В серверных приложениях один из самых важных показателей — это безопасность. Это один из видов Non-Functional Requirements (нефункциональных требований).
Безопасность включает в себя множество компонентов. Разумеется, чтобы охватить в полной мере и объеме все те защитные принципы и действия, которые известны, нужно написать не одну статью, так что остановимся на самом важном.
Человек, который хорошо разбирается в этой теме, сможет настроить все процессы и проследить, чтобы они не создавали новых дыр в безопасности, будет нужен в любой команде.
Конечно, не стоит думать, что если следовать этим практикам, то приложение будет однозначно безопасно. Нет! Но оно точно будет более безопасным с ними. Поехали.
1. Обеспечить безопасность на уровне языка Java
Прежде всего, безопасность в Java начинается прямо на уровне возможностей языка. Вот что бы мы делали, если бы не было модификаторов доступа?... Анархия, не иначе.
Язык программирования помогает нам писать безопасный код, а также пользоваться многими неявными функциями безопасности:
Строгая типизация. Java — это язык со статической типизацией, который дает возможность обнаружения ошибок, связанных с типами, во время выполнения.
Модификаторы доступа. Благодаря им мы можем настраивать доступ к классам, методам и полям классов так, как нам нужно.
Автоматическое управление памятью. Для этого дела у нас (у джавистов ;)) есть Garbage Collector, который освобождает от настройки вручную. Да, иногда возникают проблемы.
Проверка байткода: Java компилируется в байткод, который проверяет runtime, прежде чем запустить его.
Помимо всего прочего, есть рекомендации от Оракла по безопасности. Конечно написано не “высоким слогом” и можно уснуть несколько раз при прочтении, но оно стоит того.
В особенности важен документ Secure Coding Guidelines for Java SE, в котором есть советы, как писать безопасный код. Этот документ несет много полезного. Если есть возможность — обязательно стоит прочесть.
Для разогрева интереса к этому материалу, приведу несколько интересных советов:
Избегайте сериализации чувствительных к безопасности (secure-sensitive) классов. В этом случае можно получить по сериализованному файлу интерфейс класса, не говоря уже о данных, которые сериализуются.
Старайтесь избегать mutable классов для данных. Это дает все преимущества неизменяемых классов (например, потокобезопасность). Если будет изменяемый объект, то это может привести к неожиданному поведению.
Создавайте копии возвращаемых изменяемых объектов. Если метод возвращает ссылку на внутренний изменяемый объект, тогда клиентский код может изменить внутреннее состояние объекта.
И так далее…
В общем, в Secure Coding Guidelines for Java SE собран набор советов и рекомендаций по тому, как правильно и безопасно писать код на Java.
2. Устранить SQL injection уязвимость
Уникальная уязвимость. Уникальность ее состоит в том, что она одновременно и одна из самых известных, и одна из самых частых уязвимостей. Если не интересоваться вопросом безопасности, то об этом и не узнаешь.
Что такое SQL injection? Это атака базы данных посредством внедрения дополнительного SQL-кода там, где это не ожидается.
Допустим, у нас есть метод, который принимает какой-то параметр для запроса в базу данных. Например, имя пользователя. Код с уязвимостью будет выглядеть примерно так:
// Метод достает из базы данных всех пользователей с определенным именем
public List<User> findByFirstName(String firstName) throws SQLException {
// Создается связь с базой данных
Connection connection = DriverManager.getConnection(DB_URL, USER, PASS);
// Пишем sql запрос в базу данных с нашим firstName
String query = "SELECT * FROM USERS WHERE firstName = " + firstName;
// выполняем запрос
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery(query);
// при помощи mapToUsers переводит ResultSet в коллекцию юзеров.
return mapToUsers(result);
}
private List<User> mapToUsers(ResultSet resultSet) {
//переводит в коллекцию юзеров
}
В этом примере sql запрос готовится заранее в отдельной строке. Казалось бы, в чем проблема, да? Может, проблема в том, что лучше бы использовать String.format? Нет? А в чем тогда?
Поставим себя на место тестировщика и подумаем, что можно передать в значении firstName. Например:
Можно передать то, что ожидается — имя пользователя. Тогда база данных вернет всех пользователей с таким именем.
Можно передать пустую строку: тогда вернутся все пользователи.
А можно передать следующее: “‘’; DROP TABLE USERS;”. И здесь уже будут бооольшие проблемы. Этим запросом удалится таблица из базы данных. Со всеми данными. ВСЕМИ.
Представляете, какие проблемы могут быть из-за этого? Далее можно писать что угодно. Можно поменять имя у всех пользователей, можно удалить их адреса. Простор для вредительства обширен.
Чтобы избежать этого, нужно прекратить внедрение уже готового запроса и вместо этого — формировать его при помощи параметров. Это должен быть единственный способ создания запросов к базе данных. Таким образом можно устранить эту уязвимость.
Пример:
// Метод достает из базы данных всех пользователей с определенным именем
public List<User> findByFirstName(String firstName) throws SQLException {
// Создается связь с базой данных
Connection connection = DriverManager.getConnection(DB_URL, USER, PASS);
// Создаем параметризированный запрос.
String query = "SELECT * FROM USERS WHERE firstName = ?";
// Создаем подготовленный стейтмент с параметризованным запросом
PreparedStatement statement = connection.prepareStatement(query);
// Передаем значение параметра
statement.setString(1, firstName);
// выполняем запрос
ResultSet result = statement.executeQuery(query);
// при помощи mapToUsers переводим ResultSet в коллекцию юзеров.
return mapToUsers(result);
}
private List<User> mapToUsers(ResultSet resultSet) {
//переводим в коллекцию юзеров
}
Таким образом избегают данной уязвимости.
Для тех, кому хочется погрузиться в вопрос глубже этой статьи — вот отличный пример.
Как понять, что вы поняли эту часть? Если шутейка ниже стала понятной, то это верный признак, что суть уязвимости ясна :D
3. Сканировать и держать обновленными зависимости
Что это значит? Для тех, кто не знает, что такое зависимость (dependency) поясню: это jar архив с кодом, который подключают к проекту при помощи систем автоматической сборки (Maven, Gradle, Ant) для того, чтобы переиспользовать чье-то решение. Например, Project Lombok, который за нас генерирует в рантайме геттеры, сеттеры и т.д.
А если говорить о больших приложениях, так они используют множество различных зависимостей. Некоторые — транзитивно (то есть, у каждой зависимости могут быть свои зависимости, и так далее).
Поэтому злоумышленники все чаще обращают внимание на open-source зависимости, так как их регулярно используют, и из-за них у множества клиентов могут быть проблемы. Важно убедиться, что во всем дереве зависимостей (а именно так это и выглядит) нет известных уязвимостей. А для этого есть несколько путей.
Использовать Snyk для мониторинга
Инструмент Snyk проверяет все зависимости проекта и отмечает известные уязвимости. Там можно зарегистрироваться и импортировать свои проекты через GitHub, например.
Также, как видно из картинки выше, если в более новой версии есть решение этой уязвимости, Snyk предложит сделать это и создать Pull-Request. Использовать его можно бесплатно для open-source проектов.
Проекты будут сканироваться с какой-то периодичностью: раз в неделю, раз в месяц.
Я зарегистрировался и добавил все свои публичные репозитории в сканирование Snyk (в этом нет ничего опасного: они и так в открытом доступе для всех).
Далее Snyk показал результат сканирования:
А через некоторое время, Snyk-bot подготовил несколько Pull-Request’ов в проектах, где нужно обновить зависимости:
И вот еще:
Так что это отличный инструмент для поиска уязвимостей и мониторинга по обновлению новых версий.
Использовать GitHub Security Lab
Те, кто работает GitHub, могут воспользоваться и их встроенными инструментами. Более детально про этот подход можно почитать в моем переводе из их блога Анонс GitHub Security Lab.
Этот инструмент, конечно, попроще, чем Snyk, но пренебрегать им точно не стоит.
Плюс ко всему количество известных уязвимостей будет только расти, поэтому и Snyk, и GitHub Security Lab будут расширяться и улучшаться.
Активировать Sonatype DepShield
Если пользоваться GitHub’ом для хранения своих репозиториев, можно добавить к себе на проекты из MarketPlace одно из приложений — Sonatype DepShield. При его помощи можно также сканировать проекты на зависимости.
Более того, если он найдет что-то, будет создано GitHub Issue с соответствующим описанием, как показано ниже:
4. Осторожно обращаться с конфиденциальными данными
В английской речи чаще встречается словосочетание “sensitive data”. Раскрытие персональных данных, номеров кредитных карт и прочей личной информации клиента может нанести непоправимый вред.
Прежде всего, нужно внимательно посмотреть на дизайн приложения и определить, действительно ли нужны какие-то данные. Возможно, в части из них никакой потребности нет, а добавили их для будущего, которое не наступило и вряд ли наступит. К тому же, во время логирования проекта может произойти утечка таких данных.
Простой способ предотвратить попадание конфиденциальных данных в ваши логи — очистить методы toString() доменных сущностей (таких как User, Student, Teacher и так далее). Таким образом нельзя будет распечатать конфиденциальные поля случайно. Если использовать Lombok для генерации метода toString(), то можно использовать аннотацию @ToString.Exclude, чтобы поле не использовалось в выводе через метод toString().
Кроме того, будьте очень осторожны, передавая данные внешнему миру. Например, есть http endpoint, который показывает имена всех пользователей. Нет необходимости показывать внутренний уникальный идентификатор пользователя.
Почему? Потому что по нему злоумышленник может получить другую, более конфиденциальную информацию о каждом из пользователей.
Например, если задействовать Jackson для сериализации и десериализации POJO в JSON, то можно использовать аннотации @JsonIgnore и @JsonIgnoreProperties, чтобы исключить сериализацию и десериализацию конкретных полей.
А вообще нужно использовать различные POJO классы для различных мест. Что это значит?
Для работы с базой данных использовать одни POJO — Entity.
Для работы с бизнес логикой — переводить Entity в Model.
Для работы с внешним миром и с отправкой на http запросы — использовать третьи сущности — DTO.
Таким образом можно четко определить, какие именно поля будут видны снаружи, а какие — нет.
Использовать надежные алгоритмы шифрования и хеширования
Конфиденциальные данные клиентов нужно хранить надежно. Для этого нужно использовать шифрование.
В зависимости от задачи, нужно решить, какой тип шифрования использовать.
Далее, более сильное шифрование требует больше времени, поэтому опять же нужно учитывать, насколько его необходимость оправдывает затраченное на это время.
Разумеется, можно написать алгоритм самому. Но это излишне. Можно воспользоваться уже существующими решениями в этой области.
Например, Google Tink:
Для этой задачи безопаснее всего использовать асимметричное шифрование. Почему? Потому что в приложении реально не нужно расшифровывать пароли обратно.
Таков общий подход. В реальности, когда пользователь вводит пароль, система шифрует его и сравнивает с тем, что лежит в хранилище паролей. Шифрование проходит одним и тем же средством, поэтому можно ожидать, что они совпадут (при вводе правильного пароля ;), разумеется).
Для этого дела подходят BCrypt и SCrypt. Оба являются односторонними функциями (криптографическими хешами) с вычислительно сложными алгоритмами, которые занимают много времени. Это как раз то, что нужно, так как расшифровка в лоб займет целую вечность.
Например, Spring Security поддерживает целый спектр алгоритмов. Можно воспользоваться SCryptPasswordEncoder и BCryptPasswordEncoder.
То, что сейчас является сильным алгоритмом шифрования, в следующем году может быть уже слабым. Вследствие этого делаем вывод, что нужно проверять используемые алгоритмы и обновлять библиотеки с алгоритмами.
Вместо вывода
Сегодня мы поговорили о безопасности и, разумеется, множество вещей осталось за кадром. Я лишь приоткрыл вам дверь в новый мир: мир, который живет своей жизнью.
С безопасностью все так же, как с политикой: если вы не будете заниматься политикой, политика займется вами.
Традиционно предлагаю подписаться на мой гитхаб аккаунт. Я там выкладываю свои наработки по разным технологиям, которые изучаю и применяю на работе.
Полезные ссылки
Да, почти все статьи на почитать написаны на английском. Хотим мы этого или нет, но английский — это язык для коммуникации программистов. Все самые новые статьи, книги, журналы по программированию пишут на английском.
Поэтому и ссылки мои на рекомендации в основном на английском:
⚡️UPDATE⚡️
Друзья, создал телеграм-канал 🤓, в котором освещаю свою писательскую деятельность и свою open-source разработку в целом.
Не хотите пропустить новые статьи? Присоединяйтесь ✌️
 Безопасность включает в себя множество компонентов. Разумеется, чтобы охватить в полной мере и объеме все те защитные принципы и действия, которые известны, нужно написать не одну статью, так что остановимся на самом важном.
Человек, который хорошо разбирается в этой теме, сможет настроить все процессы и проследить, чтобы они не создавали новых дыр в безопасности, будет нужен в любой команде.
Конечно, не стоит думать, что если следовать этим практикам, то приложение будет однозначно безопасно. Нет! Но оно точно будет более безопасным с ними. Поехали.
Безопасность включает в себя множество компонентов. Разумеется, чтобы охватить в полной мере и объеме все те защитные принципы и действия, которые известны, нужно написать не одну статью, так что остановимся на самом важном.
Человек, который хорошо разбирается в этой теме, сможет настроить все процессы и проследить, чтобы они не создавали новых дыр в безопасности, будет нужен в любой команде.
Конечно, не стоит думать, что если следовать этим практикам, то приложение будет однозначно безопасно. Нет! Но оно точно будет более безопасным с ними. Поехали.


 Также, как видно из картинки выше, если в более новой версии есть решение этой уязвимости, Snyk предложит сделать это и создать Pull-Request. Использовать его можно бесплатно для open-source проектов.
Проекты будут сканироваться с какой-то периодичностью: раз в неделю, раз в месяц.
Я зарегистрировался и добавил все свои публичные репозитории в сканирование Snyk (в этом нет ничего опасного: они и так в открытом доступе для всех).
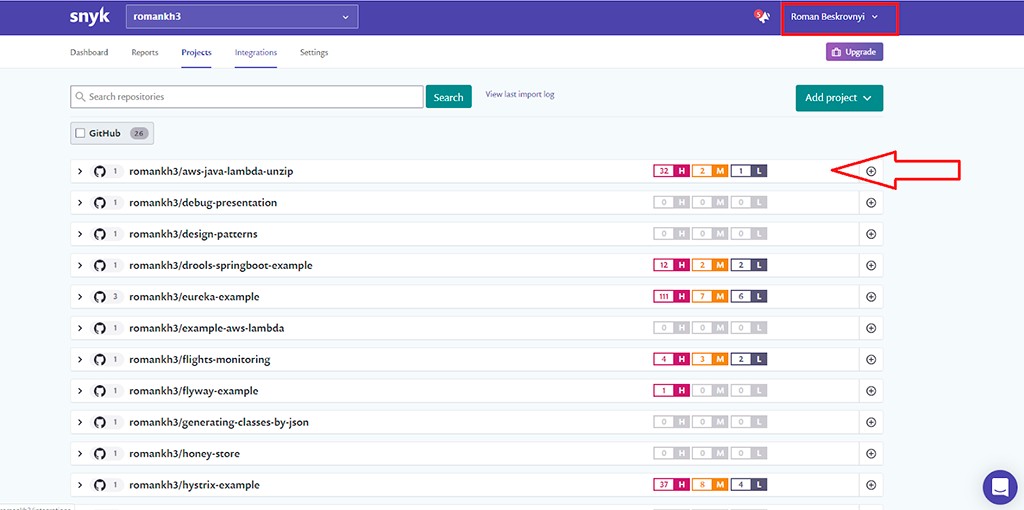
Далее Snyk показал результат сканирования:
Также, как видно из картинки выше, если в более новой версии есть решение этой уязвимости, Snyk предложит сделать это и создать Pull-Request. Использовать его можно бесплатно для open-source проектов.
Проекты будут сканироваться с какой-то периодичностью: раз в неделю, раз в месяц.
Я зарегистрировался и добавил все свои публичные репозитории в сканирование Snyk (в этом нет ничего опасного: они и так в открытом доступе для всех).
Далее Snyk показал результат сканирования:
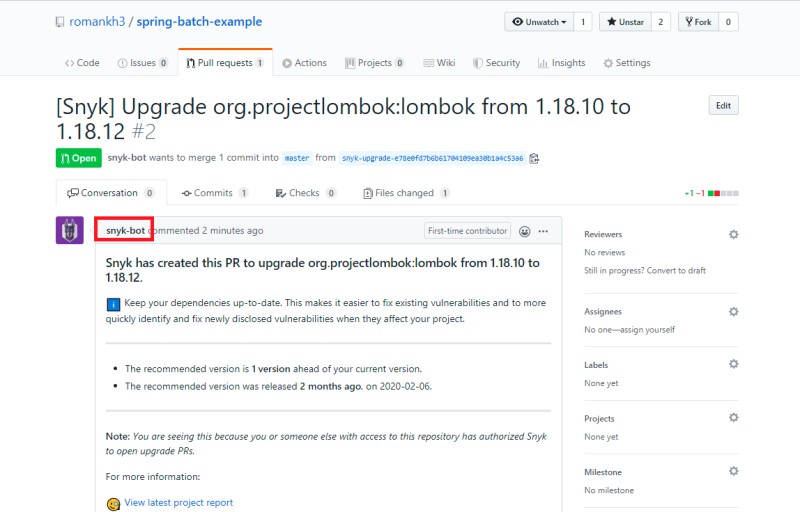
 А через некоторое время, Snyk-bot подготовил несколько Pull-Request’ов в проектах, где нужно обновить зависимости:
А через некоторое время, Snyk-bot подготовил несколько Pull-Request’ов в проектах, где нужно обновить зависимости:
 И вот еще:
И вот еще:
 Так что это отличный инструмент для поиска уязвимостей и мониторинга по обновлению новых версий.
Так что это отличный инструмент для поиска уязвимостей и мониторинга по обновлению новых версий.

 В английской речи чаще встречается словосочетание “sensitive data”. Раскрытие персональных данных, номеров кредитных карт и прочей личной информации клиента может нанести непоправимый вред.
Прежде всего, нужно внимательно посмотреть на дизайн приложения и определить, действительно ли нужны какие-то данные. Возможно, в части из них никакой потребности нет, а добавили их для будущего, которое не наступило и вряд ли наступит. К тому же, во время логирования проекта может произойти утечка таких данных.
Простой способ предотвратить попадание конфиденциальных данных в ваши логи — очистить методы
В английской речи чаще встречается словосочетание “sensitive data”. Раскрытие персональных данных, номеров кредитных карт и прочей личной информации клиента может нанести непоправимый вред.
Прежде всего, нужно внимательно посмотреть на дизайн приложения и определить, действительно ли нужны какие-то данные. Возможно, в части из них никакой потребности нет, а добавили их для будущего, которое не наступило и вряд ли наступит. К тому же, во время логирования проекта может произойти утечка таких данных.
Простой способ предотвратить попадание конфиденциальных данных в ваши логи — очистить методы 
ПЕРЕЙДИТЕ В ПОЛНУЮ ВЕРСИЮ