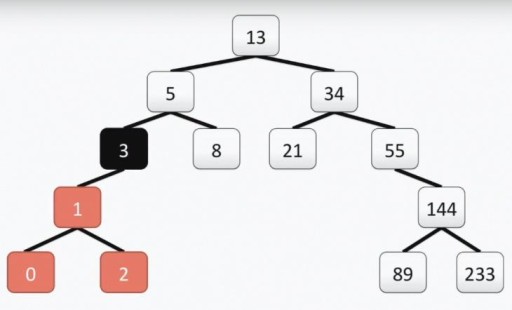 Cây của chúng ta đáp ứng đầy đủ các yêu cầu đối với cây nhị phân. Điều này có nghĩa là mỗi cây con bên trái của nó chỉ chứa các giá trị nhỏ hơn hoặc bằng giá trị của đỉnh, trong khi cây con bên phải chỉ chứa các giá trị lớn hơn hoặc bằng giá trị của đỉnh. Cả cây con trái và cây con phải đều là cây con nhị phân. Phương pháp xây dựng cây nhị phân không phải là phương pháp duy nhất: bên dưới trong hình, bạn sẽ thấy một tùy chọn khác cho cùng một bộ số và có thể có rất nhiều trong số chúng trong thực tế.
Cây của chúng ta đáp ứng đầy đủ các yêu cầu đối với cây nhị phân. Điều này có nghĩa là mỗi cây con bên trái của nó chỉ chứa các giá trị nhỏ hơn hoặc bằng giá trị của đỉnh, trong khi cây con bên phải chỉ chứa các giá trị lớn hơn hoặc bằng giá trị của đỉnh. Cả cây con trái và cây con phải đều là cây con nhị phân. Phương pháp xây dựng cây nhị phân không phải là phương pháp duy nhất: bên dưới trong hình, bạn sẽ thấy một tùy chọn khác cho cùng một bộ số và có thể có rất nhiều trong số chúng trong thực tế.  Cấu trúc này giúp thực hiện tìm kiếm: chúng tôi tìm giá trị tối thiểu bằng cách di chuyển từ trên xuống bên trái và xuống dưới mỗi lần.
Cấu trúc này giúp thực hiện tìm kiếm: chúng tôi tìm giá trị tối thiểu bằng cách di chuyển từ trên xuống bên trái và xuống dưới mỗi lần. 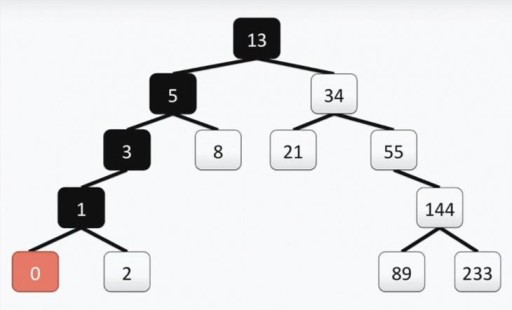 Nếu cần tìm số lớn nhất thì ta đi từ trên xuống và sang phải. Việc tìm một số không phải là tối thiểu hoặc tối đa cũng khá đơn giản. Chúng ta đi xuống từ gốc sang trái hoặc sang phải, tùy thuộc vào đỉnh của chúng ta lớn hơn hay nhỏ hơn đỉnh mà chúng ta đang tìm kiếm. Vì vậy, nếu cần tìm số 89, chúng ta thực hiện theo đường dẫn sau:
Nếu cần tìm số lớn nhất thì ta đi từ trên xuống và sang phải. Việc tìm một số không phải là tối thiểu hoặc tối đa cũng khá đơn giản. Chúng ta đi xuống từ gốc sang trái hoặc sang phải, tùy thuộc vào đỉnh của chúng ta lớn hơn hay nhỏ hơn đỉnh mà chúng ta đang tìm kiếm. Vì vậy, nếu cần tìm số 89, chúng ta thực hiện theo đường dẫn sau:  Bạn cũng có thể hiển thị các số theo thứ tự sắp xếp. Ví dụ: nếu chúng ta cần hiển thị tất cả các số theo thứ tự tăng dần, chúng ta lấy cây con bên trái và bắt đầu từ đỉnh ngoài cùng bên trái, đi lên. Thêm một cái gì đó vào cây cũng dễ dàng. Điều chính cần nhớ là cấu trúc. Giả sử chúng ta cần thêm giá trị 7 vào cây, hãy đi tới gốc và kiểm tra. Số 7 < 13 nên ta đi bên trái. Chúng ta thấy 5 ở đó, và chúng ta tiến về bên phải, vì 7 > 5. Hơn nữa, vì 7 > 8 và 8 không có con cháu, chúng ta dựng một nhánh từ 8 sang bên trái và gắn 7 vào nó. Bạn cũng có thể xóa các đỉnh
Bạn cũng có thể hiển thị các số theo thứ tự sắp xếp. Ví dụ: nếu chúng ta cần hiển thị tất cả các số theo thứ tự tăng dần, chúng ta lấy cây con bên trái và bắt đầu từ đỉnh ngoài cùng bên trái, đi lên. Thêm một cái gì đó vào cây cũng dễ dàng. Điều chính cần nhớ là cấu trúc. Giả sử chúng ta cần thêm giá trị 7 vào cây, hãy đi tới gốc và kiểm tra. Số 7 < 13 nên ta đi bên trái. Chúng ta thấy 5 ở đó, và chúng ta tiến về bên phải, vì 7 > 5. Hơn nữa, vì 7 > 8 và 8 không có con cháu, chúng ta dựng một nhánh từ 8 sang bên trái và gắn 7 vào nó. Bạn cũng có thể xóa các đỉnh 
 khỏi cây, nhưng điều này có phần phức tạp hơn. Có ba kịch bản xóa khác nhau mà chúng ta cần xem xét.
khỏi cây, nhưng điều này có phần phức tạp hơn. Có ba kịch bản xóa khác nhau mà chúng ta cần xem xét.



 Tất cả các số sẽ chỉ được thêm vào nhánh bên phải của số trước đó. Nếu muốn tìm một số, chúng ta sẽ không có lựa chọn nào khác ngoài việc lần theo chuỗi xuống.
Tất cả các số sẽ chỉ được thêm vào nhánh bên phải của số trước đó. Nếu muốn tìm một số, chúng ta sẽ không có lựa chọn nào khác ngoài việc lần theo chuỗi xuống.  Nó không tốt hơn tìm kiếm tuyến tính. Có những cấu trúc dữ liệu khác phức tạp hơn. Nhưng chúng tôi sẽ không xem xét chúng bây giờ. Giả sử rằng để giải quyết vấn đề xây dựng cây từ danh sách đã sắp xếp, bạn có thể trộn ngẫu nhiên dữ liệu đầu vào.
Nó không tốt hơn tìm kiếm tuyến tính. Có những cấu trúc dữ liệu khác phức tạp hơn. Nhưng chúng tôi sẽ không xem xét chúng bây giờ. Giả sử rằng để giải quyết vấn đề xây dựng cây từ danh sách đã sắp xếp, bạn có thể trộn ngẫu nhiên dữ liệu đầu vào.
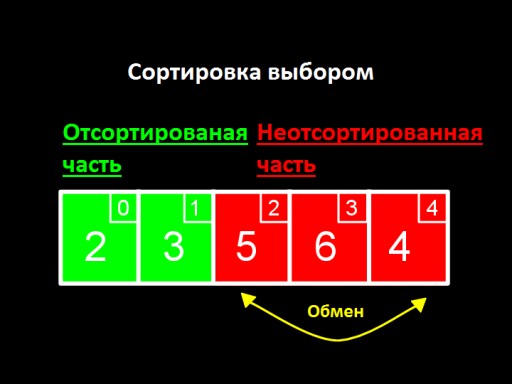 Ý tưởng chính là chia danh sách của chúng tôi thành hai phần, được sắp xếp và chưa sắp xếp. Ở mỗi bước của thuật toán, một số mới được chuyển từ phần chưa được sắp xếp sang phần được sắp xếp, v.v. cho đến khi tất cả các số đều nằm trong phần được sắp xếp.
Ý tưởng chính là chia danh sách của chúng tôi thành hai phần, được sắp xếp và chưa sắp xếp. Ở mỗi bước của thuật toán, một số mới được chuyển từ phần chưa được sắp xếp sang phần được sắp xếp, v.v. cho đến khi tất cả các số đều nằm trong phần được sắp xếp.
 Chúng tôi tìm thấy số tối thiểu trong phần chưa được sắp xếp của mảng (nghĩa là ở bước này - trong toàn bộ mảng). Số này là 2. Bây giờ chúng ta thay đổi nó bằng số đầu tiên trong số những số chưa được sắp xếp và đặt nó ở cuối mảng đã sắp xếp (ở bước này - ở vị trí đầu tiên). Ở bước này, đây là số đầu tiên trong mảng, tức là 3.
Chúng tôi tìm thấy số tối thiểu trong phần chưa được sắp xếp của mảng (nghĩa là ở bước này - trong toàn bộ mảng). Số này là 2. Bây giờ chúng ta thay đổi nó bằng số đầu tiên trong số những số chưa được sắp xếp và đặt nó ở cuối mảng đã sắp xếp (ở bước này - ở vị trí đầu tiên). Ở bước này, đây là số đầu tiên trong mảng, tức là 3.  Bước hai. Chúng ta không nhìn vào số 2; nó đã có trong mảng con được sắp xếp. Chúng tôi bắt đầu tìm kiếm mức tối thiểu, bắt đầu từ phần tử thứ hai, đây là 5. Chúng tôi đảm bảo rằng 3 là mức tối thiểu trong số các phần tử chưa được sắp xếp, 5 là phần tử đầu tiên trong số các phần tử chưa được sắp xếp. Chúng ta hoán đổi chúng và thêm 3 vào mảng con đã sắp xếp.
Bước hai. Chúng ta không nhìn vào số 2; nó đã có trong mảng con được sắp xếp. Chúng tôi bắt đầu tìm kiếm mức tối thiểu, bắt đầu từ phần tử thứ hai, đây là 5. Chúng tôi đảm bảo rằng 3 là mức tối thiểu trong số các phần tử chưa được sắp xếp, 5 là phần tử đầu tiên trong số các phần tử chưa được sắp xếp. Chúng ta hoán đổi chúng và thêm 3 vào mảng con đã sắp xếp.  Ở bước thứ ba , chúng ta thấy số nhỏ nhất trong mảng con chưa sắp xếp là 4. Chúng ta thay đổi nó bằng số đầu tiên trong số những số chưa được sắp xếp - 5.
Ở bước thứ ba , chúng ta thấy số nhỏ nhất trong mảng con chưa sắp xếp là 4. Chúng ta thay đổi nó bằng số đầu tiên trong số những số chưa được sắp xếp - 5.  Ở bước thứ tư, chúng ta thấy rằng trong mảng con chưa sắp xếp, số nhỏ nhất là 5. Chúng tôi thay đổi nó từ 6 và thêm nó vào mảng con đã sắp xếp.
Ở bước thứ tư, chúng ta thấy rằng trong mảng con chưa sắp xếp, số nhỏ nhất là 5. Chúng tôi thay đổi nó từ 6 và thêm nó vào mảng con đã sắp xếp. 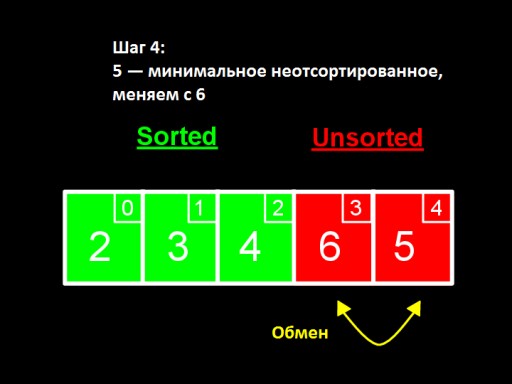 Khi chỉ còn lại một số trong số những số chưa được sắp xếp (lớn nhất), điều này có nghĩa là toàn bộ mảng đã được sắp xếp!
Khi chỉ còn lại một số trong số những số chưa được sắp xếp (lớn nhất), điều này có nghĩa là toàn bộ mảng đã được sắp xếp! 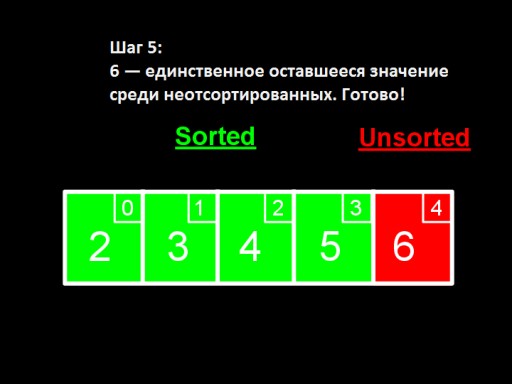 Đây là cách triển khai mảng trong mã. Hãy thử tự làm nó.
Đây là cách triển khai mảng trong mã. Hãy thử tự làm nó.  Trong cả trường hợp tốt nhất và xấu nhất, để tìm phần tử chưa được sắp xếp nhỏ nhất, chúng ta phải so sánh từng phần tử với từng phần tử của mảng chưa được sắp xếp và chúng ta sẽ thực hiện điều này ở mỗi lần lặp. Nhưng chúng ta không cần xem toàn bộ danh sách mà chỉ xem phần chưa được sắp xếp. Điều này có làm thay đổi tốc độ của thuật toán không? Ở bước đầu tiên, đối với một mảng gồm 5 phần tử, chúng ta thực hiện 4 phép so sánh, ở phần thứ hai - 3, ở phần thứ ba - 2. Để có được số lượng so sánh, chúng ta cần cộng tất cả các số này. Chúng ta nhận được tổng
Trong cả trường hợp tốt nhất và xấu nhất, để tìm phần tử chưa được sắp xếp nhỏ nhất, chúng ta phải so sánh từng phần tử với từng phần tử của mảng chưa được sắp xếp và chúng ta sẽ thực hiện điều này ở mỗi lần lặp. Nhưng chúng ta không cần xem toàn bộ danh sách mà chỉ xem phần chưa được sắp xếp. Điều này có làm thay đổi tốc độ của thuật toán không? Ở bước đầu tiên, đối với một mảng gồm 5 phần tử, chúng ta thực hiện 4 phép so sánh, ở phần thứ hai - 3, ở phần thứ ba - 2. Để có được số lượng so sánh, chúng ta cần cộng tất cả các số này. Chúng ta nhận được tổng  Do đó, tốc độ dự kiến của thuật toán trong trường hợp tốt nhất và xấu nhất là Θ(n 2 ). Không phải là thuật toán hiệu quả nhất! Tuy nhiên, đối với mục đích giáo dục và các tập dữ liệu nhỏ, nó khá có thể áp dụng được.
Do đó, tốc độ dự kiến của thuật toán trong trường hợp tốt nhất và xấu nhất là Θ(n 2 ). Không phải là thuật toán hiệu quả nhất! Tuy nhiên, đối với mục đích giáo dục và các tập dữ liệu nhỏ, nó khá có thể áp dụng được.
 Bước 1: duyệt qua mảng. Thuật toán bắt đầu với hai phần tử đầu tiên, 8 và 6, và kiểm tra xem chúng có theo đúng thứ tự hay không. 8 > 6, vì vậy chúng ta hoán đổi chúng. Tiếp theo, chúng ta xem xét phần tử thứ hai và thứ ba, bây giờ là 8 và 4. Vì những lý do tương tự, chúng ta hoán đổi chúng. Lần thứ ba chúng ta so sánh 8 và 2. Tổng cộng, chúng ta thực hiện ba phép hoán đổi (8, 6), (8, 4), (8, 2). Giá trị 8 "nổi" ở cuối danh sách ở đúng vị trí.
Bước 1: duyệt qua mảng. Thuật toán bắt đầu với hai phần tử đầu tiên, 8 và 6, và kiểm tra xem chúng có theo đúng thứ tự hay không. 8 > 6, vì vậy chúng ta hoán đổi chúng. Tiếp theo, chúng ta xem xét phần tử thứ hai và thứ ba, bây giờ là 8 và 4. Vì những lý do tương tự, chúng ta hoán đổi chúng. Lần thứ ba chúng ta so sánh 8 và 2. Tổng cộng, chúng ta thực hiện ba phép hoán đổi (8, 6), (8, 4), (8, 2). Giá trị 8 "nổi" ở cuối danh sách ở đúng vị trí.  Bước 2: hoán đổi (6,4) và (6,2). Số 6 hiện đang ở vị trí áp chót, không cần phải so sánh với “đuôi” đã được sắp xếp sẵn của danh sách.
Bước 2: hoán đổi (6,4) và (6,2). Số 6 hiện đang ở vị trí áp chót, không cần phải so sánh với “đuôi” đã được sắp xếp sẵn của danh sách.  Bước 3: Hoán đổi 4 và 2. Bốn “nổi” lên đúng vị trí của nó.
Bước 3: Hoán đổi 4 và 2. Bốn “nổi” lên đúng vị trí của nó.  Bước 4: Duyệt qua mảng nhưng không có gì cần thay đổi. Điều này báo hiệu rằng mảng đã được sắp xếp hoàn toàn.
Bước 4: Duyệt qua mảng nhưng không có gì cần thay đổi. Điều này báo hiệu rằng mảng đã được sắp xếp hoàn toàn. 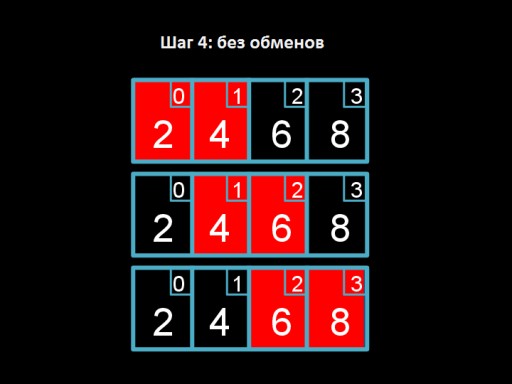 Và đây là mã thuật toán. Hãy thử triển khai nó trong C!
Và đây là mã thuật toán. Hãy thử triển khai nó trong C!  Sắp xếp nổi bọt mất O(n 2 ) thời gian trong trường hợp xấu nhất (tất cả các số đều sai), vì chúng ta cần thực hiện n bước ở mỗi lần lặp, trong đó cũng có n bước. Trên thực tế, như trong trường hợp của thuật toán sắp xếp lựa chọn, thời gian sẽ ít hơn một chút (n 2/2 – n/2), nhưng điều này có thể bỏ qua. Trong trường hợp tốt nhất (nếu tất cả các phần tử đã sẵn sàng), chúng ta có thể thực hiện điều đó theo n bước, tức là. Ω(n), vì chúng ta sẽ chỉ cần lặp qua mảng một lần và đảm bảo rằng tất cả các phần tử đều ở đúng vị trí (tức là ngay cả n-1 phần tử).
Sắp xếp nổi bọt mất O(n 2 ) thời gian trong trường hợp xấu nhất (tất cả các số đều sai), vì chúng ta cần thực hiện n bước ở mỗi lần lặp, trong đó cũng có n bước. Trên thực tế, như trong trường hợp của thuật toán sắp xếp lựa chọn, thời gian sẽ ít hơn một chút (n 2/2 – n/2), nhưng điều này có thể bỏ qua. Trong trường hợp tốt nhất (nếu tất cả các phần tử đã sẵn sàng), chúng ta có thể thực hiện điều đó theo n bước, tức là. Ω(n), vì chúng ta sẽ chỉ cần lặp qua mảng một lần và đảm bảo rằng tất cả các phần tử đều ở đúng vị trí (tức là ngay cả n-1 phần tử).

 Hãy xem cách sắp xếp chèn hoạt động như thế nào bằng ví dụ bên dưới. Trước khi chúng ta bắt đầu, tất cả các phần tử được coi là chưa được sắp xếp.
Hãy xem cách sắp xếp chèn hoạt động như thế nào bằng ví dụ bên dưới. Trước khi chúng ta bắt đầu, tất cả các phần tử được coi là chưa được sắp xếp.  Bước 1: Lấy giá trị chưa sắp xếp đầu tiên (3) và chèn nó vào mảng con đã sắp xếp. Ở bước này, toàn bộ mảng con được sắp xếp, phần đầu và phần cuối của nó sẽ chính là ba phần này.
Bước 1: Lấy giá trị chưa sắp xếp đầu tiên (3) và chèn nó vào mảng con đã sắp xếp. Ở bước này, toàn bộ mảng con được sắp xếp, phần đầu và phần cuối của nó sẽ chính là ba phần này.  Bước 2: Vì 3 > 5, chúng ta sẽ chèn 5 vào mảng con đã sắp xếp ở bên phải của 3.
Bước 2: Vì 3 > 5, chúng ta sẽ chèn 5 vào mảng con đã sắp xếp ở bên phải của 3.  Bước 3: Bây giờ chúng ta tiến hành chèn số 2 vào mảng đã sắp xếp của mình. Ta so sánh 2 giá trị từ phải sang trái để tìm ra vị trí đúng. Vì 2 < 5 và 2 < 3 nên chúng ta đã đạt đến phần đầu của mảng con được sắp xếp. Do đó, chúng ta phải chèn 2 vào bên trái của 3. Để thực hiện việc này, hãy di chuyển 3 và 5 sang bên phải để có chỗ cho số 2 và chèn nó vào đầu mảng.
Bước 3: Bây giờ chúng ta tiến hành chèn số 2 vào mảng đã sắp xếp của mình. Ta so sánh 2 giá trị từ phải sang trái để tìm ra vị trí đúng. Vì 2 < 5 và 2 < 3 nên chúng ta đã đạt đến phần đầu của mảng con được sắp xếp. Do đó, chúng ta phải chèn 2 vào bên trái của 3. Để thực hiện việc này, hãy di chuyển 3 và 5 sang bên phải để có chỗ cho số 2 và chèn nó vào đầu mảng.  Bước 4. Ta may mắn: 6 > 5 nên ta có thể chèn số đó ngay sau số 5.
Bước 4. Ta may mắn: 6 > 5 nên ta có thể chèn số đó ngay sau số 5.  Bước 5. 4 < 6 và 4 < 5, nhưng 4 > 3. Do đó, ta biết rằng 4 phải được chèn vào bên phải của 3. Một lần nữa, chúng ta buộc phải di chuyển 5 và 6 sang bên phải để tạo khoảng trống cho 4.
Bước 5. 4 < 6 và 4 < 5, nhưng 4 > 3. Do đó, ta biết rằng 4 phải được chèn vào bên phải của 3. Một lần nữa, chúng ta buộc phải di chuyển 5 và 6 sang bên phải để tạo khoảng trống cho 4.  Xong! Thuật toán tổng quát: Lấy từng phần tử chưa sắp xếp của n và so sánh với các giá trị trong mảng con đã sắp xếp từ phải sang trái cho đến khi tìm được vị trí phù hợp cho n (tức là thời điểm tìm được số đầu tiên nhỏ hơn n) . Sau đó, chúng tôi chuyển tất cả các phần tử đã sắp xếp ở bên phải của số này sang bên phải để nhường chỗ cho n của chúng tôi và chúng tôi chèn nó vào đó, từ đó mở rộng phần được sắp xếp của mảng. Đối với mỗi phần tử chưa được sắp xếp n bạn cần:
Xong! Thuật toán tổng quát: Lấy từng phần tử chưa sắp xếp của n và so sánh với các giá trị trong mảng con đã sắp xếp từ phải sang trái cho đến khi tìm được vị trí phù hợp cho n (tức là thời điểm tìm được số đầu tiên nhỏ hơn n) . Sau đó, chúng tôi chuyển tất cả các phần tử đã sắp xếp ở bên phải của số này sang bên phải để nhường chỗ cho n của chúng tôi và chúng tôi chèn nó vào đó, từ đó mở rộng phần được sắp xếp của mảng. Đối với mỗi phần tử chưa được sắp xếp n bạn cần:

 Giả sử chúng ta có n phần tử cần sắp xếp. Nếu n < 2, chúng ta sắp xếp xong, nếu không chúng ta sắp xếp riêng phần bên trái và bên phải của mảng, sau đó kết hợp chúng lại. Hãy sắp xếp mảng,
Giả sử chúng ta có n phần tử cần sắp xếp. Nếu n < 2, chúng ta sắp xếp xong, nếu không chúng ta sắp xếp riêng phần bên trái và bên phải của mảng, sau đó kết hợp chúng lại. Hãy sắp xếp mảng,  chia nó thành hai phần và tiếp tục chia cho đến khi chúng ta nhận được các mảng con có kích thước 1, rõ ràng đã được sắp xếp.
chia nó thành hai phần và tiếp tục chia cho đến khi chúng ta nhận được các mảng con có kích thước 1, rõ ràng đã được sắp xếp.  Hai mảng con đã sắp xếp có thể được hợp nhất trong thời gian O(n) bằng thuật toán đơn giản: loại bỏ số nhỏ hơn ở đầu mỗi mảng con và chèn số đó vào mảng đã hợp nhất. Lặp lại cho đến khi hết các phần tử.
Hai mảng con đã sắp xếp có thể được hợp nhất trong thời gian O(n) bằng thuật toán đơn giản: loại bỏ số nhỏ hơn ở đầu mỗi mảng con và chèn số đó vào mảng đã hợp nhất. Lặp lại cho đến khi hết các phần tử. 
 Sắp xếp hợp nhất mất O(nlog n) thời gian cho tất cả các trường hợp. Trong khi chúng tôi chia các mảng thành hai nửa ở mỗi cấp độ đệ quy, chúng tôi nhận được log n. Sau đó, việc hợp nhất các mảng con chỉ cần n phép so sánh. Do đó O(nlogn). Trường hợp tốt nhất và xấu nhất của sắp xếp hợp nhất là như nhau, thời gian chạy dự kiến của thuật toán = Θ(nlog n). Thuật toán này là hiệu quả nhất trong số những thuật toán được xem xét.
Sắp xếp hợp nhất mất O(nlog n) thời gian cho tất cả các trường hợp. Trong khi chúng tôi chia các mảng thành hai nửa ở mỗi cấp độ đệ quy, chúng tôi nhận được log n. Sau đó, việc hợp nhất các mảng con chỉ cần n phép so sánh. Do đó O(nlogn). Trường hợp tốt nhất và xấu nhất của sắp xếp hợp nhất là như nhau, thời gian chạy dự kiến của thuật toán = Θ(nlog n). Thuật toán này là hiệu quả nhất trong số những thuật toán được xem xét. 

GO TO FULL VERSION